
在互联网技术普及的时代中,淘宝是连接大众购买力与社会生产力的一座桥梁。随着商品多媒体展示能力的逐渐发展,消费者在线上能够越来越真实地了解、评估感兴趣的商品,越来越自信地购买。近年来,视频形式的互动直播愈加成熟,其对商品展示的全面与真实性,与主播对商品问题实时解答的便捷性,使得消费者越来越多地选择通过观看卖家的直播来了解、选购商品,而商家也愈加重视起直播卖货对真实购物场景的还原能力。这使得购物平台的直播服务,成为了线上大众消费的重要依托。

互联网直播产品中,各类室内外嘈杂环境中的直播里,音频经常混杂各类的噪声,影响用户的听感,干扰多媒体质量。如何利用技术手段,使用户获得“视”为所见、“声”临其境的视听感受,成为了一个重要的任务。在各类方法中,传统音频降噪算法速度较快,计算消耗较低,能在多种多样的低端设备上运行,但面对复杂且多变的突发噪声、各类语言方言的多样人声,传统方法的效果也展现出了可见的短板。

基于学习的、数据驱动的算法,通过对大量数据的学习,在真实的噪声环境中展现出了较为突出的优势,取得了较好的效果。但是这类“基于学习的”方法,由于参数多、模型大,较为复杂,因此可解释性欠佳,稳定性不易受控,泛化能力不易保障,缺陷不易排查。这些问题的存在,导致基于学习的方法常被称为“无法观察”且“不易调整”的“黑箱”。同时,基于学习的算法虽听感效果出众,但相比传统算法,复杂度偏高,运算速度较低、电量消耗较多,更容易导致硬件发热、系统降频、程序卡顿等问题。
为将最好的音频体验带给用户,淘系音视频技术团队在反复的研发、试错、创新中,针对降噪的效果、质量、算法的速度、能耗、延迟与泛化的稳定性等诸多方面,应用了一系列技术,对模型结构、框架、约束等进行了研发改进,以提升并完善淘宝直播整体的音视频体验。
本文接下来的组织结构如下:首先对音频降噪所用到的语音增强技术做了简单介绍,然后依次对基于传统信号处理的语音增强方案和基于深度学习的语音增强方案进行了详细介绍,最后对针对淘宝直播场景自研的Alidenoise算法的关键技术进行了细致阐述,文末附有参考文献列表。
语音增强任务概述
▐ 语音增强的定义
语音增强是指干净语音在现实生活场景中受到来自各种噪声干扰时,需要通过一定的方法将噪声滤除,以提升该段语音的质量和可懂度的技术。从一图中可以直观的带噪后语音的增强后图和带噪语音的频谱图的对比中理解语音增强的过程,左侧为增强后语音的频谱图,右侧为带噪语音的频谱图 [1]。

▐ 语音增强的分类
从通道数角度进行划分
按照录音的通道数来划分,语音增强又分为单通道语音增强和麦克风阵列语音增强。单通道语音增强只利用了时域和频域的信息,而麦克风阵列语音增强不仅利用了时域和频域的信息,还利用了空域的信息。因此单通道语音增强的任务更为困难,但是却对硬件成本要求相对低。另外,麦克风阵列语音增强方法对每个麦克风的物理特性的一致性要求较为苟刻,且对声源的时变空间位置要求较高,即不允许声源的大幅度快速移动。
人耳听觉系统是一个双麦克风结构,人耳能根据不同声源到达左右耳朵的时延差和声强差来感知不同声源的空间位置分布,进而辅助对不同声源的声源分离任务。但是,人耳听觉系统即使在听已经录过音的单通道带噪语音,也能容易地区分该单通道带噪语音中的不同音源;或者当不同声源处在相同位置的时候,人耳也能成功地区分并理解不同的音源。因此,时域和频域信息在音源分离中起主导作用,而空域信息只是起到辅助作用 [2]。
在淘宝直播的业务场景中,主播多以pc、手机等设备开播,是典型的单通道语音增强场景,Alidenoise目前也主要提供单通道的语音增强能力。
按照增强方法进行划分
按照语音增强的方法来分,可以分为无监督语音增强方法和有监督语音增强方法,前者也称为传统语音增强方法,传统语音增强算法虽然不需要离线训练,所需的计算资源也少,但是由于很多不合理的假设的存在,限制了其性能上限。有监督语音增强方法在近些年出现,利用既有的语音数据或噪声数据,训练相关的统计特性模型,类似于人类学习的方式,先让系统学习并记住一些语音和噪声的模式,以此来将噪声从带噪语音中分离出来。由于有监督语音增强方法充分利用了既有的数据,预先掌握了一些语音和噪声的统计特性,因而会得到更优的增强性能。但是在有监督的语音增强方法中,需要重点对其泛化能力进行研究。
基于传统信号处理的单通道语音增强方案
传统单通道语音增强算法主要分为时域方法和频域方法。
▐ 时域方法
参数和滤波的方法
这类方法 [3][4] 主要是利用滤波器估计发音器官的声道参数和激励源的激励参数,但是通常情况下,激励参数是难以估计的,特别是辅音信号的激励实际上是类似于白噪声的随机信号。而在信噪比相对比较低的时候,声道参数和激励参数都难以估计。
信号子空间法
信号子空间法 [5][6] 是基于语音信号具有稀疏特性,把带噪语音信号分解为语音子空间加噪声子空间,进而把噪声子空间的噪声去除,保留语音信号的一种方法。
▐ 频域方法

由于频域语音增强方法是目前常用的增强方法,我们先重点介绍下频域经典算法的基本思想。在频域单通道语音增强算法中,最核心的是如何求取增益函数。上图给出了传统单通道语音增强系统的算法流程图。首先通过短时傅里叶变换将带噪语音由时域信号变换为频域信号,然后计算其功率谱,再进行噪声方差的估计。噪声方差的估计方法一般是先根据语音检测模块来确定当前帧是语音帧还是噪声帧,如果是噪声帧即更新噪声的方差,反之, 则不更新噪声的方差。接下来需要对增益函数进行估计,增益函数的估计有多种方法,目前比较优的方法是先估计语音的存在概率、先验信噪比和后验信噪比,然后把估计的增益函数乘以带噪语音的频域形式即可得到干净语音的频域估计形式,最后经过逆傅里叶变换得到干净语音的时域估计形式,即得到了可测听的波形语音。下面将对一些经典的频域语音增强算法进行介绍。
谱减法
谱减法的核心思想即是在非语音帧的地方迭代更新噪声的方差,然后将噪声的方差从带噪语音信号的能量中减掉从而得到对干净语音信号的估计。谱减法原理简单,但是若噪声方差过估计,就会产生语音失真;而若噪声方差欠估计则会产生音乐噪声。
维纳滤波法
维纳滤波法也是一种经典方法,它分时域和频域滤波两种形式。通过解维纳-霍夫 (Wiener-Hopf) 方程,可获得对滤波系统函数系数的最优估计。和谱减法相比,维纳滤波法增强后的语音几乎没有“音乐噪声”,而是残留类似高斯白噪声的残留噪声,让人听上去更舒服些。但是维纳滤波法明显对语音的破坏更为严重,而且维纳滤波法是平稳条件下的假设模型,其非平稳噪声抑制能力较弱。
基于最小均方误差的语音幅度谱估计方法
传统语音增强算法中具有革命性意义的方法是1984年 Ephraim 和 Malah 提出的基于最小均方误差的语音幅度谱估计算法 [7],随后考虑到人耳对声强的感知是非线性的,因而对数谱域的最小均方误差估计在 [8] 中被提出,至此传统单通道语音增强算法发展渐进成熟,与此同时, Rainer Martin 在1994年提出了基于最小统计量的语音增强方法 [9],2001年他对该方法的噪声估计方法的原理做出了相应的改良,进而提出了更平滑的最小统计量的噪声的估计方法 [10]。而目前该类方法中,用的最普遍的是 Israel Cohen 提出的最小控制的迭代平均的 (Minima Controlled Recursive Averaging, MCRA) 噪声估计方法 [11],随后他又提出了改进的最小控制的迭代平均的噪声估计方法 [12]。最小控制的迭代平均的噪声估计方法相比之前的噪声估计方法而言,具有估计误差更小且对非平稳噪声跟踪更快的特点,可认为该方法是目前为止传统单通道语音增强算法中最优的方法。
▐ 传统单通道语音增强方法的综合评价
优点
传统单通道语音增强方法具有计算量小,可实时在线语音增强的优点。因为它们的噪声是根据当前句中当前帧之前的数据进行迭代更新的,因此可以实现快速语音增强的目的。其次在 Cohen 提出的改进的基于最小均方误差准则的对数功率谱估计方法中 [11][12][13],通过引入语音存在概率,不仅在语音帧对干净语音进行估计,还在非语音帧也对干净语音进行估计,最大程度上避免了语音的失真,使得整体的增强后语音有较好的听感。
缺点
首先是各个传统单通道语音增强方法在不同程度上均存在“音乐噪声” [14],而音乐噪声对人耳的听感影响很大。“音乐噪声”的问题在谱减法中最严重,而基于最小均方误差 (Minimum Mean Squared Error, MMSE) 准则 [15] 的维纳滤波法和幅度谱或对数功率谱估计都可以将残留噪声中的“音乐噪声”变换成听感上更平滑的高斯随机噪声。但是即使是这样,残留噪声在维纳滤波法、幅度谱或对数功率谱估计中都依然存在,且在信噪比 (Signal-to-Noise Ratio, SNR) 比较低的时候更为明显。
其次是语音损伤,这个以维纳滤波法最为严重,而基于最小均方误差准则的对数功率谱估计虽然在很大程度上避免了语音的失真,但是当噪声的能量大于语音的能量时,该类方法基本上无法挽救语音的失真问题,尤其对能量天然较低的辅音来说,这种现象更为明显。
无法对非平稳噪声,特别是极端非平稳噪声形成有效抑制。这是因为在传统的单通道语音增强算法中,噪声是通过当前句子当前帧的邻近信息进行在线估计的,而且只在非语音帧的地方才对噪声的方差进行更新,因此无法对突发性较强的非平稳噪声进行有效跟踪,因而也无法将其从带噪语音信号中去除。
最后,在传统单通道语音增强算法中,存在很多假设,比如对带噪语音信号、干净语音和噪声信号都进行了服从高斯分布的假设;还对噪声和干净语音间的相互作用关系进行了独立性假设,甚至为了推导的方便,对相邻帧或相邻频率维度进行了不相关假设,这些不太合理的假设最终都影响了该类方法的性能上限。
基于深度学习的单通道语音增强方案
在过去几年中,深度学习方法显著提升了许多监督学习任务的性能,如图像分类 [16],手写识别 [17],自动语音识别 [18],语言建模 [19] 和机器翻译 [20] 等,在语音增强任务中,也出现了很多深度学习类的方法。这些方法大致可以分为两类,基于掩码 (mask_based) 的方法和基于映射 (mapping_based) 的方法。
在过去几年中,深度学习方法显著提升了许多监督学习任务的性能,如图像分类[16],手写识别[17],自动语音识别[18],语言建模[19]和机器翻译[20]等,在语音增强任务中,也出现了很多深度学习类的方法。这些方法大致可以分为两类,基于掩码(mask_based)的方法和基于映射(mapping_based)的方法。
▐ Mask_based Methods
Mask_based 的方法,核心思想是通过离线训练 DNN 来预测时频(T-F)mask,并通过将预测的 mask 应用于输入带噪语音的频谱来重构纯净语音信号。比较常用的 mask 包括 IRM [21],PSM [22] 和 cIRM [23]。下图展示了常见 mask 的表现形式 [24]。

▐ Mapping_based Methods
Mapping_based 的方法利用 DNN 来实现从带噪语音频谱的频谱特征到干净语音的频谱特征的映射,比较广泛使用的频谱特征包括幅度频谱、对数功率频谱等。下图展示了一种经典的 mapping_based 方法的训练和测试流程 [1]。

结合信号处理算法和深度学习类方法的Alidenoise语音增强算法
▐ Alidenoise算法核心思想
综合考虑淘宝直播的实时应用场景及传统增强算法和深度学习类增强算法的优缺点,我们设计了一种混合类架构的单通道语音增强算法,巧妙的对 DNN 可有效处理非平稳类噪声的优良特性和传统算法复杂度低的特点进行了融合,算法的核心思想为利用神经网络学习带噪语音中噪声能量和目标人声能量的比值,进而利用传统信号处理中的增益估计器如最小均方误差短时频谱幅度 (MMSE-STSA) 估计器,求得频域上的去噪增益,最后经逆变换得到增强后的时域语音信号,整体处理流程如下图所示。

▐ Alidenoise核心优势
传统信号处理方法与深度学习类方法相结合,兼具可处理非平稳类噪声和算法复杂度低的特点
在神经网络的设计上,结合训练目标,以人声的语谱纹路作为主要学习对象,噪声泛化性强
采用Cache buffer技术,实现流式处理
极轻量小模型, 支持移动端实时增强
降噪延时可调
▐ Alidenoise关键技术一:时频联合域感知技术
算法细节
在基于深度学习方法的语音增强算法中,时序的上下文信息能够有效提升模型的泛化性能 [25]。多层感知器(MLP)模型通常利用连续帧的上下文窗口来捕获上下文信息 [26]。但是,上下文窗口这种信息获取形式无法为MLP 模型提供长期的上下文信息。为了解决这个问题,[25] 中提出了利用带有四层LSTM结构的递归神经网络(RNN)来捕获长期依赖信息。相比MLP模型, LSTM模型表现出了显著的优越性,但是高延迟和高训练复杂性也限制了它的适用性。而 [27] 中提出的TCN模型,则利用残差学习融合空洞多尺度卷积,在近些年中被广泛使用。但在淘宝直播场景中,对人声部分的高音质有着严格的要求,现有的深度学习类增强方案多以频域或时域的特征学习为主,均未考虑语音帧内不同频带的分布差异及时间帧维度语音特性分布的差异,导致增强后的语音部分音质受损,无法大规模应用于线上。基于此,我们在 Alidenoise 算法中引入了时频联合域感知技术,可在几乎不引入额外计算复杂度的同时提升深度学习类语音增强算法的降噪性能,可方便的与常用的CNN、RNN等网络结构结合,获得更为完整的增强后语谱结构,实际评测结果显示,主观听感体验更佳。下图展示了频域的自适应感知(注意力)机制流程。

算法效果
在Taolive Audio Test Datasets上的客观指标评测结果如下表所示,可以看出,所提的TFANet在不同信噪比条件及不同学习目标下均可以明显提升增强后语音的质量和可懂度,综合结论为 PESQ 提升10.3%,STOI 提升4.2%。


▐ Alidenoise关键技术二:分支-转换-聚合的特征提取方式
算法细节
强大的表征能力是神经网络优异的特性之一,在语音增强这个具体任务上,为了使神经网络在语音信号的关键特征提取方面发挥出更大的优势,我们在 Alidenoise 的算法设计中采用了分支-转换-聚合的提取方式,将输入分支分解为 N 个低维表示,然后在每个分支网络中使用尺寸较小的一维因果空洞卷积来进行上下文信息的捕获,最终把各个分支提取到的特征表示进行聚合,这一过程中也引入了注意力机制对不同支路的表征做自适应权重调整,使得可以在较低计算复杂度下获得强大的表征能力,下图给出了算法实现的示意图。

算法效果
这里仍然选用 PESQ 和 STOI 作为评估语音增强后效果的客观指标,在不同信噪比条件下的结果如下表所示,可以看到,在参数量大幅减少的情况下,所提机制仍可以获得最高的客观指标。


▐ Alidenoise关键技术三:轻量化与效能保障
对于运行在移动端上的算法而言,其CPU占用、电量消耗、内存占用与存储占用都会对软件系统的可用性产生明显的影响。一般地,模型的性能消耗与其输出效果,综合来看是一种拮抗取舍的关系。然而,在降噪场景下,算法既需要长时间运行,又需要保证算法效果,这对现有成熟的技术提出了一定的挑战。下文将挑选介绍一些轻量化过程中使用的方案技术,主要包括模型的轻量化裁剪和运算简化与算耗优化方面的内容。经过对模型量级与效果的反复调优,最终取得了满意的效果。
轻量化技术概览
轻量化技术,是指对算法的参数量及模型尺寸、运算量、能耗、速度等“运行成本”进行优化的一系列技术手段。其目的一般是便于智能算法在端上的运行。同时,轻量化技术在计算密集型的云端服务上也有广泛的用途,可以帮助降低服务成本、提升相应速度。
轻量化技术的主要难点在于,在优化运行成本同时,算法的效果与泛化性、稳定性不应受到明显的影响。这对于常见的“黑箱式”神经网络模型来说,在各方面都具有一定的难度。
此外,轻量化的一部分难点也体现在优化目标的差异性上。比如模型尺寸的降低,并不一定会使得运算量降低;模型运算量的降低,也未必能提高运行速度;运行速度的提升也不一定会降低能耗。这种差异性使得轻量化难以“一揽子”地解决所有性能问题,而需要从多种角度、利用多种技术配合,才能达成运行成本的综合降低。
目前学术界与工业界常见的轻量化技术包括:参数/运算量子化、剪枝、小型模块、结构超参优化、蒸馏、低秩、共享等。一个大致的轻量化技术栈可如下图所示。

其中的各类技术都对应不同的目的与需求,比如参数量子化可以压缩模型占用的存储空间,但运算时依然恢复成浮点数;参数+运算全局量子化可以同时降低参数体积,减少芯片运算量,但需要芯片有相应的运算器支持,才能发挥提速效果;知识蒸馏利用小型的学生网络,学习大型模型的高层特征,来获得性能匹配的轻量模型,但优化存在一些难度且主要适合简化表达的任务(比如分类);非结构化的精细剪裁可以将最多的冗余参数剔除,达成优良的精简,但需要专用硬件支持才可以减少运算量;权重共享可显著降低模型尺寸,缺点是难以加速或节能;automl/结构超参搜索能自动确定小型测试结果最优的模型堆叠结构,但搜索空间复杂度与迭代估计的优良度限制了其应用面。团队结合淘宝直播场景软硬件平台特性、稳定性、泛化性、速度与能耗需求的多方面特点,在大量的尝试后使用了对应的技术,达成了符合体验要求的轻量级别。
模型的轻量化剪裁
一般而言,模型剪裁与压缩包括结构化与非结构化两种,我们基于对实际运算效率的需求,主要选择了结构化裁剪路线,根据近期研究成果中对模型结构重要性/参数重要性的均衡,对降噪模型进行了调整剪裁。
一、AutoML与结构超参优化
在计算负担允许的前提下,利用超参搜索方式确定较优的模型尺寸,是一种较为有效且实用的方法。具体的优化算法多种多样,从最简单的网格搜索、连续二分法到 HyperBand、贝叶斯+HyperBand、PBT,都可以对模型初始剪裁的效果提供信息。我们的算法中对子模块、层数、参数量级、学习率、批大小等多种因素都进行了优化搜索,综合来看的确存在一个较为合适的效果-尺寸拐点坡峰,如下所示。整体复杂度指数为5时,取得了最经济的的效果指标。

二、结构化剪裁
结构化剪裁一般指,以卷积核,或整层的粒度,对模型结构进行削减。上述超参优化已经确立了一个较为经济的层+模块堆叠复杂度,接下来进行的结构化剪裁主要针对卷积核/全链接映射数。主流使用的剪裁思想中,常见的有如下几种。
特征图激活前显著性剪裁:基于仿射变换后的特征数值显著性判别,对各层特征进行投票,从而移除相应数量的卷积核,如下左图所示:

特征图激活后显著性剪裁:基于非线性单元(或额外使用了正则化)后的特征显著性,投票移除相应卷积核,如上右图所示。
关于Loss梯度显著性剪裁:基于参数/特征对优化损失计算的导数,结合尺度显著性,共同判断权重/特征的有效度,如下左图所示:

关于输出梯度显著性剪裁:基于参数/特征对输出值梯度的显著性,结合尺度判断其有效性,进行剪裁。如上右图所示。
基于这四种方向的剪裁也衍生出了一系列方法与讨论,比如显著性的L0、L1、L2、方差、最大可预测性、梯度二阶近似积分、差分近似等测度,我们的算法中对其都进行了尝试,纵览对比后将参数量安全降低,算法指标没有显著影响。
运算简化与算耗优化
运算简化与算耗优化主要针对模型中细节的计算流程,设计简化与提速方法,降低运算的时间消耗,降低CPU负载与电量消耗,从而使得模型更加具有部署经济性。
一、低秩与运算分解
模型计算中涉及大量矩阵运算,而一般模型中的过参数假设会使得各中间特征数据的内部具有冗余的相关性,这些相关性一部分通过对模型整体的剪裁去除,一部分通过对无用特征的剪裁去除。剩余的部分在尽可能不降低非线性拟合能力的前提下,难以显式裁剪。此时使用低秩运算来配合特征中剩余的相关性,达成对参数的精简,成为了一个可行的方案。
对音频数据,一个常见的一维卷积运算可示意如下:

进行运算分解后,一种方案可如下所示:

例如,在W=100,Kh=256,Kw=3,F=64的条件下,可节约66%的加法与乘法,削减67%的参数。在我们的算法中,经过对降秩设置的调整,最终节省了参数、达到了提速,而模型效果整体上依然可以保持原水平。
二、短时记忆与延迟优化
在一般的音频算法设置中,为了将算法实时化,常将输入截断为较短的帧序列,分别、单独地输入给模型,如下图所示。
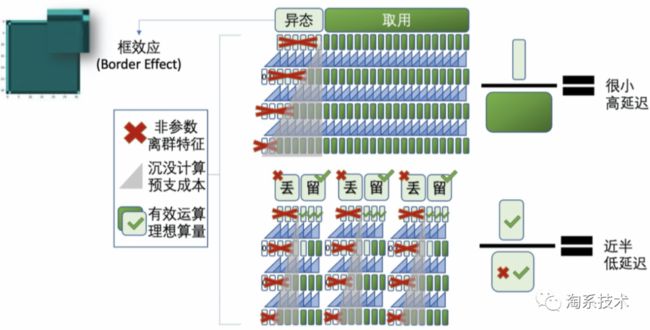
在这种设置下,补边数据会导致一些未完全从音频数据分布计算得来的“异态数据”,从而产生音频框效应,使每帧起始听感受到影响。而加长推演序列尺寸,又会增加延迟。
另一种方法是使用GRU/LSTM等带有记忆参数的模块,但这些模块之外的权重并不具有显著的记忆性,增加GRU/LSTM模块的使用又会显著增加模型尺寸/运算量。另外针对不同延时需要,一般方法常需要训练多个模型实现,加大了用户使用的成本,这也是我们希望统一解决的问题之一。
为了降低框效应、减少运算并增大音频感受野,我们采用了一种逐层短时记忆金字塔的方式来优化运算,如下图所示:
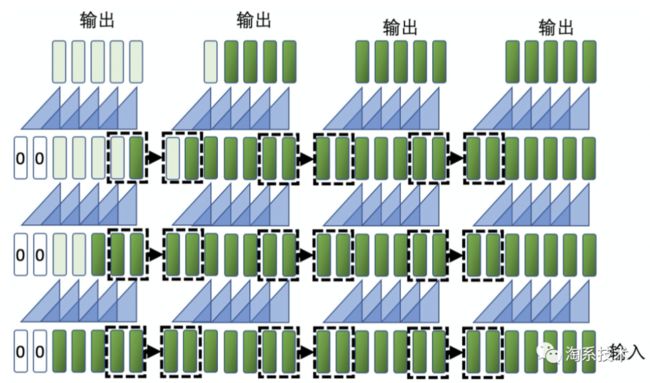
使用此方式,每层特征都可以保存其对应感受野的短时记忆,此短时记忆的时间尺度也可方便地进行计算。该方法可以使得我们的模型能够保存各尺度短时记忆金字塔,在扩大感受野的同时,也消除了框效应。
三、动态自适应能耗
在端上运行时,提高算法运行频率,可以降低音频输出的延迟,反之可以节约能耗防止发热导致的电量降低与过早降频。我们基于一套自动化的调度机制,充分利用模型的弹性帧长,为不同性能的机型提供适配的最优体验。整体算法包括可变初始帧长,与动态帧长调度。
可变初始帧长
调度算法对不同的机型,设置可调可变的初始的分帧帧长。平台硬件条件越高端,则设定帧长越小,相应允许的能耗提高;平台的硬件条件越低端,则设定帧长越大,相应使得能耗降低。
动态帧长调度
我们的实现用,依照下列逻辑对帧长进行调度,其中动态调度模块会根据用户硬件温度、频率、运算耗时、多任务数、电量等实时状况,对帧长进行调整,取得延迟与能耗之间的平衡,确保用户长时间直播的稳定性与算力经济性。

▐ Alidenoise关键技术四:算法质量与平稳性保障
模型的轻量化,一般会在不同程度上,降低拟合能力的上限。在输入数据分布较为集中的情况下,简单的拟合方式被认为会产生最具泛化性的模型估计。然而,在输入数据分布较为复杂稀疏的情况下,轻量化的模型会使得参数空间中可行解的数量受到影响,最终体现为降噪结果的不稳定,具体表现为“降噪减弱”,“人声损伤忽变”,“低频成分降低”,“噪声强度伴随人声音量显著起伏”等。为对此类现象加以规避与改善,我们在轻量化模型上施加了多种技术来保障输出的质量,与降噪的平稳性,主要包括:数据均衡与分布控制、降噪加强与力度控制、人声保护与损伤预防、音质监测与效果评估
数据均衡与分布控制
在实践中,我们发现数据质量与分布,对主客观表现均有影响。未经优化的数据集会导致语音的错误抑制。其中值得注意的现象主要为:
英文人声发音方式,对中文降噪中低沉发音存在影响。
嘈杂程度不足的喧嚣噪声(babblenoise),对语音数据存在对抗影响。
噪声多样性欠缺,对尖锐突发噪声抑制存在影响。
为了均衡语音中不同类型发音的分布,我们对语音数据以及噪声种类都进行了分析调整,适配的大致的结果如下:

降噪加强与力度控制
一、利用AutoVAD进行降噪加强
为了提升小模型的降噪能力上限,降低噪声抑制的参数学习量,我们设计了一种模拟VAD的机制来降低噪声段抑制难度,从而减轻模型的学习负担。该设计将隔层特征的统计量作为输入,计算时间轴上的抑制系数,对不含人声的部分提升抑制能力,该设计如下图所示:
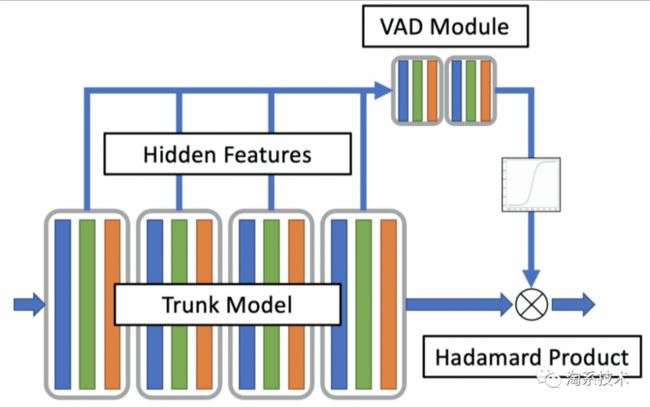
经过对无监督VAD模块的限值激活(Sigmoid),形成一个值域(0-1)的时间向量,与降噪后的数据相乘过滤。
二、降噪力度控制
在通过数据与结构改进提升模型整体降噪学习能力后,在不同场景需求下,对降噪力度的需要也有差异。一般而言,不同降噪强度需要通过不同约束的模型来达成,但这样会增加体验的不一致性与不稳定性,同时加重用户下载/存储等负担。为此,我们设计了两种方便可调的降噪力度控制方法,可以在不改变模型的前提下,调整模型降噪的性能曲线,从而达成不同等级降噪的控制。
多项式修正控制
该方法中,我们根据声音保留的目标信噪比,设置了一个多项式形式的修正函数,通过一个参数 µ 控制多项式扭曲的程度,以定向的、平缓地控制一定范围内的声音保留。
极值差频谱修正
娱乐场景中,降噪程度的需求一般会低于会议场景,在其中平缓过渡的过程中,可以基于帧内+帧间语音存在可能性的差异,对语音保留进行控制。该方法检测每帧各频段的信噪比情况,判断人声频段附近的最高信噪比,是否达到人声存在的可能性阈值,若此时人声频率附近的信噪比平均估计过低,则依据帧间动量平滑,降低此帧的抑制程度。
人声保护与损伤预防
在一般的基于学习的降噪算法中,优化的目标一般为损伤平均值,客观评估的指标也大都基于各时间子序列上损伤的均值。这在使用中会暴露一些实用问题,一种具体的表现即为:虽然降噪的平均能力较为优异,但实际上降噪能力忽强忽弱、人声突然减弱或消失,会对用户的使用体检产生骤发的、短时的、但较为明显且严重的影响。
我们提出了一些方法来解决应对此类问题,保障降噪后声音的质量。
Distortion Aware Loss
我们提出了一种 Distortion-Aware-Loss 对信号进行保护的机制。该机制利用一个平衡参数 alpha 来控制对语音信号的保护程度。其核心思想是“当语音出现损伤时,其产生的损失值会被放大;当语音没有损伤时,其产生的loss会被略微缩小”。
当使用“目标值减估计值”作为损伤差值时,随着alpha参数的变化,该方法对损失数值的差异化调整曲线如下:

分频保护约束
在研究中我们发现,随着降噪程度的提高,低频人声部分的音量降低越来越明显,这导致原本沉厚的语音,在变得清晰的同时,因尖锐化而显得单薄,对原声的还原度下降。为此,我们设计了一种分频约束的机制,基于上述对人声的保护约束,对不同频段的信号,施加不同的学习任务。基本的逻辑如下:
对低频设置较高的保护值,使得低频“宁存噪,不损声”。
对高频设置较高的降噪值,使得高频“主降噪”。
高低频之间,施加平缓的任务过渡。该约束对Loss影响的图示如下:
上图是施加前后的损失频谱图,横坐标为时间,纵坐标为频率。其中,带有红/绿色的位置,表示此处的目标值与估计值有差距,产生了Loss。红色点位表示此处产生的Loss,是由于人声过渡削弱导致,属于人声损伤Loss。
绿色点位表示产生的是降噪不足的Loss。可见,经过分频平缓约束,低频部分的人声损伤Loss被放大。而高频部分的降噪Loss占主导。该方法的应用,使得低频部分得到了更好的保留。
时域专注约束
解决了一部分人声损伤与频带均衡后,我们发现在一些情况下,噪声会随着人声的提高而透出,跟随人声变化,形成一种类似混响回音的不良效果。为改善此问题,我们提出了一种针对性的约束,其核心思路为:
人声部分降噪不足,是模型监督不良的体现。
提出假设:纯噪声的抑制,属于较为简单的任务。
提出假设:人声音量较大时进行降噪,属于中等难度的任务。
提出假设:人声音量较小时进行降噪,属于难度较大的任务。
针对“人声能量较大”或“信噪比较大”的时间部分,加强约束学习,符合由易到难的优化顺序。
以此思想设置的约束可描述为:“人声能量较大”或“信噪比较大”时,Loss加权高;两者较低时,Loss加权低。
同时,我们对人声能量、噪声能量、信号能量比等多种专注向量进行选取整合(乘积、加和、最大值),之后对专注向量进行归一化,与Loss相乘进行优化。在使用了上述各项保护策略之后,算法客观指标有效提升,而降噪波动性指数降低,人声音量与字词都得到了良好的保护。
音质监测与效果评估
为了在上述整个研究过程中,追踪主观客观的算法表现情况,我们设置了多种角度的评估策略,其中包含:
客观评估:
中文+各类噪声客观评测标准
英文+各类噪声客观评测标准
语音泛化性、噪声泛化性、以及收敛程度测试数据集
主观评估:
基于ITU相关标准设置的众包语音降噪质量主观评测、综合主观评测标准
综合工况主观评估标准
难样本主观测试数据集
等一系列评估标准,用以适配算法研发过程中不同阶段的需求。在实践中,我们发现随着效果的逐步改进,综合的主观评测对算法效果的评估越来越重要,对改善算法在各异环境中的表现有非常重要的指导作用。
▐ Alidenoise关键技术小结
“声”动设计理念:为保证人声部分的高品质,综合考虑语音帧内不同频带的分布差异及时间帧维度语音特性分布的差异,提出了时频联合域感知技术。
高效特征提取:采用了分支-转换-聚合的提取方式,将输入分解为多分支低维表示,进行上下文信息的捕获,最后通过引入注意力机制对不同支路的表征做自适应权重调整,使得可以在较低计算复杂度下获得更强的降噪能力。
极致能耗优化:采用了包括超参优化、结构化剪裁、低秩运算、短时记忆与动态能耗在内的算耗节简手段,为各类终端设备全方位提供优享体验。
稳定质量保障:在数据均衡的基础上,使用无监督VAD配合降噪力度控制来调整降噪强度,提出了一系列声音保护约束提升平稳性与音质,并使用主客观的音质监测评估方法对算法质量进行跟踪。
总结与展望
为淘宝直播的广大用户提供“视”为所见、“声”临其境的视听感受,一直以来都是淘系音视频技术团队追求的目标。
借助音频降噪、检测、声效特效、娱乐玩法、内容挖掘、语音辅助、通用轻量化等技术与场景的探索实用,我们将在未来的技术开拓中,持续优化音质画质,通过主观质量优化来进一步提升直播间画质,通过智能PLC技术来恢复网络丢包,通过场景检测来识别当前的直播环境,并据此来选择最佳的语音降噪模式和降噪强度;我们还会研发声音美化功能,给男主播更磁性的声线,给女主播更清澈的嗓音;在声音互动方面,我们还会支持直播连麦的变声功能,有效保护特定人群隐私。我们还会同达摩院一起,在直播间引入智能语音TTS、ASR能力,提供语音播报、语音消息、实时字幕能力,更好的服务主播和用户。
创新技术驱动的服务升级,将为亿万淘宝用户带来焕然一新的购物体验。如果您有兴趣,欢迎加入我们,一起为智能服务的基础设施添砖加瓦!
参考文献:
[1] Xu Y, Du J, Dai L R, et al. A regression approach to speech enhancement based on deep neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 23(1): 7-19.
[2] Rouat J. Computational auditory scene analysis: Principles, algorithms, and applications (wang, d. and brown, gj, eds.; 2006)[book review][J]. IEEE Transactions on Neural Networks, 2008, 19(1): 199-199.
[3] Gannot S, Burshtein D, Weinstein E. Iterative and sequential Kalman filter-based speech enhancement algorithms[J]. IEEE Transactions on speech and audio processing, 1998, 6(4): 373-385.
[4] Kim J B, Lee K Y, Lee C W. On the applications of the interacting multiple model algorithm for enhancing noisy speech[J]. IEEE transactions on speech and audio processing, 2000, 8(3): 349-352.
[5] Ephraim Y, Van Trees H L. A signal subspace approach for speech enhancement[J]. IEEE Transactions on speech and audio processing, 1995, 3(4): 251-266.
[6] Ephraim Y, Van Trees H L. A signal subspace approach for speech enhancement[J]. IEEE Transactions on speech and audio processing, 1995, 3(4): 251-266.
[7] Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. IEEE Transactions on acoustics, speech, and signal processing, 1984, 32(6): 1109-1121.
[8] Ephraim Y, Malah D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator[J]. IEEE transactions on acoustics, speech, and signal processing, 1985, 33(2): 443-445.
[9] Martin R. Spectral subtraction based on minimum statistics[J]. power, 1994, 6(8).
[10] Martin R. Noise power spectral density estimation based on optimal smoothing and minimum statistics[J]. IEEE Transactions on speech and audio processing, 2001, 9(5): 504-512.
[11] Cohen I, Berdugo B. Speech enhancement for non-stationary noise environments[J]. Signal processing, 2001, 81(11): 2403-2418.
[12] Cohen I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging[J]. IEEE Transactions on speech and audio processing, 2003, 11(5): 466-475.
[13] Cohen I, Gannot S. Spectral enhancement methods[M]//Springer Handbook of Speech Processing. Springer, Berlin, Heidelberg, 2008: 873-902.
[14] Esch T, Vary P. Efficient musical noise suppression for speech enhancement system[C]//2009 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2009: 4409-4412.
[15] Scharf L L. Statistical signal processing[M]. Reading, MA: Addison-Wesley, 1991.
[16] Ciregan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification[C]//2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012: 3642-3649.
[17] Graves A, Liwicki M, Fernández S, et al. A novel connectionist system for unconstrained handwriting recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2008, 31(5): 855-868.
[18] Senior A, Vanhoucke V, Nguyen P, et al. Deep neural networks for acoustic modeling in speech recognition[J]. IEEE Signal processing magazine, 2012.
[19] Sundermeyer M, Ney H, Schlüter R. From feedforward to recurrent LSTM neural networks for language modeling[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(3): 517-529.
[20] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Advances in neural information processing systems. 2014: 3104-3112.
[21] Wang Y, Narayanan A, Wang D L. On training targets for supervised speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2014, 22(12): 1849-1858.
[22] Erdogan H, Hershey J R, Watanabe S, et al. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks[C]//2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015: 708-712.
[23] Williamson D S, Wang Y, Wang D L. Complex ratio masking for monaural speech separation[J]. IEEE/ACM transactions on audio, speech, and language processing, 2015, 24(3): 483-492.
[24] Wang D L, Chen J. Supervised speech separation based on deep learning: An overview[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(10): 1702-1726.
[25] Chen J, Wang D L. Long short-term memory for speaker generalization in supervised speech separation[J]. The Journal of the Acoustical Society of America, 2017, 141(6): 4705-4714.
[26] Xu Y, Du J, Huang Z, et al. Multi-objective learning and mask-based post-processing for deep neural network based speech enhancement[J]. arXiv preprint arXiv:1703.07172, 2017.
[27] Bai S, Kolter J Z, Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[J]. arXiv preprint arXiv:1803.01271, 2018.




