KubeEdge和Kuiper“双剑合并”,轻松解决边缘流式数据处理
摘要:KubeEdge 是一个开源的边缘计算平台,它在Kubernetes原生的容器编排和调度能力之上,扩展实现了 云边协同、计算下沉、海量边缘设备管理、边缘自治等能力。KubeEdge还将通过插件的形式支持5G MEC、AI云边协同等场景,目前在很多领域都已落地应用。
在边缘的流失处理产品Kuiper
Kuiper是从2019年初开始做的,在2019年10月份,发布了第一个版本,一直持续迭代到现在,它的整个架构是一个比较经典的流式处理架构。
产品设计目标:在云端运行的流式处理,像Spark与Flink可以运行在边缘端
Kuiper架构图

整体架构可分为3部分,左侧为sources,代表数据来源的位置,数据来源可能是KubeEdge里面有个边缘端的MQTT macOS broker,也可能是文件、窗口、数据库;
右侧为Sinks,代表数据处理完成后所要存储的位置,也就是目标系统,目标可以是MQTT,可以将其存到文件、数据库里面,也可以调用HTTP service;
中间部分分成了这几层,最上层为数据业务逻辑处理,这个层面提供了SQL statement、Rule Parser,SQL processors进行处理后并将其转化成SQL plan;下面层为Streaming runtime和SQL runtime, 运行最终执行出来的 plan;最底层为storage,用来存储有些消息流出。
Kuiper使用场景
流式处理:实现在边缘端的实时流式处理
规则引擎:灵活定义规则引擎,实现告警和消息转发
数据格式与协议转换:实现边缘与云端不同类型的数据格式与异构协议之间灵活转换,实现IT&OT融合
KubeEdge与Kuiper集成

部分架构图
Kuiper是装在 KubeEdge MQTT Broker后面,整个都运行在边缘端,底下为不同的Mapper,也就是接入各种各样不同的协议。边缘MQTT Broker用来交换消息。
数据处理的类型:
从设备模型文件定义中获取类型定义
将数据转换为Kuiper的数据类型
创建流时,可使用schema-less流定义
支持的数据类型有int、string、bool、float
KubeEdge模型文件和配置
下图为部分配置文件,包括设备的名称、属性、name、data type、Description等。

部分配置文件
保存设备模型文件
在ect/mqtt_source.yaml中配置模型文件信息
- KubeEdgeVersion:目前未使用,为适配将来不同的版本模型文件预留
- KubeEdgeModelFile:模型文件路径
通过config-map下发配置,保存到相关目录下
Kuiper使用过程
1)定义流:类似余数据库中表格的定义
DATASOURCE=”$hw/events/device/+/twin/update”为KubeEdge里定义好的topic

2)定义并提交规则

用SQL实现业务逻辑,并将运行结果发送到指定目标
支持的SQL
SELECT/FROM/WHERE/ORDER
JOIN/GROUP/HAVING
4类时间窗口+1个计数窗口
60+SQL函数
3)运行
KubeEdge中部署Kuiper规则
1)运用Kuiper-Kubernetes-tool
2)该程序为一个工具类,单独运行在容器中,执行通过config-map下发的命令配置文件
配置文件中用于指定kuiper服务所在的地址和端口等信息
命令文件所在的目录
3)通过config-map下发命令执行文件,该工具定期自动扫描文件,然后执行命令
Kuiper manager-云边协同管理控制台
另外一种方式是通过管理控制台来管理很多Kuiper节点,因为Kuiper可以运行在很多节点上。
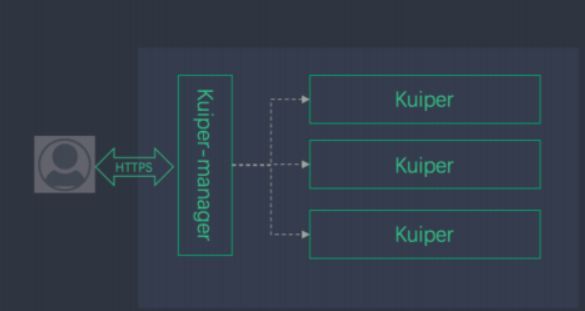
比如Kuiper可以运行在车联网的盒子里面,车联网有很多车,可以通过Kuiper-manager把所有的实例都接入进来,统一对其进行规则更新。
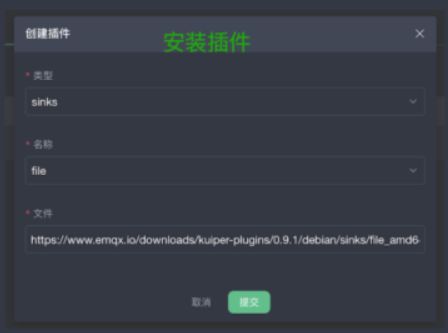
第一步是安装插件,我们提供了一些插件的知识,比如要接入不同的源,如果我们这边的源不支持,则可以自己写个插件,将插件进行安装,安装上去之后我们提供安卓插件界面,就可以使用了。
接下来为创建流定义

下图为数据存储的位置,下图所示为将数据保存到文件系统,进行路径的指定。

下图为可视化的编辑界面,可以进行规则的编写。

应用案例:国家工业互联网大数据中心

该案例是一个非常典型的使用场景。K8s+CloudCore部署在云端,将规则通过管理通道下放到Kuiper,Kuiper的位置是放在MQTT broker,会将数据定义,实现数据的清洗。目前通道有两条,第一条是将处理完的消息发往Cloud MQTT broker,第二条通道比如本地要做数据持久化,可将其存到Influxdb这个持续数据库,我们在边缘发生的一些第三方应用可以直接去调Influxdb里面的数据,做一些展示可视化等。底层是通过Mapper把不同的数据给接上来。
Kuiper里规则引擎的使用场景
LF EdgeX Foundry内置规则引擎,于2020年4月Geneva版本中已经正式发布。

应用案例:异构系统对接数据格式转换
实现与ERP、MES等IT系统数据交换,我们提供了一个非常灵活的扩展能力,包括异构数据通过扩展插件采集后,可以利用SQL内置函数或者扩展函数进行快速、灵活处理;第二点是拿到数据处理结果后,通过sink的数据模板可以对分析结果进行转换,灵活适配各类目标系统所需的数据格式和协议,比如同样一条温度大于30度的规则,如果要去发送控制设备的指令,并且要发到微信上。这两个不同的目标系统,它所需要的接口和数据是不一样的,但对于这个规则是一样的,那么可以在 data里面,根据同一条规则触发两个不同的操作,你可以指定不同的 topic,数据即可发送,不需再进行复杂的编程;第三点是利用SAP NetWeaver RFC SDK,实现从SAP中读取数据,处理并转换后发送到别的异构系统。
性能数据
Kuiper 支持并发运行数千条规则
8000规则*0.1消息/秒/规则,共计的TPS为800条/秒
规则定义
源:MQTT
SQL:select temperature from source where temperature>20(90%数据被过滤)
目标:日志
配置
AWS:2core*4GB
Ubuntu
资源使用
Memory:89%~72%;0.4MB/rule
GPU:25%
AWS t2.micro 配置10k+/s消息吞吐

点击关注,第一时间了解华为云新鲜技术~