本文原题“程序员应如何理解高并发中的协程”,转载请联系作者。
1、系列文章引言
1.1 文章目的
作为即时通讯技术的开发者来说,高性能、高并发相关的技术概念早就了然与胸,什么线程池、零拷贝、多路复用、事件驱动、epoll等等名词信手拈来,又或许你对具有这些技术特征的技术框架比如:Java的Netty、Php的workman、Go的gnet等熟练掌握。但真正到了面视或者技术实践过程中遇到无法释怀的疑惑时,方知自已所掌握的不过是皮毛。
返璞归真、回归本质,这些技术特征背后的底层原理到底是什么?如何能通俗易懂、毫不费力真正透彻理解这些技术背后的原理,正是《从根上理解高性能、高并发》系列文章所要分享的。
1.2 文章源起
我整理了相当多有关IM、消息推送等即时通讯技术相关的资源和文章,从最开始的开源IM框架MobileIMSDK,到网络编程经典巨著《TCP/IP详解》的在线版本,再到IM开发纲领性文章《新手入门一篇就够:从零开发移动端IM》,以及网络编程由浅到深的《网络编程懒人入门》、《脑残式网络编程入门》、《高性能网络编程》、《不为人知的网络编程》系列文章。
越往知识的深处走,越觉得对即时通讯技术了解的太少。于是后来,为了让开发者门更好地从基础电信技术的角度理解网络(尤其移动网络)特性,我跨专业收集整理了《IM开发者的零基础通信技术入门》系列高阶文章。这系列文章已然是普通即时通讯开发者的网络通信技术知识边界,加上之前这些网络编程资料,解决网络通信方面的知识盲点基本够用了。
对于即时通讯IM这种系统的开发来说,网络通信知识确实非常重要,但回归到技术本质,实现网络通信本身的这些技术特征:包括上面提到的线程池、零拷贝、多路复用、事件驱动等等,它们的本质是什么?底层原理又是怎样?这就是整理本系列文章的目的,希望对你有用。
1.3 文章目录
《 从根上理解高性能、高并发(一):深入计算机底层,理解线程与线程池》
《 从根上理解高性能、高并发(二):深入操作系统,理解I/O与零拷贝技术》
《 从根上理解高性能、高并发(三):深入操作系统,彻底理解I/O多路复用》
《 从根上理解高性能、高并发(四):深入操作系统,彻底理解同步与异步》
《 从根上理解高性能、高并发(五):深入操作系统,理解高并发中的协程》(* 本文)
《从根上理解高性能、高并发(六):高并发高性能服务器到底是如何实现的 (稍后发布..)》
1.4 本篇概述
接上篇《深入操作系统,彻底理解同步与异步》,本篇是高性能、高并发系列的第5篇文章。
协程是高性能高并发编程中不可或缺的技术,包括即时通讯(IM系统)在内的互联网产品应用产品中应用广泛,比如号称支撑微信海量用户的后台框架就是基于协程打造的(详见《开源libco库:单机千万连接、支撑微信8亿用户的后台框架基石》)。而且越来越多的现代编程语言都将协程视为最重要的语言技术特征,已知的包括:Go、Python、Kotlin等。
因此了解和掌握协程技术对于很多程序员(尤其海量网络通信应用的后端程序员)来说是相当有必要的,本文正是为你解惑协程技术原理而写。
本文已同步发布于“即时通讯技术圈”公众号,欢迎关注。公众号上的链接是:点此进入。
2、本文作者
应作者要求,不提供真名,也不提供个人照片。
本文作者主要技术方向为互联网后端、高并发高性能服务器、检索引擎技术,网名是“码农的荒岛求生”,公众号“码农的荒岛求生”。感谢作者的无私分享。
3、正文引言
作为程序员,想必你多多少少听过协程这个词,这项技术近年来越来越多的出现在程序员的视野当中,尤其高性能高并发领域。当你的同学、同事提到协程时如果你的大脑一片空白,对其毫无概念。。。

那么这篇文章正是为你量身打造的。
话不多说,今天的主题就是作为程序员,你应该如何彻底理解协程。
4、普通的函数
我们先来看一个普通的函数,这个函数非常简单:
def func():
print("a")
print("b")
print("c")
这是一个简单的普通函数,当我们调用这个函数时会发生什么?
- 1)调用func;
- 2)func开始执行,直到return;
- 3)func执行完成,返回函数A。
是不是很简单,函数func执行直到返回,并打印出:
a
b
c
So easy,有没有,有没有!

很好!
注意这段代码是用python写的,但本篇关于协程的讨论适用于任何一门语言,因为协程并不是某种语言特有的。而我们只不过恰好使用了python来用作示例,因其足够简单。
那么协程是什么呢?
5、从普通函数到协程
接下来,我们就要从普通函数过渡到协程了。和普通函数只有一个返回点不同,协程可以有多个返回点。
这是什么意思呢?
void func() {
print("a")
暂停并返回
print("b")
暂停并返回
print("c")
}
普通函数下,只有当执行完print("c")这句话后函数才会返回,但是在协程下当执行完print("a")后func就会因“暂停并返回”这段代码返回到调用函数。
有的同学可能会一脸懵逼,这有什么神奇的吗?
我写一个return也能返回,就像这样:
void func() {
print("a")
return
print("b")
暂停并返回
print("c")
}
直接写一个return语句确实也能返回,但这样写的话return后面的代码都不会被执行到了。
协程之所以神奇就神奇在当我们从协程返回后还能继续调用该协程,并且是从该协程的上一个返回点后继续执行。
就好比孙悟空说一声“定”,函数就被暂停了:
void func() {
print("a")
定
print("b")
定
print("c")
}
这时我们就可以返回到调用函数,当调用函数什么时候想起该协程后可以再次调用该协程,该协程会从上一个返回点继续执行。
Amazing,有没有,集中注意力,千万不要翻车。

只不过孙大圣使用的口诀“定”字,在编程语言中一般叫做yield(其它语言中可能会有不同的实现,但本质都是一样的)。
需要注意的是:当普通函数返回后,进程的地址空间中不会再保存该函数运行时的任何信息,而协程返回后,函数的运行时信息是需要保存下来的。
接下来,我们就用实际的代码看一看协程。
6、“Talk is cheap,show me the code”
下面我们使用一个真实的例子来讲解,语言采用python,不熟悉的同学不用担心,这里不会有理解上的门槛。
在python语言中,这个“定”字同样使用关键词yield。
这样我们的func函数就变成了:
void func() {
print("a")
yield
print("b")
yield
print("c")
}
注意:这时我们的func就不再是简简单单的函数了,而是升级成为了协程,那么我们该怎么使用呢?
很简单:
def A():
co =func() # 得到该协程
next(co) # 调用协程
print("in function A") # do something
next(co) # 再次调用该协程
我们看到虽然func函数没有return语句,也就是说虽然没有返回任何值,但是我们依然可以写co = func()这样的代码,意思是说co就是我们拿到的协程了。
接下来我们调用该协程,使用next(co),运行函数A看看执行到第3行的结果是什么:
a
显然,和我们的预期一样,协程func在print("a")后因执行yield而暂停并返回函数A。
接下来是第4行,这个毫无疑问,A函数在做一些自己的事情,因此会打印:
a
in function A
接下来是重点的一行,当执行第5行再次调用协程时该打印什么呢?
如果func是普通函数,那么会执行func的第一行代码,也就是打印a。
但func不是普通函数,而是协程,我们之前说过,协程会在上一个返回点继续运行,因此这里应该执行的是func函数第一个yield之后的代码,也就是 _print("b")_。
a
in function A
b
看到了吧,协程是一个很神奇的函数,它会自己记住之前的执行状态,当再次调用时会从上一次的返回点继续执行。
7、图形化解释
为了让你更加彻底的理解协程,我们使用图形化的方式再看一遍。
首先是普通的函数调用:

在该图中:方框内表示该函数的指令序列,如果该函数不调用任何其它函数,那么应该从上到下依次执行,但函数中可以调用其它函数,因此其执行并不是简单的从上到下,箭头线表示执行流的方向。
从上图中我们可以看到:我们首先来到funcA函数,执行一段时间后发现调用了另一个函数funcB,这时控制转移到该函数,执行完成后回到main函数的调用点继续执行。这是普通的函数调用。
接下来是协程:

在这里:我们依然首先在funcA函数中执行,运行一段时间后调用协程,协程开始执行,直到第一个挂起点,此后就像普通函数一样返回funcA函数,funcA函数执行一些代码后再次调用该协程。
注意:协程这时就和普通函数不一样了,协程并不是从第一条指令开始执行而是从上一次的挂起点开始执行,执行一段时间后遇到第二个挂起点,这时协程再次像普通函数一样返回funcA函数,funcA函数执行一段时间后整个程序结束。
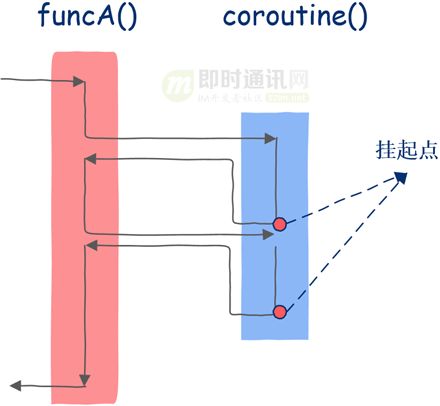
8、函数只是协程的一种特例
怎么样,神奇不神奇。和普通函数不同的是,协程能知道自己上一次执行到了哪里。
现在你应该明白了吧,协程会在函数被暂停运行时保存函数的运行状态,并可以从保存的状态中恢复并继续运行。
很熟悉的味道有没有,这不就是操作系统对线程的调度嘛(见《深入计算机底层,理解线程与线程池》),线程也可以被暂停,操作系统保存线程运行状态然后去调度其它线程,此后该线程再次被分配CPU时还可以继续运行,就像没有被暂停过一样。
只不过线程的调度是操作系统实现的,这些对程序员都不可见,而协程是在用户态实现的,对程序员可见。
这就是为什么有的人说可以把协程理解为用户态线程的原因。
此处应该有掌声。

也就是说现在程序员可以扮演操作系统的角色了,你可以自己控制协程在什么时候运行,什么时候暂停,也就是说协程的调度权在你自己手上。
在协程这件事儿上,调度你说了算。
当你在协程中写下 yield 的时候就是想要暂停该协程,当使用 _next()_ 时就是要再次运行该协程。
现在你应该理解为什么说函数只是协程的一种特例了吧,函数其实只是没有挂起点的协程而已。
9、协程的历史
有的同学可能认为协程是一种比较新的技术,然而其实协程这种概念早在1958年就已经提出来了,要知道这时线程的概念都还没有提出来。
到了1972年,终于有编程语言实现了这个概念,这两门编程语言就是Simula 67 以及Scheme。

但协程这个概念始终没有流行起来,甚至在1993年还有人考古一样专门写论文挖出协程这种古老的技术。
因为这一时期还没有线程,如果你想在操作系统写出并发程序那么你将不得不使用类似协程这样的技术,后来线程开始出现,操作系统终于开始原生支持程序的并发执行,就这样,协程逐渐淡出了程序员的视线。
直到近些年,随着互联网的发展,尤其是移动互联网时代的到来,服务端对高并发的要求越来越高,协程再一次重回技术主流,各大编程语言都已经支持或计划开始支持协程。
那么协程到底是如何实现的呢?
10、协程到底是如何实现的?
让我们从问题的本质出发来思考这个问题:协程的本质是什么呢?
其实就是可以被暂停以及可以被恢复运行的函数。那么可以被暂停以及可以被恢复意味着什么呢?
看过篮球比赛的同学想必都知道(没看过的也能知道),篮球比赛也是可以被随时暂停的,暂停时大家需要记住球在哪一方,各自的站位是什么,等到比赛继续的时候大家回到各自的位置,裁判哨子一响比赛继续,就像比赛没有被暂停过一样。

看到问题的关键了吗:比赛之所以可以被暂停也可以继续是因为比赛状态被记录下来了(站位、球在哪一方),这里的状态就是计算机科学中常说的上下文(context)。
回到协程。
协程之所以可以被暂停也可以继续,那么一定要记录下被暂停时的状态,也就是上下文,当继续运行的时候要恢复其上下文(状态)另外:函数运行时所有的状态信息都位于函数运行时栈中。
函数运行时栈就是我们需要保存的状态,也就是所谓的上下文。
如图所示:

从上图中我们可以看出:该进程中只有一个线程,栈区中有四个栈帧,main函数调用A函数,A函数调用B函数,B函数调用C函数,当C函数在运行时整个进程的状态就如图所示。
现在:我们已经知道了函数的运行时状态就保存在栈区的栈帧中,接下来重点来了哦。
既然函数的运行时状态保存在栈区的栈帧中,那么如果我们想暂停协程的运行就必须保存整个栈帧的数据,那么我们该将整个栈帧中的数据保存在哪里呢?
想一想这个问题:整个进程的内存区中哪一块是专门用来长时间(进程生命周期)存储数据的?是不是大脑又一片空白了?

先别空白!
很显然:这就是堆区啊(heap),我们可以将栈帧保存在堆区中,那么我们该怎么在堆区中保存数据呢?希望你还没有晕,在堆区中开辟空间就是我们常用的C语言中的malloc或者C++中的new。
我们需要做的就是:在堆区中申请一段空间,让后把协程的整个栈区保存下,当需要恢复协程的运行时再从堆区中copy出来恢复函数运行时状态。
再仔细想一想,为什么我们要这么麻烦的来回copy数据呢?
实际上:我们需要做的是直接把协程的运行需要的栈帧空间直接开辟在堆区中,这样都不用来回copy数据了,如下图所示。
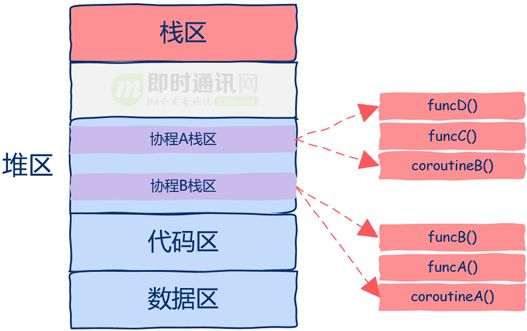
从上图中我们可以看到:该程序中开启了两个协程,这两个协程的栈区都是在堆上分配的,这样我们就可以随时中断或者恢复协程的执行了。
有的同学可能会问,那么进程地址空间最上层的栈区现在的作用是什么呢?
答案是:这一区域依然是用来保存函数栈帧的,只不过这些函数并不是运行在协程而是普通线程中的。
现在你应该看到了吧,在上图中实际上共有3个执行流:
- 1)一个普通线程;
- 2)两个协程。
虽然有3个执行流但我们创建了几个线程呢?
答案是:一个线程。
现在你应该明白为什么要使用协程了吧:使用协程理论上我们可以开启无数并发执行流,只要堆区空间足够,同时还没有创建线程的开销,所有协程的调度、切换都发生在用户态,这就是为什么协程也被称作用户态线程的原因所在。
掌声在哪里?

因此:即使你创建了N多协程,但在操作系统看来依然只有一个线程,也就是说协程对操作系统来说是不可见的。
这也许是为什么协程这个概念比线程提出的要早的原因,可能是写普通应用的程序员比写操作系统的程序员最先遇到需要多个并行流的需求,那时可能都还没有操作系统的概念,或者操作系统没有并行这种需求,所以非操作系统程序员只能自己动手实现执行流,也就是协程。
现在你应该对协程有一个清晰的认知了吧。

11、协程技术概念小结
正文内容用了较多调侃语气,目的是希望能轻松诙谐地助你理解协程技术概念。那么,我们从严肃专业知识来小结一下,到底什么是协程呢?
11.1 协程是比线程更小的执行单元
协程是比线程更小的一种执行单元,你可以认为是轻量级的线程。
之所以说轻:其中一方面的原因是协程所持有的栈比线程要小很多,java当中会为每个线程分配1M左右的栈空间,而协程可能只有几十或者几百K,栈主要用来保存函数参数、局部变量和返回地址等信息。
我们知道:而线程的调度是在操作系统中进行的,而协程调度则是在用户空间进行的,是开发人员通过调用系统底层的执行上下文相关api来完成的。有些语言,比如nodejs、go在语言层面支持了协程,而有些语言,比如C,需要使用第三方库才可以拥有协程的能力(比如微信开源的Libco库就是这样的,见:《开源libco库:单机千万连接、支撑微信8亿用户的后台框架基石》)。
由于线程是操作系统的最小执行单元,因此也可以得出,协程是基于线程实现的,协程的创建、切换、销毁都是在某个线程中来进行的。
使用协程是因为线程的切换成本比较高,而协程在这方面很有优势。
11.2 协程的切换到底为什么很廉价?
关于这个问题,我们回顾一下线程切换的过程:
- 1)线程在进行切换的时候,需要将CPU中的寄存器的信息存储起来,然后读入另外一个线程的数据,这个会花费一些时间;
- 2)CPU的高速缓存中的数据,也可能失效,需要重新加载;
- 3)线程的切换会涉及到用户模式到内核模式的切换,据说每次模式切换都需要执行上千条指令,很耗时。
实际上协程的切换之所以快的原因我认为主要是:
- 1)在切换的时候,寄存器需要保存和加载的数据量比较小;
- 2)高速缓存可以有效利用;
- 3)没有用户模式到内核模式的切换操作;
- 4)更有效率的调度,因为协程是非抢占式的,前一个协程执行完毕或者堵塞,才会让出CPU,而线程则一般使用了时间片的算法,会进行很多没有必要的切换(为了尽量让用户感知不到某个线程卡)。
12、写在最后
写到这里,相信你已经理解协程到底是怎么一回事了,关于协程更系统的知识可以自行查阅相关资料,我就不再啰嗦了。
下一篇《从根上理解高性能、高并发(六):高并发高性能服务器到底是如何实现的》,敬请期待!
附录:更多高性能、高并发文章精选
《 高性能网络编程(一):单台服务器并发TCP连接数到底可以有多少》
《 高性能网络编程(二):上一个10年,著名的C10K并发连接问题》
《 高性能网络编程(三):下一个10年,是时候考虑C10M并发问题了》
《 高性能网络编程(四):从C10K到C10M高性能网络应用的理论探索》
《 高性能网络编程(五):一文读懂高性能网络编程中的I/O模型》
《 高性能网络编程(六):一文读懂高性能网络编程中的线程模型》
《 高性能网络编程(七):到底什么是高并发?一文即懂!》
《 以网游服务端的网络接入层设计为例,理解实时通信的技术挑战》
《 知乎技术分享:知乎千万级并发的高性能长连接网关技术实践》
《 淘宝技术分享:手淘亿级移动端接入层网关的技术演进之路》
《 一套海量在线用户的移动端IM架构设计实践分享(含详细图文)》
《 一套原创分布式即时通讯(IM)系统理论架构方案》
《 微信后台基于时间序的海量数据冷热分级架构设计实践》
《 微信技术总监谈架构:微信之道——大道至简(演讲全文)》
《 如何解读《微信技术总监谈架构:微信之道——大道至简》》
《 快速裂变:见证微信强大后台架构从0到1的演进历程(一)》
《 17年的实践:腾讯海量产品的技术方法论》
《 腾讯资深架构师干货总结:一文读懂大型分布式系统设计的方方面面》
《 以微博类应用场景为例,总结海量社交系统的架构设计步骤》
《 新手入门:零基础理解大型分布式架构的演进历史、技术原理、最佳实践》
《 从新手到架构师,一篇就够:从100到1000万高并发的架构演进之路》
本文已同步发布于“即时通讯技术圈”公众号。
▲ 本文在公众号上的链接是:点此进入。同步发布链接是:http://www.52im.net/thread-3306-1-1.html