机器学习实战sklearn_随机森林参数选择
有了之前的经验,能够对数据使用随机森林进行分析,接下来就来选择随机森林的最优参数
步骤:
1、数据预处理、特征选择
2、调节参数
3、训练
4、参数微调
1、数据载入与处理
import pandas as pd
features = pd.read_csv('data/temps_extended.csv')
# One Hot
features = pd.get_dummies(features)
# 标签与数据
labels = features['actual']
features = features.drop('actual', axis = 1)
feature_list = list(features.columns)
# 格式转换
import numpy as np
features = np.array(features)
labels = np.array(labels)
from sklearn.model_selection import train_test_split
# 数据集切分
train_features, test_features, train_labels, test_labels = train_test_split(features, labels,
test_size = 0.25, random_state = 42)2、选择6个最重要的特征
# 最重要的几组
important_feature_names = ['temp_1', 'average', 'ws_1', 'temp_2', 'friend', 'year']
# Find the columns of the most important features
important_indices = [feature_list.index(feature) for feature in important_feature_names]
# 训练和测试数据集
important_train_features = train_features[:, important_indices]
important_test_features = test_features[:, important_indices]
train_features = important_train_features[:]
test_features = important_test_features[:]
3、调节参数
调节前参数:
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(random_state = 42)
from pprint import pprint
print('Parameters currently in use:\n')
pprint(rf.get_params())
寻找最优参数,使用RandomizedSearchCV网格化寻找最优参数:
from sklearn.model_selection import RandomizedSearchCV
# 参数配置
# 随机森林中树的个数
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
# 每一节点考虑切分的节点数
max_features = ['auto', 'sqrt']
# 最大深度
max_depth = [int(x) for x in np.linspace(10, 100, num = 10)]
max_depth.append(None)
# 切分一个节点最小数量
min_samples_split = [2, 5, 10]
# 每一叶子节点最小数量
min_samples_leaf = [1, 2, 4]
# Method of selecting samples for training each tree
bootstrap = [True, False]
# Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
# 模型构建
# 模型创建
rf = RandomForestRegressor()
# Random search of parameters, using 3 fold cross validation,
# search across 100 different combinations, and use all available cores
rf_random = RandomizedSearchCV(estimator=rf, param_distributions=random_grid,
n_iter = 100, scoring='neg_mean_absolute_error',
cv = 3, verbose=2, random_state=42, n_jobs=-1)
# 训练
rf_random.fit(train_features, train_labels)
寻找的结果:

4、评估
predictions = model.predict(test_features)
errors = abs(predictions - test_labels)
mape = 100 * np.mean(errors / test_labels)
accuracy = 100 - mape
print('Model Performance')
print('Average Error: {:0.4f} degrees.'.format(np.mean(errors)))
print('Accuracy = {:0.2f}%.'.format(accuracy))
best_random = rf_random.best_estimator_
evaluate(best_random, test_features, test_labels)结果:
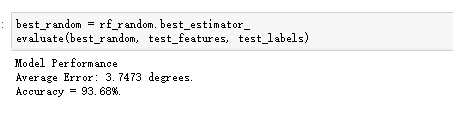
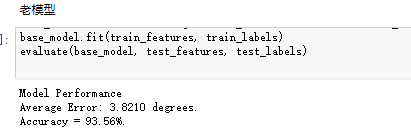
而老模型的结果:
5、 微调参数:
参数微调1:
# 依据上述结果微调参数
param_grid = {
'bootstrap': [True],
'max_depth': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [100, 200, 300, 1000]
}
# 模型
rf = RandomForestRegressor()
# Instantiate the grid search model
grid_search = GridSearchCV(estimator = rf, param_grid = param_grid,
scoring = 'neg_mean_absolute_error', cv = 3,
n_jobs = -1, verbose = 2)
# 训练
grid_search.fit(train_features, train_labels)训练后的参数:

评估:
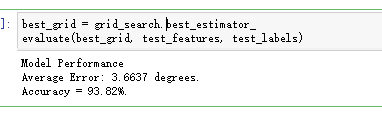
参数微调2:
param_grid = {
'bootstrap': [True],
'max_depth': [110, 120, None],
'max_features': [3, 4],
'min_samples_leaf': [5, 6, 7],
'min_samples_split': [10],
'n_estimators': [75, 100, 125]
}
rf = RandomForestRegressor()
grid_search_ad = GridSearchCV(estimator = rf, param_grid = param_grid,
scoring = 'neg_mean_absolute_error', cv = 3,
n_jobs = -1, verbose = 2)
grid_search_ad.fit(train_features, train_labels)参数结果与准确率:
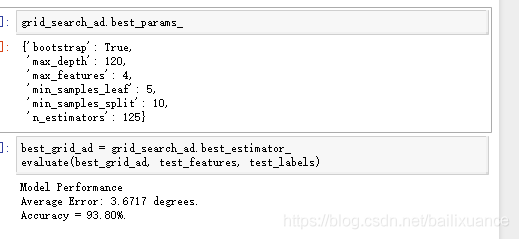
6、综上,我们可以得到我们训练最优结果是第一次微调:
print('Model Parameters:\n')
pprint(best_grid.get_params())
print('\n')
evaluate(best_grid, test_features, test_labels)Model Parameters:
{'bootstrap': True,
'criterion': 'mse',
'max_depth': 100,
'max_features': 3,
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_impurity_split': None,
'min_samples_leaf': 5,
'min_samples_split': 12,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 300,
'n_jobs': 1,
'oob_score': False,
'random_state': None,
'verbose': 0,
'warm_start': False}
Model Performance
Average Error: 3.6637 degrees.
Accuracy = 93.82%.