vSphere 集群HA插槽策略配置指导
背景
最近,生产环境vsphere中某群集主机17台,虚拟机达到520台,虚比例达到:34:1;按照经验值,虚比例应控制在10-15,最大不超过15-20之间;vsphere HA报故障容量告警;咨询虚拟化厂商,应对措施多采用配置HA 插槽数来优化。

HA 工作原理
当在群集启用HA时,系统会自动选举一台ESXi主机作为首选主机(也称为Master主机),其余的ESXi主机作为从属主机(也称为Slave主机)。Master主机与vCenter Server进行通信,并监控所有受保护的从属主机(也称为Slave主机)的状态。Master主机使用管理网络和数据存储检测信号来确定故障的类型。当不同类型的ESXi主机故障时,Master主机检测并相应地处理故障,让虚拟机重新启动。当Master主机本身出现故障时,Slave主机会重新选举产生Master主机。
Master/Slave主机的选举是存储最多的ESXi主机,如果ESXi主机的存储相同时,会使用MOID(Managed Objective ID,数值大的为Master,)来进行选举。当Master主机产生后,会通告给其他Slave主机。当选举产生的Master主机故障时,会重新选举产生新的Master主机;
注意:vCenter Server正常情况下只和Master主机通信;Slave主机监视本地运行的虚拟机状态,推送给Master主机;Master主机发送心跳信息给Slave主机,Slave主机监控Master主机的健康状态,Master主机故障时,Slave主机将参与与Master主机的选举。
A》 主机与网络隔离:与管理网全不通,slave只能通过共享存储通知master自己存活,而这种被标记为:隔离
一个或多个slave丢失了所有的管理网络连接,这样的slave既不能联系到master也不能联系到其他ESXi hosts。这种情况下,slave主机通过存储网络来通知master,它已经是隔离状态。
我们知道HA使用管理网络及存储设备进行通信监测状态,如果Master主机不能通过管理网络与Slave主机通信,那么会通过存储来确认ESXi主机是否存活,这样的机制可以让HA判断主机是否处于网络隔离状态。在这种情况下,Slave主机通过heartbeat datastores来通知Master主机它已经是隔离状态,具体上这个Slave是通过一个特殊的二进制文件–host-Xpoweron,来通知Master主机能够采取适当的措施来确保保护虚拟机。Master主机看到这个标志后,就知道Slave主机已经是隔离状态,然后Master主机通过HA锁定其他文件(datastores上的其他文件),当Slave主机看到这些文件已经被锁定,就知道Master主机正在重新启动虚拟机,然后Slave主机可以执行配置过的隔离响应动作(如关机或者关闭电源)
B》主机与网络分区:联系到管理网的其他主机
一个或多个slave通过管理网络联系不到master,这样的slave虽不能联系到master但能联系到其他ESXi hosts,这种情况下,vSphere HA能够了使用存储网络来检测分离的主机是否存活以及否要保护它们里面的虚拟机。
HA插槽控制
VMware HA 插槽计算是由 vCenter HA 服务完成,可向涉及的各个代理提供整个群集的容量。vSphere HA 使用准入控制确保在主机出现故障时预留足够的资源用于虚拟机恢复。
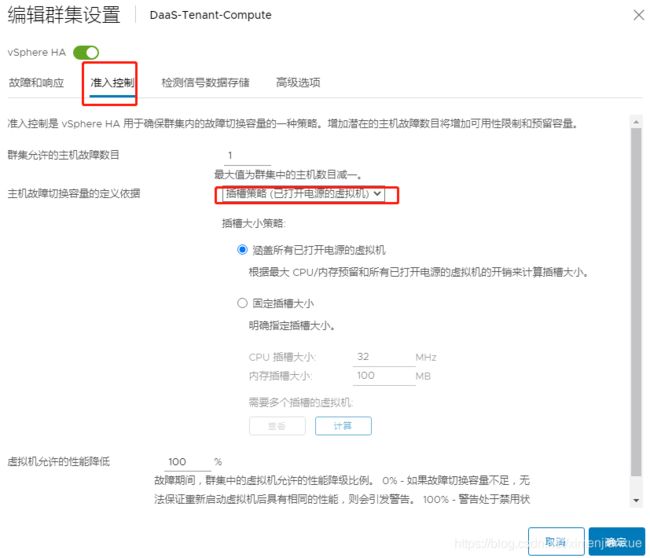
准入控制对资源使用施加一些限制,vSphere HA 准入控制的基础是群集允许的且仍能保证可故障切换的主机故障数,有三种方式来设置主机故障切换容量:a)群集资源百分比; b) 插槽策略; c)专用故障切换主机.
插槽是内存和 CPU 资源的逻辑表示。默认情况下,会调整插槽的大小来满足群集中任何已打开电源虚拟机的要求。
在 VirtualCenter 2.x 中,具有最大资源消耗的虚拟机将选为插槽计算的基础。 如果只有一个虚拟机消耗的资源较大而其他虚拟机消耗的资源较小,则会产生问题。
在 vCenter Server 4.0 中,插槽大小显示在群集的“摘要”选项卡上的 vSphere Client 中。
在 vCenter Server 4.1 和 5.x 中,可单击高级运行时信息以在群集的“摘要”选项卡中显示插槽大小信息。
VMware HA 可根据主机的 CPU 和内存容量确定每个 ESX/ESXi 主机中可用的插槽数。然后,还可以确定群集中可以出现故障的 ESX/ESXi 主机的数量,其中插槽的数量不少于已打开电源的计算机的数量。 如果虚拟机没有预留,例如,当预留为 0 时,4.x 版本的 RAM 默认值为 0,CPU 速度为 256 MHz;5.x 版本的 CPU 速度为 32MHz。
注意:在 ESXi 5.5 中,默认 CPU 速度为 32 MHz,内存为0MB+内存开销。
通常在vCenter大喊“资源不足”之前,slots决定了有多少虚拟机可以开启,一个slot代表一个虚拟机,接入控制不会限制HA重新启动虚拟机,它确保有足够的资源提供给虚拟机启动从而防止过度承诺。HA为群集内开启的虚拟机预留最高的CPU和内存,如果预留不超过32MHz,HA会使用默认的32MHz的CPU,请注意,这种行为已经改变:在vSphere 5.0之前的版本默认是256MHz,这个值被改变是因为有些人认为256MHz太激进,如果没有设置内存预留,HA会默认使用0MB+内存开销。
预留必须小心,如果没必要以每个虚拟机为单位,不用对其配置,尤其当使用群集主机故障容忍,如果预留是必须的,最好以资源池为单位。预留决定了插槽大小。
插槽计算
插槽大小由两个组件(CPU 和内存)组成,插槽是基于虚拟机级别的,计算插槽前要考虑几个因素:
1)确定群集内每台主机可以拥有的插槽数目。
2)确定群集的当前故障切换容量。保证群集内主机发生故障并仍然有足够插槽满足所有已打开电源虚拟机的主机的数目。
3) 确定“当前故障切换容量”是否小于“配置的故障切换容量”,如果是,则准入控制不允许执行此以下操作:
. a)打开虚拟机电源; b) 迁移虚拟机 c)增加虚拟机的 CPU 或内存预留
1、vSphere HA 计算 CPU 组件的方法:
是先获取每台已打开电源虚拟机的 CPU 预留,然后再选择最大值。如果没有为虚拟机指定 CPU 预留,则系统会为其分配一个默认值 32 MHz。可以用 das.vmcpuminmhz 高级选项更改此值。
2、 vSphere HA 计算内存组件的方法:
先获取每台已打开电源虚拟机的内存预留和内存开销,然后再**选择最大值。**内存预留没有默认值。如果群集内虚拟机的预留值大小不一致,则会影响插槽大小的计算。为避免出现这种情况,可以使用das.slotcpuinmhz或das.slotmeminmb高级选项分别指定插槽大小的 CPU 或内存组件的上限。也可以通过查看需要多个插槽的虚拟机数来确定群集中资源碎片的风险。
可以从vSphere Web Client中 vSphere HA设置的准入控制部分对此进行计算。如果已使用高级选项指定了固定插槽大小或最大插槽大小,则虚拟机可能需要多个插槽。使用插槽数目计算当前故障切换容量,计算出插槽大小后,vSphere
HA 会确定每台主机中可用于虚拟机的 CPU 和内存资源。这些值包含在主机的根资源池中,而不是主机的总物理资源中。如果群集中的所有主机均相同,则可以用群集级别指数除以主机的数量来获取此数据。不包括用于虚拟化目的的资源。只有处于连接状态、未进入维护模式且没有任何 vSphere HA错误的主机才列入计算范畴。
就按下图示例来讲:

1). 插槽大小由每个虚拟机的CPU和内存决定,取CPU和内存的需求最大值,通过上图虚拟机可以得知:插槽大小为2GHz CPU和2GB内存。
2). HA计算CPU组件的方法是先获取每台已打开电源虚拟机的CPU预留,如果没有为虚拟机指定CPU预留,则系统会为其分配一个默认值32MHz。
3). HA计算内存组件的方法是先获取每台已打开电源虚拟机的内存预留,如果没有为虚拟机指定内存预留,则系统会为其分配一个默认值(无默认值,用户自定义)。
4). 插槽计算:用主机的CPU资源数除以插槽大小的CPU组件,然后将结果化整。对主机内存资源数进行同样的计算。然后,比较这两个数字,较小的那个数字即为主机可以支持的插槽数。
示例2:
假设某 群集含三台主机,每台主机上可用的 CPU 和内存资源数各不相同。第一台主机 (H1) 的可用 CPU 资源和可用内存分别为 9 GHz 和 9 GB,第二台主机 (H2) 为 9 GHz 和 6 GB,而第三台主机 (H3) 则为 6 GHz 和 6 GB。群集内有5个已打开电源的虚拟机,其 CPU 和内存要求各不相同。
VM1 所需的 CPU 资源和内存分别为 2 GHz 和 1 GB,VM2为 2 GHz 和 1 GB,VM3 为 1 GHz 和 2GB,VM4 为 1 GHz 和 1 GB,VM5 则为 1GHz 和 1 GB。
“群集允许的主机故障数目”设置为 1。
<1> 通过以上环境可知:群集插槽大小为: 2 GHz,2G
最大 CPU 要求(由 VM1 和 VM2 共享)为 2 GHz,而最大内存要求(针对 VM3)为 2 GB。综合,插槽大小为 2 GHz CPU 和 2 GB 内存。
由此可确定每台主机可以支持的最大插槽数目如下:
H1 可以支持四个插槽:9/2=4.5,取整为4;
H2 可以支持三个插槽(取 9GHz/2GHz 和 6GB/2GB 中较小的一个):3
H3 也可以支持三个插槽:6/2=3
<2>计算出当前故障切换容量:
由上计算可知,最大容量的主机是 H1,如果它发生故障,群集内还有六个插槽,足够供所有5个已打开电源的虚拟机使用。如果 H1 和 H2 都发生故障,群集内将仅剩下三个插槽,这是不够用的。因此,当前故障切换容量为 1。按最大故障计算,群集内可用插槽的数目为 1(H2 和 H3 上的六个插槽减去五个已使用的插槽)。
vSphere HA 的接入控制策略选择
选择接入控制策略时,应当基于可用性需求和群集的特性选择 vSphere HA 接入控制策略。

1) 选择什么样的接入控制策略?
生产环境比较常见的是选择按**静态主机数量(允许几台主机故障)**定义故障切换容量、预留一定百分比的群集资源来定义故障切换容量这两种策略。
选择前者的话,如果群集中某一台虚拟机所需的CPU或内存资源较大(3,3),而其他虚拟机所需的CPU或内存资源比较平均,会影响到ESXi主机支持的插槽数量计算。
因此,如果群集中虚拟机所需的CPU和内存资源差距较大,推荐使用使用预留一定百分比的群集资源来定义故障切换容量策略。
2) 避免资源碎片
“群集资源的百分比”策略不解决资源碎片问题。
通过将插槽定义为虚拟机最大预留值,“群集允许的主机故障数目”策略的默认配置可避免资源碎片。
使用“指定故障切换主机”策略不会出现资源碎片,因为该策略会为故障切换预留主机。
3) 故障切换资源预留的灵活性
为故障切换保护预留群集资源时,接入控制策略所提供的控制粒度会有所不同。“群集允许的主机故障数目”策略允许设置多个主机作为故障切换级别。“群集资源的百分比”策略最多允许指定 100% 的群集 CPU 或内存资源用于故障切换。通过“指定故障切换主机”策略可以指定一组故障切换主机。
4) 群集的异构性
从虚拟机资源预留和主机总资源容量方面而言,群集可以异构。在异构群集内,“群集允许的主机故障数目”策略可能过于保守,因为在定义插槽大小时它仅考虑最大虚拟机预留,而在计算当前故障切换容量时也假设最大主机发生故障。其他两个接入控制策略不受群集异构性影响。
附录:补充HA的几个概念:
1)启用虚拟机组件保护(VMCP):vSphere HA可以检测到数据存储可访问性故障,并为受影响的虚拟机提供自动恢复。当发生数据存储可访问性故障时,受影响的主机无法再访问特定数据存储的存储路径,可确定vSphere HA将对此类故障作出的响应,从创建事件警报到虚拟机在其他主机上重新启动。
2)PDL(permanent device loss 永久设备丢失):是在存储设备报告主机无法再访问数据存储时发生的不可恢复的可访问性丢失,如果不关闭虚拟机的电源,此状况将无法恢复。
3)APD(All-Paths-Down 全部路径异常):暂时性或未知的可访问性丢失,或I/O处理中的任何其他未识别的延迟,此类型的可访问性问题是可恢复的。
a). 关闭虚拟机电源再重新启动虚拟机(保守):
受影响的Vms会被关闭电源,然后在连接正常的ESXi主机上重启。如果故障主机无法与Master主机通讯则将无法激活
b). 关闭虚拟机电源再重新启动虚拟机(积极):
受影响的vms会被关闭电源,无论是否有主机可以通过重启承载这些vms。不论Master主机是否存在,是否能和其它主机通讯以及是否有足够的资源
4) 虚拟机监控敏感度:
A) 故障时间间隔(30S):如果在30S的时间间隔内未收到主机与虚拟机间的检测信号,vSphere HA会重新启动虚拟机。
B) 最短正常运行时间(120S):发现故障后,不会立即重启虚拟机,先进行120S的和存储I/O的信息监测,以免故障误判。das.iostatsinterval可配置
C) 每个虚拟机的最大重置次数(3次)
为了避免因非瞬态错误而反复重置虚拟机,默认情况下,在某个可配置的时间间隔内将对虚拟机仅重置三次,在对虚拟机执行过三次重置后,指定的时间结束之前,vSphere HA 不会在后续故障出现后进一步尝试重置虚拟机,可以使用每个虚拟机的最大重置次数自定义设置来配置重置次数。
D) 最大重置时间段(1小时)
- 群集资源百分比控制策略
示例:

上示例图中,全部群集资源时24GHz(CPU)和96GB (MEM),这导致了下面的计算公式
((24 GHz - (2 GHz + 1 GHz + 32 MHz + 4 GHz)) / 24 GHz) = 69 % available //集群可用的cpu容量
((96 GB - (1,1 GB + 114 MB + 626 MB + 3,2 GB)/96 GB= 85 % available
如果是一个不平衡的群集(主机由不同大小的CPU和内存资源),预留资源百分比应该等于或者大于主机提供的最大资源百分比,这样做是为了确保在发生故障时,虚拟机所在的主机有足够的资源让其重新启动。
在vSphere 4.0中引入了基于百分比的接入控制策略,基于百分比的接入控制是基于每预留计算,从而代替插槽计算.基于百分比的接入控制策略比“主机故障”更保守,比“故障切换主机”更灵活。
建议使用按百分比的基本接入控制策略,因为它是最灵活的。至于这个比例,因一旦指定了预留百分比,该百分比的资源将不提供给虚拟机使用,因此设置一个百分比等于一个单一或者多个主机的资源时就更合理。
示例2:

对于上图中示例集群,以每个主机为粒度,每主机对集群的高效率为1/8,即每个主机贡献的资源为12.5%,使用了20%的预留资源在8个主机的群集中将大于单台主机贡献率,HA的主要目标是提供物理服务器故障后虚拟机的自动恢复,它是建议预留单个或者多个主机资源相等的资源,由于预留资源百分比必须是个整数,所以保守的比例是13%,这样就近似等于单台主机了。
如下图所示,添加主机到群集:

如图中所示,继续使用之前配置的13%的接入控制策略,这样将导致故障转移能力相当于1.5个主机,每个主机拥有8核2GHz主频的CPU,70GB的内存,群集最初设置的接入控制策略为13%,相当于109.2GB内存和24.96GHz的CPU,如果要允许一个主机发生故障,7.68GHz和33.6GB将被浪费,如果定义故障主机为N+2,那么预留比例建议为:2/N*100%