2020年美国新冠肺炎疫情数据分析
US_2019COVID
介绍
2020年美国新冠肺炎疫情数据分析–截止2020年9月9日
- 数据处理
- 使用Spark对数据进行分析
- 数据可视化
一、数据处理
1. 数据集分析
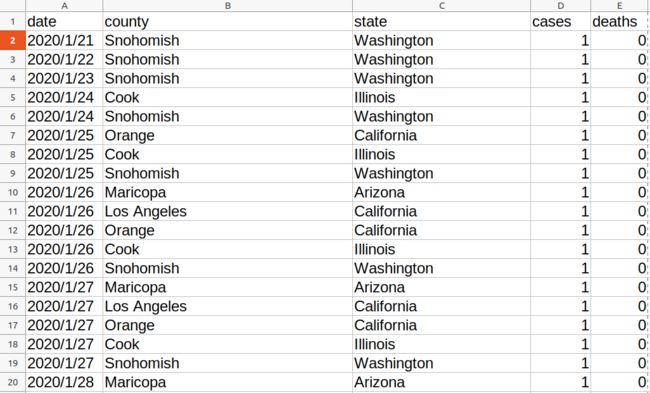
数据包含以下字段,具体含义:
date 日期; county 区县; state 州; cases 截止该日期确诊人数; deaths 截止该日期死亡人数
将csv文件转为txt文件,方便spark读取生成RDD和DataFrame。
转换代码见 csv_txt.py
2. 上传文件到HDFS文件系统
hdfs dfs -mkdir /tmp
hdfs dfs -put us-counties.txt /tmp
二、使用Spark对数据进行分析
这里使用spark SQL对数据进行分析,因数据集是txt文件,需要从RDD转换得到DataFrame。
从RDD转换得到DataFrame有两种方法,因不知道数据结构,使用第二种编程方式定义RDD模式。
#生成表头
fields=[StructField("date",DateType(),False),
StructField("county",StringType(),False),
StructField("state",StringType(),False),
StructField("cases",IntegerType(),False),
StructField("deaths",IntegerType(),False)]
schema=StructType(fields)
#生成表中记录
rdd0=spark.sparkContext.textFile("/tmp/us-counties.txt")
rdd1=rdd0.map(lambda x:x.split("\t")).map(lambda p:Row(toDate(p[0]),p[1],p[2],int(p[3]),int(p[4])))
#拼接
schemaUsCovid=spark.createDataFrame(rdd1,schema)
#注册临时表
schemaUsCovid.createOrReplaceTempView("usInfo")
其中主要统计了一下8个指标,分别是:
- 计算每日累计确诊病例数和死亡数
- 计算每日较昨日新增确诊病例数和死亡数
- 统计截止9月9日 美国各州累计确诊人数和死亡人数 病死率=死亡率/确诊率
- 统计截止9月9日 美国确诊最多的10个州
- 统计截止9月9日 美国国死亡最多的10个州
- 统计截止9月9日 美国确诊最少的10个州
- 统计截止9月9日 美国死亡最少的10个州
- 统计截止9月9日全美和各州病死率
将结果存储在本地文件系统中。
hdfs dfs -get /tmp/us/result1.json ./result/result1
剩下result文件类似。
完整代码见 dataAnalyst.py
三、数据可视化
使用python第三方库pyecharts作为可视化工具
具体代码见 show.py
具体截图如下:
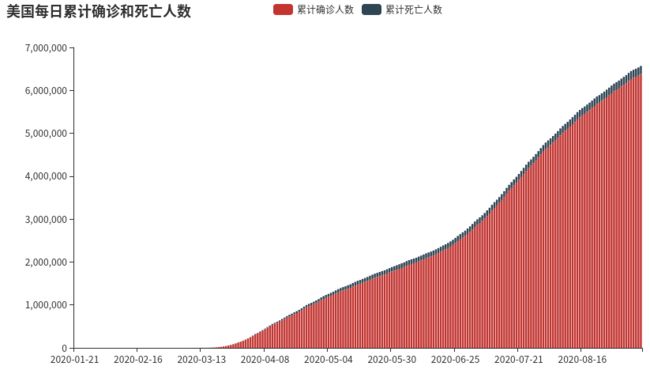
1.计算每日累计确诊病例数和死亡数
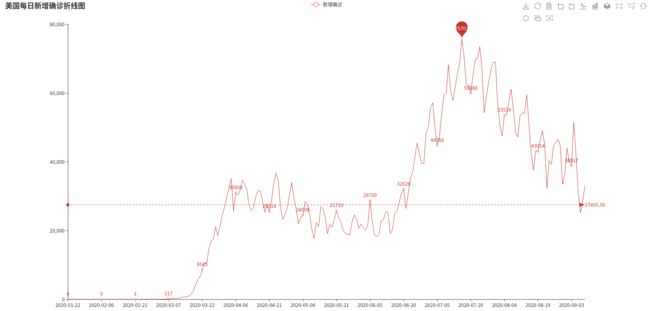
2.计算每日较昨日新增确诊病例数
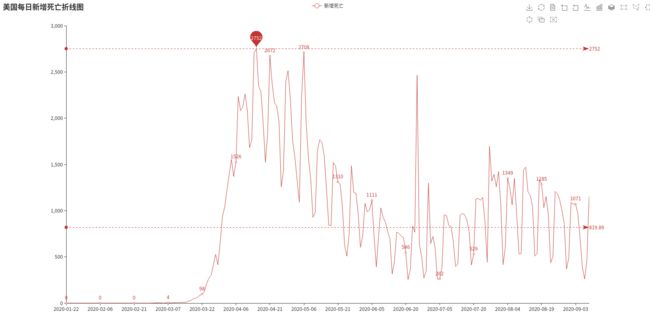
死亡数
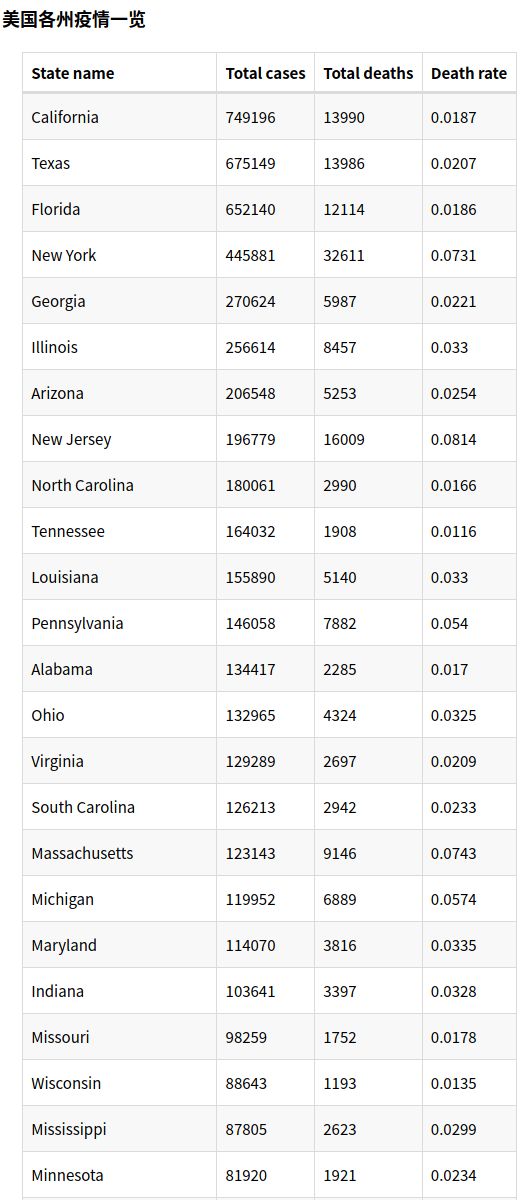
3.统计截止9月9日 美国各州累计确诊人数和死亡人数
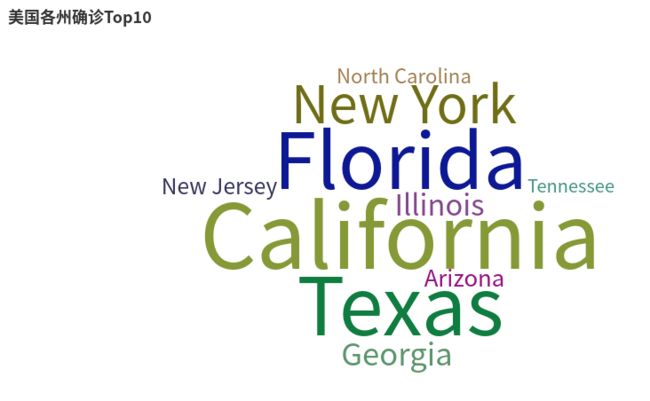
4.统计截止9月9日 美国确诊最多的10个州
5.统计截止9月9日 美国国死亡最多的10个州

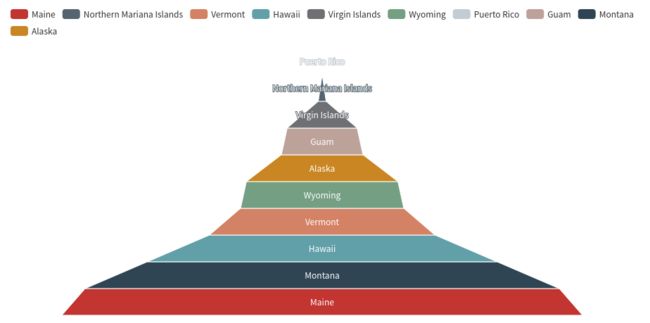
6.统计截止9月9日 美国确诊最少的10个州

7.统计截止9月9日 美国死亡最少的10个州
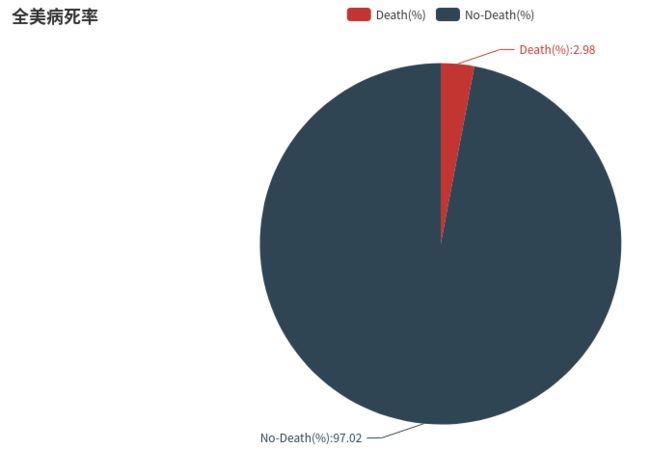
8.统计截止9月9日全美和各州病死率
代码地址:https://gitee.com/yxuan-cs/us_2019-covid
参考:http://dblab.xmu.edu.cn/blog/2636-2/