我的Python心路历程 第十期 (10.2 通达信股票day数据转化为csv)
我的Python心路历程 第十期 (10.2 通达信股票day数据转化为csv)
股票day数据转化为csv,便于pandas分析。详见参考1来下载股票日线数据,如:上证所有证券日线。

其中,需要了解的是通达信日线*.day文件内容:
文件名即股票代码
每32个字节为一天数据
每4个字节为一个字段,
每个字段内低字节在前00 ~ 03 字节:年月日,
整型04 ~ 07 字节:开盘价100,
整型08 ~ 11 字节:最高价100,
整型12 ~ 15 字节:最低价100,
整型16 ~ 19 字节:收盘价100,
整型20 ~ 23 字节:成交额(元),
float型24 ~ 27 字节:成交量(股),
整型28 ~ 31 字节:(保留)
起初用struct.unpack方法解析数据编译报错如下:
![]()
查询源码介绍:


如上所示4字节没啥大问题,实在搞不定了,根据经验估计是struct类对unpack方法做了封装引起的,直接用unpack问题得到解决。
不啰嗦,不含糊。上编译通过的所有代码:
#!/usr/bin/python
# coding=UTF-8
import os
import sys
from struct import unpack
import datetime
#将通达信股票day数据转化为csv,便于pandas分析;以上证所有证券日线数据为例。
def day2csv(fileName, code):
#获取绝对路径,data为当前文件夹
curpath = os.path.join(os.path.dirname(__file__), 'data')
file_object_path = curpath + '/' + code + '.csv'
file_object = open(file_object_path, 'w+')
#初始化csv文件:Date Open High Low Close Acount Volume Adj Close
listname = 'Date' + "," + 'Open' + "," + 'High' + "," + 'Low' + "," + 'Close' + "," + 'Acount' + "," + 'Volume' + "," + 'Adj Close' + '\r\n'
file_object.writelines(listname)
#初始化变量
i = 0
with open(fileName, 'rb') as f:
#有数据就继续处理
while True:
#每次读一条记录,相当于32字节,减小对buf的开销
buf = f.read(32)
# 没有数据了就结束while循环
if not buf:
break
num = len(buf)
no = num / 32
b = 0
e = 32
#items = list()
#解析buf
a = unpack('IIIIIfII', buf[b:e])
year = int(a[0] / 10000);
m = int((a[0] % 10000) / 100);
month = str(m);
if m < 10:
month = "0" + month;
d = (a[0] % 10000) % 100;
day = str(d);
if d < 10:
day = "0" + str(d);
dd = str(year) + "-" + month + "-" + day
openPrice = a[1] / 100.0
high = a[2] / 100.0
low = a[3] / 100.0
close = a[4] / 100.0
amount = a[5] / 10.0
vol = a[6]
unused = a[7]
if i == 0:
preClose = close
i += 1
ratio = round((close - preClose) / preClose * 100, 2)
preClose = close
#暂时用preClose代替,具体如何获取待确认后更新
adjClose = preClose
#整理当前这条记录:Date Open High Low Close Acount Volume Adj Close
item = [dd, str(openPrice), str(high), str(low), str(close), str(amount), str(vol), str(adjClose)]
list = item[0] + "," + item[1] + "," + item[2] + "," + item[3] + "," + item[4] + "," + \
item[5] + "," + item[6] + "," + item[7] + "\r\n"
#每条记录逐个写入csv
file_object.writelines(list)
#print list
print "总共解析%d条记录。"%i
file_object.close()
f.close()
def main():
# 获取绝对路径,data为当前文件夹
curpath = os.path.join(os.path.dirname(__file__), 'shlday')
filepath = curpath + '/' +'sh000001.day'
#执行转化操作,'00001'为csv文件名;如果需要批量操作的话就遍历文件夹下面的所有day文件即可实现
day2csv(filepath, '00001')
if __name__ == "__main__":
main()
通过excel打开csv文件查看效果如下图所示:

需要说明的一点是,此处的adjClose并非取自通信达日线数据,是通过= preClose赋值。从通信达如何获取该值暂时没有答案,不过有辛通过雅虎金融数据中获得了该值,具体可详细参见参考5。
基于数据分析后的展示效果如参考4所述,如下:
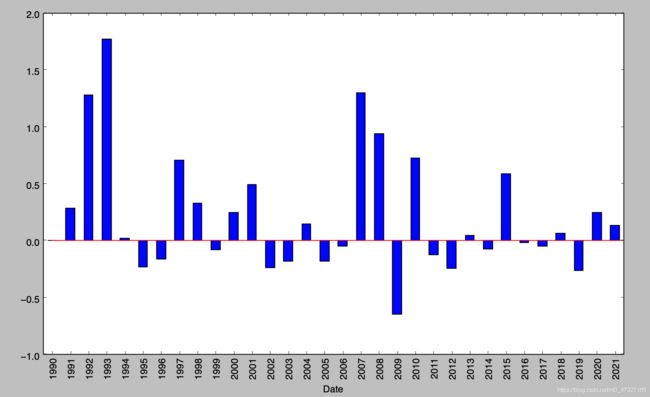
哦耶,妥妥的捋顺了一层皮。
备注:
1、股票数据下载日线数据途径之一Python读取通达信本地数据
2、[python]解析通达信盘后数据获取历史日线数据
3、我的Python心路历程 第十期 (10.1 实践实例之股票数据分析)
4、股票数据下载日线数据途径之二如何下载股票历史数据?
5、我的Python心路历程 第十期 (10.3 雅虎金融股票day数据转化为csv)