Python学习笔记(一)(持续更新)
Python学习笔记(一)(持续更新)
- 学习笔记
- 问题集锦
-
- 问题一:Resource xxx not found.
- 问题二:运行jupyter notebook打不开浏览器
- 问题三:调用的库不在默认安装路径时
- 问题四:csv文件读取问题
-
- 运行报错 AttributeError: ‘Rectangle’ object has no property ‘normed’
因为建模原因开始接触Python,会记下在学习过程中遇到的问题和解决方案
学习笔记
参考资料: https://www.cnblogs.com/traditional/p/12514914.html
问题集锦
问题一:Resource xxx not found.
初次调用nltk库,遇到如下错误
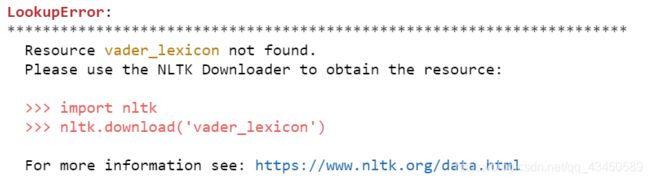
解决方案:进入网站 https://www.nltk.org/install.html ,下载相应版本的nltk下载器,根据网页上的提示进行操作。
当然,也可以直接点击以下网站下载相关文件。(我就是用这种方式下载的,这里只列出了punkt文件的下载路径)
https://github.com/nltk/nltk_data/blob/gh-pages/packages/tokenizers/punkt.zip
问题二:运行jupyter notebook打不开浏览器
利用anaconda打开jupyter notebook,无法启动浏览器,解决方法见如下博客。在网上海找到了设置防火墙的方法,但我试验后发现无效,只有下面博客中的方法一有效。
http://www.cppcns.com/jiaoben/python/306949.html
问题三:调用的库不在默认安装路径时
现有两个同名库函数,假设一个处于默认下载路径,另一个在位置a,现在我想要调用a处的库。
开始我仿照下面链接中的方法,将a加入到搜索路径的最顶端,但毫无作用,在搜索时仍然是先搜索默认路径。好像和绝对路径和相对路径有关,如果有明白的朋友,欢迎在评论区指出原因。
最终我只能将默认路径中的库删除,将a处的库挪到默认路径中,才能正常调用。
网上常见的解决方案:
https://www.cnblogs.com/silence-cc/p/8970368.html
问题四:csv文件读取问题
创建world文件(.py),关键代码如下
fullevents = "C:\Users\fullevents.csv"
passing = r'C:\Users\passingevents.csv'
matches = 'C:\Users\matches.csv'
读取某csv文件,调用方式如下
import csv
with open(world.matches, 'r') as f:
# with open(r'C:\Users\fullevents.csv', 'r') as f:
reader = csv.reader(f)
print(type(reader))
for row in reader:
print(row)
运行后报错

但如果不经过world.py,在主程序中直接调用csv文件,则能够成功运行,代码如下:
import csv
with open(r'C:\Users\fullevents.csv', 'r') as f:
reader = csv.reader(f)
print(type(reader))
for row in reader:
print(row)
部分输出结果如下图所示

运行报错 AttributeError: ‘Rectangle’ object has no property ‘normed’
报错原因:函数hist由于版本更新,部分参数名称发生改变。
解决方案参考博文 https://blog.csdn.net/m0_45408211/article/details/107583589
https://www.jianshu.com/p/72274ccb647a
https://www.dataquest.io/blog/settingwithcopywarning/