空值处理、去重、无穷大(inf)的处理、分组聚合agg、map/apply/applymap、匿名函数(lambda)、透视表、where/mask
1、空值处理
student_excel.xlsx如图: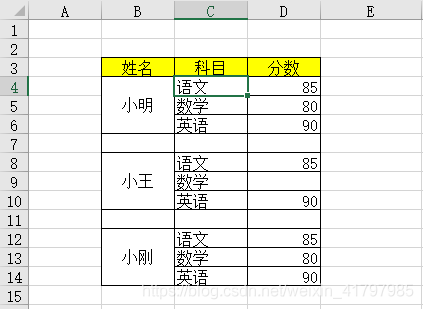
import pandas as pd
#表头为第三行(索引为2)
df1=pd.read_excel(r'C:\Users\9250\Downloads\20201228课后资料\20201228课后资料\student_excel.xlsx',header=2)
print(df1)
print('*'*20)
# 判断每一列中是否包含Nan
# df.isnull().any()
# df.isnull().all() # 是否全是空值
#删除A列(全部无数据),且在原数据上进行更改
df1.dropna(how='all',axis=1,inplace=True)
#删除全为空的行
df1.dropna(how='all',axis=0,inplace=True)
#重置索引
df1.index=range(0,len(df1))
'''
method :
ffill(使用前一个值,使用的是左一个)
bfill(使用后一个值,使用的是右一个)
根据axis的设置
'''
#姓名这一列中的空值 基于空值上面的值填充 ffill,且在原数据上进行修改
df1['姓名'].fillna(method='ffill',inplace=True)
df1['分数'].fillna(method='bfill',inplace=True)
df1
# 填充全部
# df.fillna(0)
# 进行不同的列填充不同的值
# df.fillna({'分数':0,'姓名':'abc'})
2、去重
import pandas as pd
df2=pd.DataFrame({
'A':[1,1,1,2,2,3,1,5],'B':list("aabbbcad")})
display(df2)
#判断该行是否重复 重复返回true
df2.duplicated()
#删除重复的行 keep='first'保留一开始出现的 keep='last'保留最后出现的
df2.drop_duplicates(keep='first')
#基于B列进行重复删除
df2.drop_duplicates(subset=['B'])
3、无穷大(inf)的处理
'''
0/0=0,非0/0=无穷大
可将inf替换成nan
df.replace(np.inf,np.NaN)
'''
4、分组、聚合、agg
# 分组
import numpy as np
# 分组
df=pd.DataFrame({
'name':['BOSS','Lilei','Lilei','Han','BOSS','BOSS','Han','BOSS'],
'Year':[2016,2016,2016,2016,2017,2017,2017,2017],
'Salary':[999999,20000,25000,3000,9999999,999999,3500,999999],
'Bonus':[100000,20000,20000,5000,200000,300000,3000,400000]
})
# print(df)
#df.groupby() 分组
group_by_name = df.groupby(by='name')
#group_by_name
# 查看分组
print(group_by_name.groups)
# 分组后的数量
print(group_by_name.count())
print(group_by_name.count()['Year'])
# 获取一组数据
group_by_name.get_group('BOSS')
for name,group in group_by_name:
print(name)# 组的名字
print(group)# 组具体内容
break
group_by_name_year=df.groupby(['name','Year'])
# for name,group in group_by_name_year:
# print(name)# 组的名字
# print(group)# 组具体内容
# break
# 可以选择分组
print(group_by_name_year.get_group(('BOSS',2016)))
# 将某列数据按数据值分成不同范围段进行分组(groupby)运算
df = pd.DataFrame({
'Age': np.random.randint(20, 70, 100),
'Sex': np.random.choice(['M', 'F'], 100),
})
#print(df)
# 确定年龄段
# df['Age'] 基于哪一列进行范围切割
age_groups = pd.cut(df['Age'],bins=[19,40,65,100],labels=['青年','中年','老年']) # 19-40 40-65 65-100
df.groupby(age_groups).count()
# age_groups = pd.cut(df['Age'], bins=[19,40,65,100])
# print(age_groups)
# print(df.groupby(age_groups).count())
# 按‘Age’分组范围和性别(sex)进行制作交叉表
pd.crosstab(df['Age'], df['Sex'])
# 聚合
df1=pd.DataFrame({
'Data1':np.random.randint(0,10,5),
'Data2':np.random.randint(10,20,5),
'key1':list('aabba'),
'key2':list('xyyxy')})
print(df1)
# df1.groupby('key1').sum()
# 获取某一列聚合之后的结果
df1['Data1'].groupby(df1['key1']).sum()
df1.groupby('key1')['Data1'].sum()
# agg
df1=pd.DataFrame({
'Data1':np.random.randint(0,10,5),
'Data2':np.random.randint(10,20,5),
'key1':list('aabba'),
'key2':list('xyyxy')})
print(df1)
# df1.groupby('key1').agg(['sum','mean'])
# 自定义了一个聚合函数
def peak_range(df):
"""
返回数值范围
"""
return df.max() - df.min()
# 总结: 主要就是做多个聚合运算,agg内部的函数只能返回一个结果值
# df1.groupby('key1').agg(['sum','mean',peak_range])
# [('求和','sum'),'mean',('range',peak_range)]
df1.groupby('key1').agg([('求和','sum'),'mean',('range',peak_range)])
# def peak_range(df):
# """
# 返回数值范围
# """
# return df.max() - df.min()
#
# df1.groupby('key1').agg([('求和','sum'),'mean',('range',peak_range)])
# 给每列作用不同的聚合函数
dict_mapping = {
'Data1':['mean','max'],
'Data2':'sum'
}
df1.groupby('key1').agg(dict_mapping)
5、map/apply/applymap函数
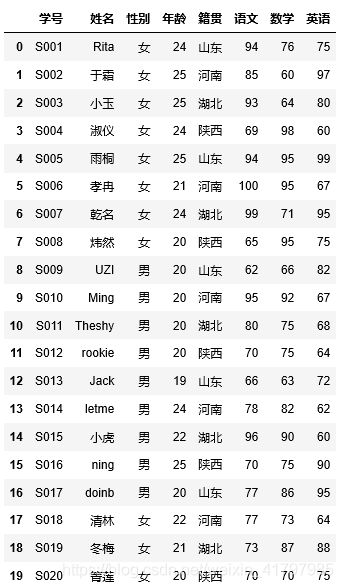
学生信息表.xlsx的数据如下图:
'''
map:只用于Series,实现每个值->值的映射;
apply:用于Series实现每个值的处理,用于Dataframe实现某个轴的Series的处理;
applymap:只能用于DataFrame,用于处理该DataFrame的每个元素
'''
# df = pd.read_excel('./学生信息表.xlsx')
# display(df)
#********************** map ***********************
# 字典的形式
# df['性别映射'] = df['性别'].map({'男':1,'女':0})
# df
# # 以函数的形式
# def func(x):
# if x >= 20 :
# return '成年'
# else:
# return '未成年'
# df['是否成年'] = df['年龄'].map(func)
# df
#********************** map ***********************
#********************** apply ***********************
# apply(用于Series实现每个值的处理)
# def func(x):
# return x.lower()
# df['学号'] = df['学号'].apply(func)
# df
# df['学号'].apply(func)
# apply,在对dataframe
# df[['语文','数学','英语']].apply(sum,axis=0)
# df['总分'] = df[['语文','数学','英语']].apply(sum,axis=1)
# df
#********************** 分组之后的apply ***********************
# 分组之后的apply
# df1=pd.DataFrame({'sex':list('FFMFMMF'),'smoker':list('YNYYNYY'),'age':[21,30,17,37,40,18,26],'weight':[120,100,132,140,94,89,123]})
# print(df1)
# def bin_age(age):
# if age >=18:
# return 1
# else:
# return 0
# # # 抽烟的年龄大于等18的
# df1['age'] = df1['age'].apply(bin_age)
# df1
# # 取出抽烟和不抽烟的体重前二
# def top(somker,col,n):
# return somker.sort_values(by=col)[-n:]
# df1.groupby('smoker').apply(top,col='weight',n=2)
#********************** 分组之后的apply ***********************
#********************** apply ***********************
#********************** applymap ***********************
# applymap 对每一个元素处理
# def func(x):
# return '%.2f' % x
# df[['语文','数学','英语']].applymap(func)
#********************** applymap ***********************
6、匿名函数(lambda)
# 匿名函数
# lambda 表达式,又称匿名函数,常用来表示内部仅包含 一行表达式的函数。
# 匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
# 匿名函数的优势:
# 对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
# 对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
# def add(x, y):
# return x + y
# add(3,4)
# lambda x,y:x+y
# 匿名函数的调用
(lambda x,y:x+y)(3,4)
7、透视表
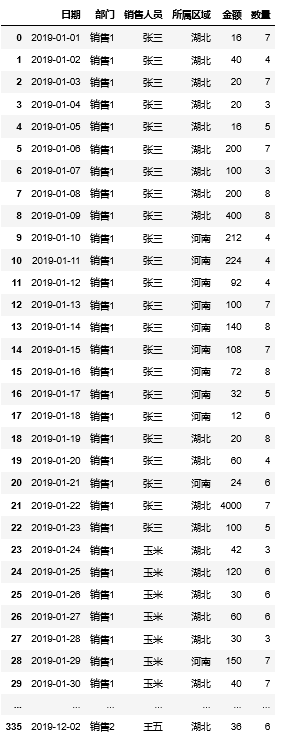
透视.xlsx的数据如下图:
'''
参数解释:
data:dataframe格式数据
values:需要汇总计算的列,可多选
index:行分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的行索引
columns:列分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的列索引
aggfunc:聚合函数或函数列表,默认为平均值
fill_value:设定缺失替换值
margins:是否添加行列的总计
dropna:默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
margins_name:汇总行列的名称,默认为All
observed:是否显示观测值
'''
# 透视表
# df = pd.read_excel('./透视.xlsx')
# display(df)
# 按照部门进行透视,默认计算式求均值
# pd.pivot_table(df,index=['部门'])
# 按照部门和地区进行透视,默认计算式求均值, 可以将列表中的顺序进行调换,调整index的内外层级
# pd.pivot_table(df,index=['所属区域','部门'])
# 默认获取所有数据列的值,可以通过values进行筛选
# pd.pivot_table(df,index=['所属区域','部门'],values=['数量'])
# Columns类似Index可以设置列层次字段,它不是一个必要参数
# pd.pivot_table(df,index=['部门'],columns=['所属区域'])
# 如果出现空值,可以用fill_value填充
# pd.pivot_table(df,index=['部门'],columns=['所属区域'],fill_value=0)
# 对数据聚合时默认计算求均值
# pd.pivot_table(df,index=['所属区域','部门'],aggfunc=[np.sum,np.mean])
# 对不同列进行不同的聚合函数
# pd.pivot_table(df,index=['部门'],values=['数量','金额'],aggfunc={'数量':[np.sum,np.mean],'金额':[('求和',np.sum)]})
8、where/mask
# pandas 中where和mask
'''
where(条件,值):表示不满足条件的,使用设定值,满足条件值不变
mask(条件,值):表示满足条件的,使用设定值,不满足条件值不变
'''
df = pd.DataFrame(np.arange(12).reshape((4, 3)))
display(df)
# df.where(df<5, 0)
# df.mask(df<5, 0)