爬虫库urllib使用(4)分析Robots协议
文章目录
-
-
- 一、Robots协议
- 二、爬虫名称
- 三、robotparser
-
一、Robots协议
Robots协议也称作爬虫协议,机器人协议,网络爬虫排除协议,用来告诉爬虫哪些页面是可以爬取的,哪些页面是不可爬取的。它通常是一个robots.txt的文本文件,一般放在网站的根目录上。
当爬虫访问一个站点的时候,会首先检查这个站点目录是否存在robots.txt文件,如果存在,搜索爬虫会根据其中定义的爬取范围进行爬取。如果没有找到这个文件,搜索爬虫会访问所有可直接访问的页面。
User-agent:*
Disallow:/
Allow:/public/
所有搜索爬虫允许爬取public目录下的页面,
- User-agent: 描述爬虫的名称,将其设置为*表示该协议对任何爬虫有效.
- Disallow:指定不允许爬取的目录,/表示不允许抓取所有页面
- Allow:用来排除某些限制
二、爬虫名称
| 爬虫名称 | 名称 | 网站 |
|---|---|---|
| BaiduSpider | 百度 | www.baidu.com |
| Googlebot | 谷歌 | www.google.com |
| 360Spider | 360搜索 | www.so.com |
| YodaoBot | 有道 | www.youdao.com |
| ia_archiver | Alexa | www.alexa.cn |
| Scooter | altavista | www.altavista.com |
三、robotparser
我们可以使用robotparser模块来解析robots.txt,该模块提供了一个RobotFileParser,他可以根据某网站的robot.txt文件来判断一个爬虫是否有权限来爬取这个网页。
urllib.robotparser.RobotFileParser(url)
- set_url():用于设置robots.txt文件的路径,在创建RobotFileParser对象时没有传入,可调用此方法
- read():读取robots.txt文件进行分析。这个方法执行一个读取和分析操作,如果不调用这个方法,接下来的判断就会为False,一定要调用这个方法。这个方法不返回任何结果
- parse():用于解析robots.txt文件,传入的参数是robots,txt某行的内容,它会按照robots.tx的语法规则来分析这些内容
- can_fetch():该方法传入两个参数,第一个是User-Agent,第二个是抓取的URL,返回的结果是这个链接是否可爬取
- mtime():返回上次抓取和分析robots.txt的时间,如果长时间分析和抓取搜索爬虫,需要定期检查抓取最新的robots.txt
- modified():将当前时间设置为上次抓取和分析robots.tx的时间
from urllib.robotparser import RobotFileParser
from urllib.request import urlopen
rp = RobotFileParser()
rp.set_url("https://www.jianshu.com/robots.txt")
rp.read()
print(rp.can_fetch("*", "https://www.jianshu.com/p/b67554025d7d"))
print(rp.can_fetch("*", "https://www.jianshu.com/search?q=python&page=1&type=collections"))
运行结果:
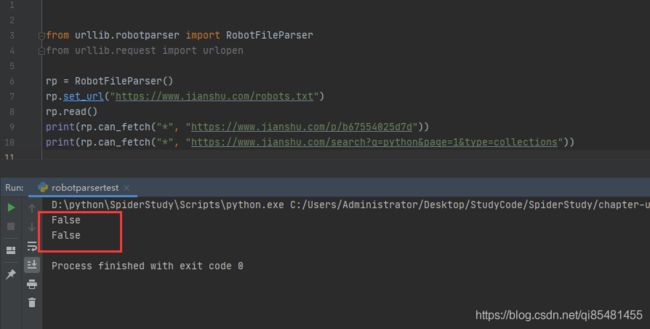
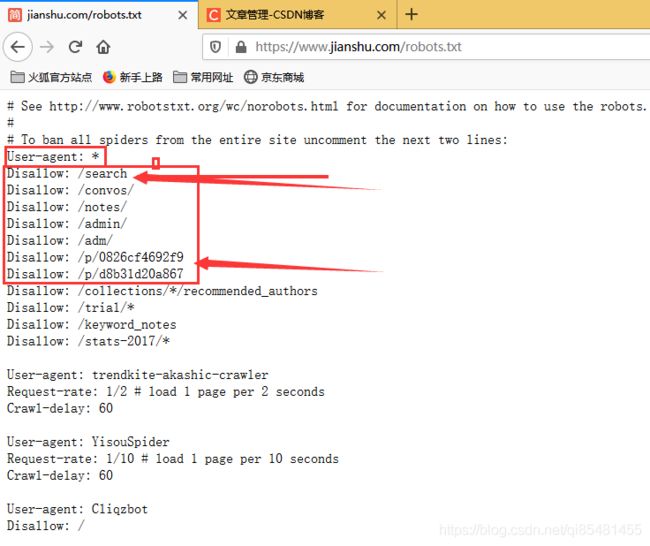 查看简书的robots,可以看到对于*/search* /p是不允许爬取的
查看简书的robots,可以看到对于*/search* /p是不允许爬取的
这里我们可以使用parse()方法执行和读取
rp = RobotFileParser()
rp.parse(urlopen("https://www.jianshu.com/robots.txt").read().decode("utf-8").split("\n"))
print(rp.can_fetch("*", "https://www.jianshu.com/p/b67554025d7d"))
print(rp.can_fetch("*", "https://www.jianshu.com/search?q=python&page=1&type=collections"))