Python人工智能算法笔记(慕课刘经纬老师人工智能)
1.回归分析
import numpy as np
t = np.arange(1,20,1)
y = 0.9 * t + np.sin(t)
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(t,y,"1")
model = np.polyfit(x,y,1)
x2 = np.arange(0,20,0.5)
y2 = np.polyval(model,x2)
plt.plot(x,y,'.',x2,y2,'^')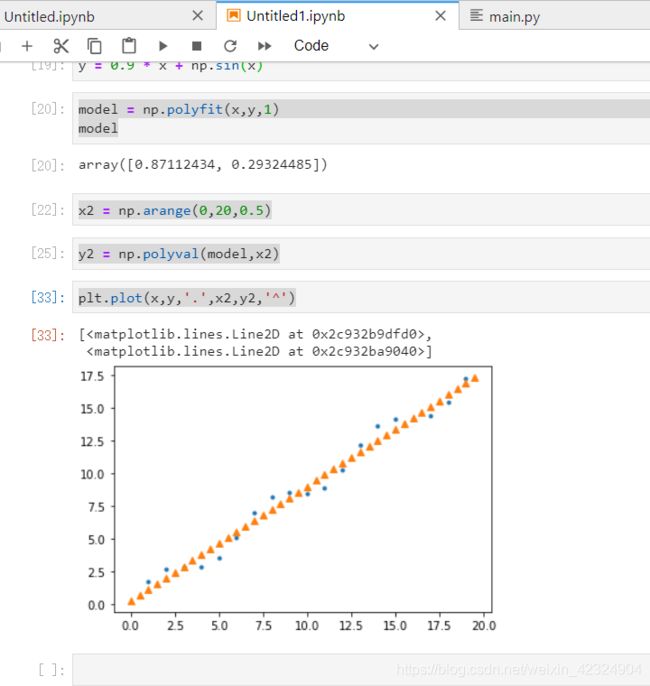
2.K-NN算法分类
由于需要数据,我看的是慕课老师的课,没有数据,我们可以用python生成一些随机数据供测试。python操作excel表格我也是刚去哔哩哔哩看来的,这里可能有些方法比较笨,但是为了节约时间不花太多时间就懒得去查一些简单的方法了。


注意,在执行代码之前,我已经创建过一个classify.xlsx文件,就在当前目录下,然后也将下面那个sheet名称设置成为classify,上图所示
from openpyxl import load_workbook
import random
wb = load_workbook("classify.xlsx")
sheet = wb["classify"]
sheet["A1"] = "id"
sheet["B1"] = "yingyu"
sheet["C1"] = "yuwen"
sheet["D1"] = "shuxue"
sheet["E1"] = "identity"
count = 1
for cell in sheet["A2:A101"]:
cell[0].value = count
count = count + 1
for cell in sheet["B2:B101"]:
cell[0].value = random.randrange(60,101,1)
for cell in sheet["C2:C101"]:
cell[0].value = random.randrange(60,101,1)
for cell in sheet["D2:D101"]:
cell[0].value = random.randrange(60,101,1)
sheet["E1"] = 'classify'
for row in sheet.iter_rows(min_row=2,max_row=101):
str1 = row[1].value
str2 = row[2].value
str3 = row[3].value
avg_yw_yx = (int(str1) + int(str2)) / 2
sx = int(str2)
if avg_yw_yx > sx:
row[4].value = 1
else:
row[4].value = 2
wb.save("classify.xlsx") 这里我的策略是算出语文英语的平均分,和数学比较,数学高就是2,否则就是1.(与老师的略有不同,不过我们的目的是为了分类,这样也能达到测试目的)(剧透一下,这样分类出来的准确率达到了0.95.。
这里我的策略是算出语文英语的平均分,和数学比较,数学高就是2,否则就是1.(与老师的略有不同,不过我们的目的是为了分类,这样也能达到测试目的)(剧透一下,这样分类出来的准确率达到了0.95.。
import os
thisFilePath = os.path.abspath('.')
os.chdir(thisFilePath)第一步,将工作路路径设置为当前
import pandas as pd
df = pd.read_csv('classify.csv')
# print(df.head())
train_x = df.iloc[0:80,1:4]
train_y = df.iloc[0:80,4]
# print(train_x.head())第二步,熊猫包,读取csv
然后读取出训练集合。
from sklearn import neighbors
model = neighbors.KNeighborsClassifier()
model.fit(train_x,train_y)第三步,就是训练出一个模型,这个模型叫做model
然后测试输入集合,作为输入,给这个模型,然后这个模型给出预测输出
test_x = df.iloc[80:100,1:4].values
# print(test_x)
test_y = df.iloc[80:100,4].values
test_p = model.predict(test_x)
只有一个是不对的。