论文阅读笔记(8)——《Learning Representation Mapping for Relation Detection in KBQA》
- Abstract
- 1 Introduction
- 2 Representation Adapter
-
- 2.1 Motivation
- 2.2 Basic Adapter
-
- Pseudo Target Representations
- Linear Mapping
- 2.3 Adversarial Adapter
- 2.4 Reconstruction Loss
- 3 Relation Detection with the Adapter
-
- Framework
- Adapting the Relation Representation
- Training
- 4 SimpleQuestion-Balance (SQB)
- 5 Experiment
-
- 5.1 Settings
-
- Implementation Details
- Evaluation
- 5.2 Main Results
-
- Baseline
- Using Adapters
- Using Reconstruction Loss
- Integration to the KBQA
- 5.3 Analysis
-
- Seen Relation Bias
- Influence of Number of Relations for Training
- Relation Representation Analysis
- Adapting JointNRE
- Case Study
- 6 Related Work
-
- Relation Detection in KBQA
- Embedding Mapping
- Zero-Shot Learning
- 7 Conclusion
Title: Learning Representation Mapping for Relation Detection in Knowledge Base Question Answering
来源:ACL 2019
Contributor: 计算机软件新技术国家重点实验室,南京大学,华为科技泊松实验室
Paper: https://arxiv.org/pdf/1907.07328v1.pdf
Code: https://github.com/wudapeng268/KBQA-Adapter
本文探讨的问题仍然关注于知识库问答的固有缺陷:知识库不可能涵盖 QA 任务所需的所有关系。
主要研究的问题:研究KBQA中的关系检测步骤,测试数据中可能出现训练数据中没有出现过的关系,而模型从来没有学习过它们的嵌入,导致模型表现受到影响。
Abstract
Relation Detection(关系检测)是包括知识库问答在内的许多自然语言处理应用的核心步骤。目前对于关系已在训练数据中的情况,可以得到较高的准确度。当应对不可见的关系时,准确度将迅速下降。造成这一问题的主要原因是不可见关系的表示形式缺失。为此,本文提出了一种简单的映射方法——表示适配器(representation adapter),该方法基于先前学习的关系嵌入来学习可见和不可见关系的表示映射。利用 adversarial objective(对抗目标)和 reconstruction objective(重构目标)来提高映射性能。本文重新组织了流行的 SimpleQuestion 数据集来揭示和评估检测不可见关系的问题。实验表明,该方法能显著提高不可见关系的性能,而可见部分的性能保持在与现有方法相当的水平。
1 Introduction
知识库问答近年来取得不错的进展,它使用开放域知识库回答问题。知识库通常包含大量三元组triple,每个 triple 的形式是
典型的知识库问答系统 (KBQA) 可以分为两步:
- 实体链接步骤:首先确定问题的目标实体,该实体与三元组的主体相对应;
- 关系检测步骤:然后从一组候选关系中确定问题提出的关系。
经过这两个步骤,可以通过从知识库中提取相应的三元组来获得答案。

本文的主要重点是关系检测步骤,它更具挑战性,因为它需要考虑整个疑问句的含义(例如,“出生于……的地方”的模式)以及句法的含义,还有候选人关系(例如,“出生地”)。 而实体链接步骤受益于问题中的单词与主体实体之间的表面形式的匹配。
在最近的基于深度学习的关系检测方法中,每个单词或关系都由一个稠密向量表示,称为 Embedding嵌入,它通常在优化关系检测目标时自动学习得到。然后通过神经网络计算进行推断。这些方法在常见的 KBQA 数据集上取得了巨大的成功,例如 SimpleQuestion。
但作者注意到,在 SimpleQuestion 数据集的常见拆分中,训练集中也存在测试集中 99% 的关系,这意味着在训练过程中可以很好地学习它们的嵌入。相反,对于那些从未在训练数据中看到的关系(称为 unseen relations),自初始化以来就从未对它们的嵌入进行过训练。结果检测性能并不好,这是亟待研究的问题。
在大规模知识库中为所有关系建立训练数据是不可行的。 该问题可以被视为 zero-shot 学习问题,其在训练数据集中看不到测试实例的标签。
本文对这个 zero-shot 关系检测问题进行了详细研究,作者的贡献总结为:
- 没有仅从训练数据中学习关系表示,而是从覆盖面更广的整个知识图中学习表示。
- 提出一种映射机制,称为 Representation Adapter(表示适配器),或 adapter,将学习到的表示集成到关系检测模型中。从适配器的简单 mean square error loss(均方误差损失)入手,并提出集成对抗性和重建目标函数以改善训练过程。
- 将 SimpleQuestion 数据集重新组织为 SimpleQuestion-Balance,以分别评估可见和不可见关系的表现。
2 Representation Adapter
2.1 Motivation
人类注解数据的表示学习受限于训练数据的大小和覆盖范围。关于不可见关系的表示无法在训练时被模型学习的问题,一种可能解决方案是采用大量未注释的数据(可能更容易获得)以提供更好的覆盖范围。
通常,预训练所得的嵌入向量并不直接适用于特定任务,而是需要进行特定于任务的微调。然而由于上文提到的覆盖问题,不可见的关系向量无法在微调过程中被正确更新,导致测试时的表现较差。
为了解决关系向量在微调中无法被正确更新的这个问题,本文提出在训练过程中保持关系的表示不变,并提出一种表示适配器,以弥合通用表示(预训练所得的表示)和任务特定表示之间的差距。接下来是三种适配器框架的介绍。
一些 notations:
- r:一个relation
- S:the set of seen relations
- U:the set of unseen relations
- e ( r ) e(r) e(r) or e e e:the embedding of r
- e g e_{g} eg:general pre-trained embedding
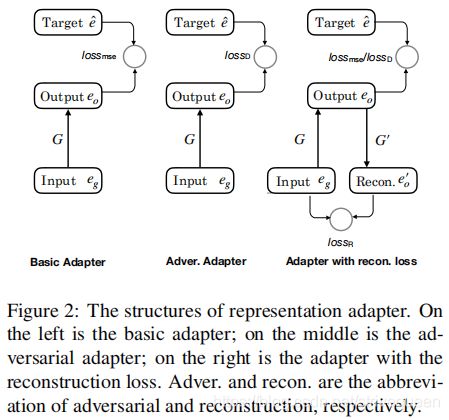
2.2 Basic Adapter
Pseudo Target Representations
伪目标表示 基本思想是使用一个神经网络表示适配器执行由通用表示到任务特定表示的映射。适配器的输入是从知识库学习得到的 embedding 。然而,适配器的输出是不确定的,因为没有用于关系检测任务的准则 (oracle) 表示。
因此,作者首先训练类似于 Yu 等人的传统关系检测模型(HR-BiLSTM)。在训练期间,将更新训练集中的关系表示形式(可见关系)以进行关系检测任务。 作者使用这些表示作为伪目标表示,用 e ^ \hat{e} e^ 表示,以训练适配器。
Linear Mapping
线性映射 受到 Mikolov 等人的启发,它展示了相似语言的表示空间可以通过线性映射转换,作者也使用一个线性映射函数 G ( ⋅ ) G(\cdot) G(⋅) 来将通用嵌入 e g e_{g} eg 映射到任务特定(伪目标)表示 e ^ \hat{e} e^。
作者提出的适配器和神经网络中的一层(extra layer)的主要区别是,特定的损失被用于训练适配器,而不是隐式地将适配器作为整个网络的一部分。
L adapter = ∑ r ∈ S loss ( e ^ , G ( e g ) ) \mathcal{L}_{\text {adapter }}=\sum_{r \in S} \operatorname{loss}\left(\hat{e}, G\left(e_{\mathrm{g}}\right)\right) Ladapter =r∈S∑loss(e^,G(eg))
上式:loss(任务特定表示, 线性映射(通用表示))
此处的损失函数,可以是评估两个表示之间差异的任何度量。 最常见和最简单的方法是在基本适配器中采用的均方误差(如下式)。其他可能性将在后文讨论。
loss M S E ( e ^ , G ( e g ) ) = ∥ e ^ − G ( e g ) ∥ 2 2 \operatorname{loss}_{\mathrm{MSE}}\left(\hat{e}, G\left(e_{\mathrm{g}}\right)\right)=\left\|\hat{e}-G\left(e_{\mathrm{g}}\right)\right\|_{2}^{2} lossMSE(e^,G(eg))=∥e^−G(eg)∥22
2.3 Adversarial Adapter
对抗适配器
均方误差只衡量两个嵌入向量之间的绝对距离。受到生成对抗网络(GAN),和之前一些无监督机器翻译等工作的启发,作者使用一个 discriminator(判别器)提供对抗损失来指导训练。这是最小化伪目标表示 e ^ \hat{e} e^ 和通用表示 G ( e ) G(e) G(e) 之间的差异的另外一种方法。
从细节看,作者训练了一个判别器 D(·) 来分辨“真实”的表示,即被微调的关系嵌入 e ^ \hat{e} e^。它是从适配器的输出,即“虚假”的表示中分辨出来的。
适配器 G(·) 扮演了 GAN 中 generator(生成器)的角色,它尝试生成类似于“真实”表示的表示。作者使用 WassersteinGAN 训练适配器。对于任何从训练集中采样的关系,判别器和生成器的目标函数分别是:
loss D = E r ∈ S [ D ( G ( e g ) ) ] − E r ∈ S [ D ( e ^ ) ] los s G = − E r ∈ S [ D ( G ( e g ) ) ] \begin{array}{c} \operatorname{loss}_{\mathrm{D}}=\mathbb{E}_{r \in S}\left[D\left(G\left(e_{\mathrm{g}}\right)\right)\right]-\mathbb{E}_{r \in S}[D(\hat{e})] \\ \operatorname{los} s_{\mathrm{G}}=-\mathbb{E}_{r \in S}\left[D\left(G\left(e_{\mathrm{g}}\right)\right)\right] \end{array} lossD=Er∈S[D(G(eg))]−Er∈S[D(e^)]lossG=−Er∈S[D(G(eg))]
这里对于D(·),我们使用一个前馈神经网络,没有最后一层的sigmoid函数。
2.4 Reconstruction Loss
重构损失函数
适配器只能通过可见关系的表示学习映射,这忽略了大量不可见的关系。这里作者提出额外的重构损失来增强适配器。具体而言,使用一个反转的适配器 G ′ ( ⋅ ) G^{\prime}(\cdot) G′(⋅),将通用嵌入的线性映射 G ( e ) G(e) G(e),映射回通用嵌入 e e e。
使用反转训练的优势包括两方面:
- 可以由所有的关系来学习,可见、不可见的关系都可以
- 反转映射能作为一种正则化前向映射的额外约束。
对于反转适配器 G ′ ( ⋅ ) G^{\prime}(\cdot) G′(⋅),作者采用类似于基本适配器中的线性映射 G ( ⋅ ) G^{}(\cdot) G(⋅) 的均方误差:
los s R = ∑ r ∈ S ∪ U ∥ G ′ ( G ( e g ) ) − e g ∥ 2 2 \operatorname{los} s_{\mathrm{R}}=\sum_{r \in S \cup U}\left\|G^{\prime}\left(G\left(e_{\mathrm{g}}\right)\right)-e_{\mathrm{g}}\right\|_{2}^{2} lossR=r∈S∪U∑∥G′(G(eg))−eg∥22
注意:不同的是,重新构建的损失函数是同时针对可见关系和不可见关系的。
3 Relation Detection with the Adapter
本文将 adapter 集成到最先进的(state-of-the-art)关系检测框架 Hierarchical Residual BiLSTM (HR-BiLSTM)。
Framework
该框架使用问题网络将问题句子编码为向量 q f q_{f} qf,并使用关系网络将关系编码为向量 r f r_{f} rf。 这两个网络都基于具有最大池化操作的 Bi-LSTM。 然后,引入余弦相似度以计算 q f q_{f} qf 和 r f r_{f} rf 之间的距离,从而确定检测结果。作者提出的 adapter 是关系网络中用于增强此框架的附加模块。
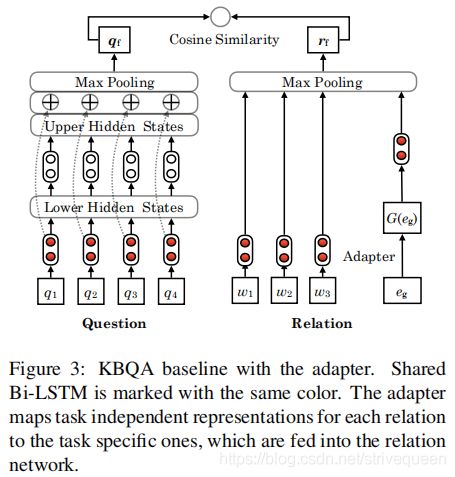
Adapting the Relation Representation
调整关系表示 由 Yu 等人提出的关系网络在关系表示上有两部分:word-level和 relation-level。这两部分被送入关系网络,来生成最终的关系表示。
与之前的方法不同,作者在 relation-level 层表示上使用所提出的适配器 G ( ⋅ ) G^{}(\cdot) G(⋅) 来解决不可见的关系检测问题。本文使用JointNRE embedding(Han等人,
(2018)将知识库中的关系表示转化为通用空间,因为它的 word 和 relation 表示在同一个空间。
Training
跟随 Yu 等人,关系检测模型通过 hinge 损失函数进行训练。它尝试将每个负样本和正样本的分数通过间距分开:
L r d = ∑ max ( 0 , γ − s ( q f , r f + ) + s ( q f , r f − ) ) \mathcal{L}_{\mathrm{rd}}=\sum \max \left(0, \gamma-s\left(\mathbf{q}_{\mathrm{f}}, \mathbf{r}_{\mathrm{f}}^{+}\right)+s\left(\mathbf{q}_{\mathrm{f}}, \mathbf{r}_{\mathrm{f}}^{-}\right)\right) Lrd=∑max(0,γ−s(qf,rf+)+s(qf,rf−))
- γ \gamma γ:the margin
- r f + \mathbf{r}_{\mathrm{f}}^{+} rf+:标注的训练数据中的关系正样本。
- r f − \mathbf{r}_{\mathrm{f}}^{-} rf−:从剩余关系中抽样得到的负样本。
- s ( ⋅ , ⋅ ) s(\cdot, \cdot) s(⋅,⋅):the cosine distance between q f q_{f } qfand r f r_{f} rf
基本的关系检测模型是预训练的,以获得伪目标表示。adapter集成在训练过程中,和关系检测模型联合优化。对于 adversarial adapter,将按照常规做法交替训练生成器和判别器。
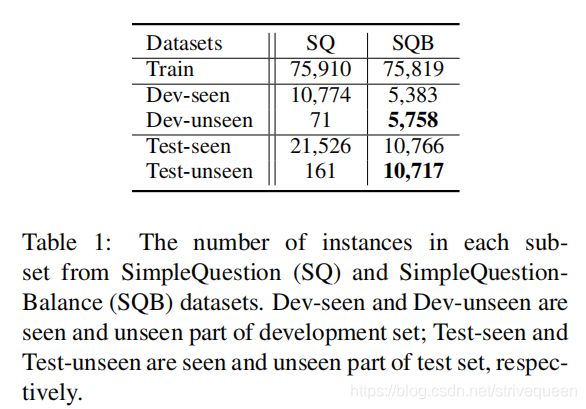
4 SimpleQuestion-Balance (SQB)
SimpleQuestion(SQ)是一个大规模的KBQA数据集。在SQ中的每个样本包括一个人工标注的问题和相应的知识三元组。但是,测试集中的关系是不平衡的,测试集中的大部分关系都在训练数据中得到了体现。为了更好地评估未出现关系的检测性能,该论文重新组织了SQ数据集,以平衡开发和测试集中已出现和未出现的关系的数量,新的数据集表示为SimpleQuestion-Balance(SQB)。
5 Experiment
5.1 Settings
Implementation Details
训练 adapter 的 optimization strategy:RMProp
learning rate: 1 0 − 4 10^{-4} 10−4
batch size:256
将 discriminator 的参数剪辑为 [c, c],其中 c = 0.1
Dropout rate:0.2
关系检测模型baseline:HR-BiLSTM
不同:模型的词嵌入和关系嵌入是由 JointNRE (Han et al., 2018)在FB2M和维基百科数据集,并应用Han等人报告的 default settings (2018)预训练得到的。嵌入是通过模型进行微调的。
relation representation 的维度:300
hidden state of Bi-LSTM 的维度:256
神经模型中的参数使用 uniform sampling(均匀采样)进行初始化
negative sampled relations 的数量:256
γ \gamma γ = 0.1
Evaluation
Micro average accuracy:所有样本的平均精度
Macro average accuracy:关系的平均精度
注意:由于不同的关系在测试集中对应的样本数量不同,所以微观平均精度可能会受到测试集中看不见的关系分布的影响。在这种情况下,宏观平均精度将作为替代指标。
本文报告平均值和标准偏差(std)的10倍交叉验证,以避免偶然性。
5.2 Main Results
关系检测在SQB数据集上的微观平均精度和宏观平均精度:
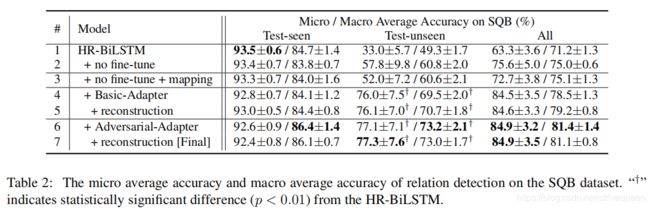
Baseline
基线HR-BiLSTM(第1行)显示了在 Test-seen 的最佳性能,但在 Test-unseen 时的性能要差得多。
相比之下,未经微调的训练模型(第2行)在 Test-unseen 获得更好的结果,证明了我们的动机,即 embedding 是 unseen relations 表现不佳的原因,而微调使它们变得更糟。
Using Adapters
第3行显示了在预先训练的嵌入网络和关系检测网络之间添加额外的神经网络映射层的结果,没有任何损失。
结果表明,该模型能较好地预测未知关系。
使用对抗式适配器(第6行)可以进一步提高 Test-unseen 的微观和宏观平均分数。
Using Reconstruction Loss
将重构损失添加到基本适配器也可以略微提高性能(第5行vs .第4行)。
Integration to the KBQA
采用不同的关系检测模型对整个KBQA系统的微平均精度进行了测试:

5.3 Analysis
Seen Relation Bias
在 Test-unseen 中,计算了该预测率的宏观平均值:
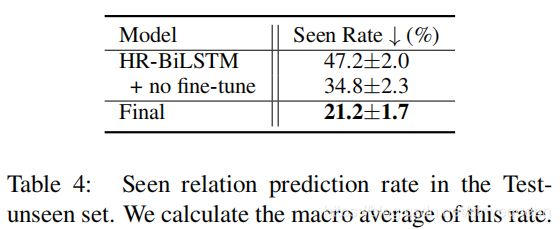
seen rate:使用 macro-average 来计算在 Test-unseen 的关系被错误预测为 seen relation 的实例的百分比。越小越好。
adapter 弱化了选择可见关系的趋势,有助于促进可见关系和不可见关系之间的公平选择。
Influence of Number of Relations for Training
本文从训练集中随机抽取60000个样本执行训练,并对不同数量的训练关系绘制精度图,报告 Test-unseen 的宏观平均精度:

Relation Representation Analysis
在 TensorBoard 的帮助下,通过主成分分析(PCA)将JointNRE、HR-BiLSTM中的关系表示和最终 adapter 的输出表示可视化:

Adapting JointNRE
Case Study
本文的模型仍然不能处理词与词之间的细微语义差异。
6 Related Work
Relation Detection in KBQA
Yu等人(2017)首先注意到KBQA关系检测中的 zero-shot 问题。
Embedding Mapping
与将单词映射为不同语言的工作不同,本文在异构数据生成的表示之间进行映射,即 knowledge base and question-triple pairs。
Zero-Shot Learning
本文使用知识图嵌入作为可见与不可见关系之间的桥梁,这与之前的工作相似。然而,在关系检测方面的研究较少。
7 Conclusion
本文讨论了 KBQA 中不可见关系的检测。其中主要问题在于这类关系表示的学习。 作者将 SimpleQuestion 数据集重组为 SimpleQuestion-Balance,以揭示和评估问题,并提出一个可显著改善结果的 adapter。
作者强调,对于其他任何包含大量非可见样本的任务,针对可见样本进行训练、微调是不合理的。类似的问题可能存在于其他 NLP 任务,在未来进行探索将是有趣的。