ISE,FPGA和LDPCC译码器
阶段总结 V1.0 2015/5/03 |
ISE,FPGA和LDPCC译码器 |
概述 |
本文总结了LDPC码的译码器设计方法,包括MATLAB和FPGA代码,以及ISE使用过程中的一些问题。本文内容具体包括以下几个部分 |

修订历史 |
以下表格展示了本文档的修订过程
|

简介 |
不知不觉中,接触LDPC码已近四个月了,在这四个月里,也对LDPC码的各个方面学习做了一些记录,具体包括(最后的数字代表本文撰写时笔记的最新版本更新日期) [1] 学习笔记_LDPC编译码基本原理_201502018 [2] 程序说明_LDPC译码算法代码概述_20150316 [3] 程序说明_LDPC编码(CCSDS)算法概述_20150303 [4] 应用笔记_LDPC译码器的FPGA实现_20150317 [5] 学习笔记_LDPC译码器的FPGA实现_20150327 [6] 学习笔记_MATLAB向量化计算_20150417 其中,[1]主要叙述了LDPC译码的基本原理,包括置信传播、和积算法和因子图;[2]主要叙述了LDPC译码算法的MATLAB代码的编写思路;[3]主要叙述了CCSDS中的LDPC码的构造方法;[4]主要叙述了LDPC码译码器的FPGA代码的基本程序结构和信号定义;[5]主要叙述了在编写LDPC码译码器的Verilog代码时的一些思路和想法,以及教训;[6]是针对MATLAB代码运行速度过慢做出修正过程中的一些想法和总结。 本文不再重复LDPC码的原理等内容,这些内容可以在[1]~[6]中找到。本文将阐述(针对CCSDS文档中LDPC码)部分并行(和[4]中每个时钟周期更新约1个变量不同,部分并行每个时钟周期更新多个变量)的LDPCC译码器设计过程。 |

考虑[4][5]中译码算法的实现方法,会发现完成一次迭代所需要的时钟周期约为Block RAM的深度×2 。这是因为我们将所有的校验/变量节点信息存储在一个Block RAM内,这也就意味着每个周期我们只能够读取1个校验/变量节点信息。当然,在一个地址存放多个节点信息是可以在变量节点更新或校验节点更新阶段花费更少的时钟周期,但这会带来另一阶段寻址的麻烦。 结合具体的校验矩阵,[4][5]中采用了一个Block RAM来存放地址,但校验矩阵是准循环的,这一部分资源是可以节约下来的。谈到这里,不妨看看校验矩阵(以2/3码率为例) 校验矩阵很自然的分成了3×7个小的准循环矩阵(包含0矩阵),而小的准循环矩阵又是由1~3个行和为1的准循环矩阵构成,很自然的想法是采用23个RAM来分别存储这23个行和为1的准循环矩阵节点的信息。这一想法的实现可以参见MATLAB代码,这也是采用[6]中各种方法的改进算法的结果之一。 以信息为长度为16384为例,假设vl是经过8bit量化(有符号,补码)后的结果,译码过程如下 % 初始化 decoderData = zeros(1,16384); vml = zeros(23,4096); uml = vml; vml(1:4,:) = repmat(vl(1:4096),4,1); vml(5:8,:) = repmat(vl(4097:8192),4,1); vml(9:10,:) = repmat(vl(8193:12288),2,1); vml(11:14,:) = repmat(vl(12289:16384),4,1); vml(15:16,:) = repmat(vl(16385:20480),2,1); vml(17,:) = vl(20481:24576); vml(18:23,:) = repmat(vl(24577:28672),6,1); % 校验节点更新,不完全 vmltemp1 = [vml(17,:);vml(18,:);vml(19,rowIndex(1,:));]; vmltemp1Mark = ones(size(vmltemp1)); vmltemp1Mark(vmltemp1<0) = -1; vmltemp1Mark_t = repmat(1*prod(vmltemp1Mark),3,1); vmltemp1Mark = vmltemp1Mark.*vmltemp1Mark_t; vmltemp1_min = sort(abs(vmltemp1)); vmltemp1_min1 = repmat(vmltemp1_min(1,:),3,1); vmltemp1_min2 = repmat(vmltemp1_min(2,:),3,1); min1_index = find(abs(vmltemp1) == vmltemp1_min1); vmltemp1 = vmltemp1_min1; vmltemp1(min1_index) = vmltemp1_min2(min1_index); vmltemp1 = vmltemp1.*vmltemp1Mark; % ……………… uml(17,:) = vmltemp1(1,:); uml(18,:) = vmltemp1(2,:); uml(19,rowIndex(1,:)) = vmltemp1(3,:); % ……………… uml_8 = round(uml/8); uml_16 = round(uml/16); uml = uml-uml_8-uml_16; % 变量节点更新,不完全 umltemp1 = uml(1:4,:); umltemp1_sum_vl = sum(umltemp1) + vl(1:4096); umltemp1 = repmat(umltemp1_sum_vl,4,1) - umltemp1; % ………… umltemp3 = uml(9:10,:); umltemp3_sum_vl = sum(umltemp3) + vl(8193:12288); umltemp3 = repmat(umltemp3_sum_vl,2,1) - umltemp3; % ………… umltemp5 = uml(15:16,:); umltemp5_sum_vl = sum(umltemp5) + vl(16385:20480); umltemp5 = repmat(umltemp5_sum_vl,2,1) - umltemp5; % ………… vml = [umltemp1;umltemp2;umltemp3;…;umltemp7]; qn0_1 = [umltemp1_sum_vl umltemp2_sum_vl umltemp3_sum_vl ...]; 译码过程较为简单,考虑上述代码中应用的函数。函数repmat通过控制RAM读写可以实现;函数prod实际上是符号的改变,可以用模二加代替;函数sort实际上是求最小值和次小值,这也可以通过一定比较得出,不一定需要进行排序;函数sum求和即可。归一化因子选择了0.8125,近似成为 uml_8 = round(uml/8); uml_16 = round(uml/16); uml = uml-uml_8-uml_16; 通过移位和加减可实现该过程。 |
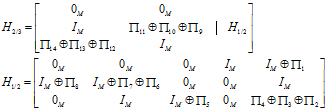

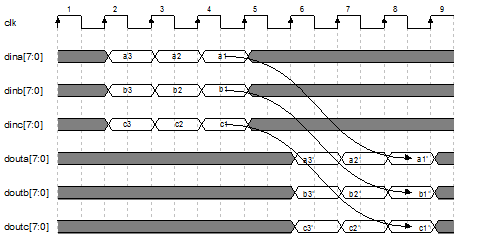
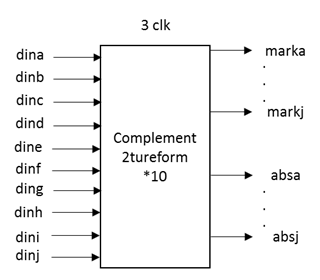
此处的功能设计指校验节点更新,变量节点更新和校验方程计算三个模块的设计方法。包括 校验节点更新,即行更新,校验矩阵行重为3或10 。最小和算法更新规则是找到除本身之外的最小绝对值作为更新值绝对值,以及所有符号之乘积作为符号。 先考虑行重为3的情况,如图 1所示,需要更新的数据并行输入(从多个RAM内同时读取),延迟4个clk后并行输出,模块输出值为更新后的结果。
图 1 校验节点更新时序图
在这5个时钟周期内,完成了以下操作
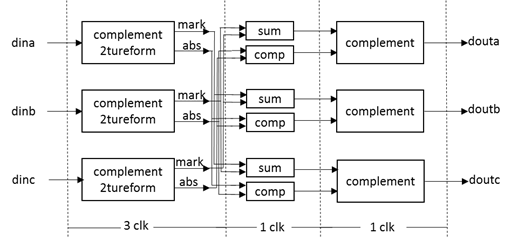
图 2校验节点更新结构图
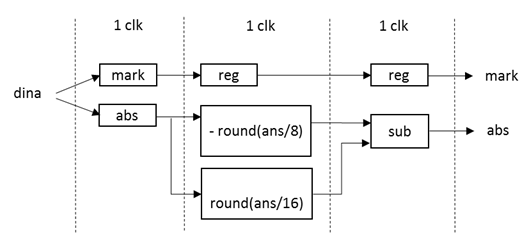
图 2中sum、comp、complement模块通过简单的选择和加法可以完成;延迟3clk的complement2tureform模块通过描述如图 3(此处取名complement2tureform沿用最小和算法中名称,但此处同时进行了归一化处理)。
图 3 complement2tureform结构图
以上为3输入的更新代码,然而对于行重为10的情况,必须采用其他方法更新。(3输入下寻找的是除自己本身外的最小值,这是容易获得的;对于10输入则不然,需要找到最小值和次小值,按MATLAB代码中所描述步骤操作)。 虽然有所差异,但是complem2tureform模块是一样的,都需要对其进行归一化和求取绝对值、符号的操作,如图 4所示。
图 4 校验节点更新处理模块(行重10)
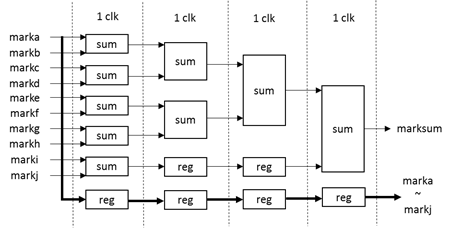
之后,需要求得更新后的符号和绝对值。求符号实际上是模二和的过程,求解思路参见MATLAB代码,先求所有输入的符号之乘积,再乘以本身即可。如图 5所示,其中sum代表模二和。
图 5 校验节点-符号更新(行重10)
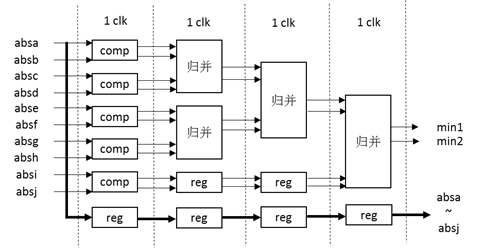
求解更新后绝对值这个过程则更为复杂一些,MATLAB代码中采用sort函数,在FPGA中排序还不如求最小值和次小值。最小值易求,次小值难得,因为在比较过程中,很有可能最小值遇到次小值,之后次小值就被抛弃了。这意味着每次比较过程中,必须要留下两个最小的量,而不是一个。同时为了让每个周期FPGA处理模块不太复杂,考虑归并排序的思想,如图 6所示。 其中,此处的comp模块具有两个输出,输出有序。即输入dina、dinb输出douta = min{dina,dinb};归并排序实际上是将两个有序数组结合为一个有序数组,此处由于之需要最小和次小,故归并模块只有两个输出。输入dina<dinb,dinc<dind, 输出douta为输入最小值,doutb为输入次小值。自此可求得最小值和次小值,满足了MATLAB中sort的要求。
图 6 校验节点-求最小值(行重10)
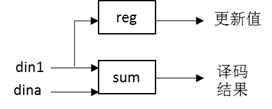
由图 5、图 6输出,可以在一个周期内求的更新后输出,结合得到行重为10下的更新模块。延时为8个周期。 位拓展考虑: 对于最小和算法,输入范围为-128~127,输出可能有128的可能性,有溢出的可能,可以采用取绝对值时限制范围为0-127解决。 归一化最小和算法由于有了0.8125的归一化因子存在,不会溢出,但是在取绝对值的时候,输入8位则绝对值也应该是8位(考虑128),而不应该变为7位。之后可进行截位(变小,所以可以直接截取低7位)。 校验矩阵的列重有1、2、4、6四种,一般而言是不可能编写出通用的Verilog代码的。和校验节点更新一样,变量节点更新有4个不同的模块对应不同的列重。 变量节点更新的同时可以输出本次迭代下的译码结果和变量节点更新值,计算模块需要输入信道信息(记为din1)和校验节点信息(记为dina,dinb,……)。
图 7列重1下变量节点更新
图 8列重2下变量节点更新
图 9列重4下变量节点更新
图 10列重6下变量节点更新
图 7、图 8中描述功能较为简单,计算分别有1、2个时钟周期的延时。图 9、图 10中accumlate模块有修改,这是修改后的结果(见时序收敛和流水线)。这两种情况下分别有3、4个时钟周期的延时。 整个计算过程中需要注意位拓展和截位的相关操作。
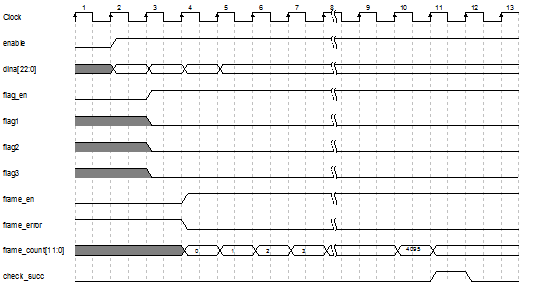
计算校验方程实际上就是计算每行的模二加是否等于0,行计算的过程和行更新(校验节点更新)。我们不妨使译码结果的存储结构和变量节点存储结构一致,那么我们就可以采用一套地址,在行更新的同时计算上一次迭代的译码结构是否满足校验方程。但这样我们需要使用更多的RAM,然而对于采用这种方法带来的便利来说,多占用的RAM是不足为道的。 由于控制信号的缘故,这里描述的方法和代码中有一定区别(代码有延迟),但思路是一致的。校验矩阵分块,每次计算3个方程,同时每时钟周期输入23个译码结果。我们需要有信号指定校验方程计算是否开始,同时在计算结束后判断是否满足校验方程。如图 11所示,该图表示译码结果满足校验方程,因为在最后check_succ信号置高了一个周期。 图 11 校验方程计算时序图 |
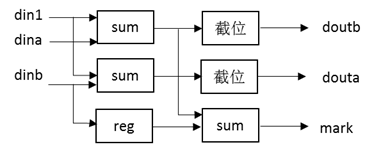
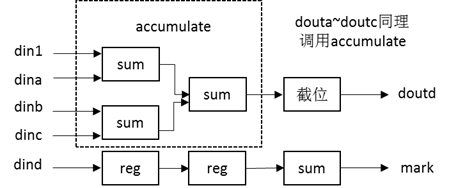
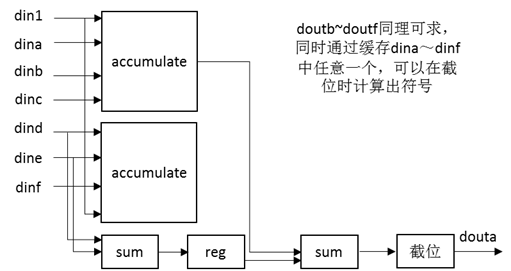

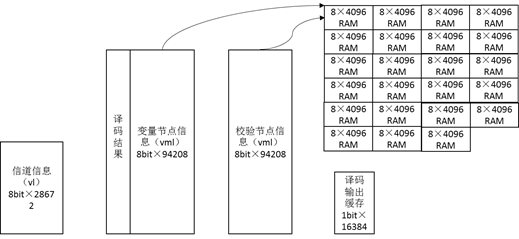
之前[4]的代码中,将所有的变量/校验节点信息存放在了一大块RAM内部,此处将校验矩阵划分为23个部分后,我们将采用23个RAM分别存储这些信息,如图 12所示。
图 12 存储结构
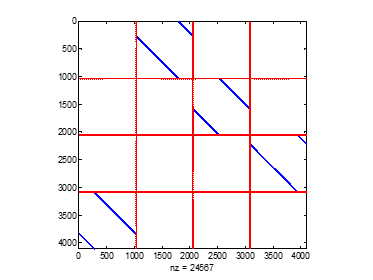
图 12中没有表现出来的是,由于译码结果和变量节点一致,所以将其拼接存在9bit位宽的RAM中,而校验节点是8bit位宽,其余一致。同时初始化过程也可部分并行进行,信道信息寻址固定,所以信道信息有两种考虑方式:采用7个RAM或是在每个地址存放7个信息。此处采用了后一种方法。也就是vl实际上是56位宽,深度为4096的RAM。 存储设计的另一部分内容是寻址。存储方式和寻址方式均按照总体思路中MATLAB代码进行。即存储顺序是按列进行的,如图 13所示。如果要寻址某一列非零项的取值是很方便的(列数-1),但是寻找每一行则需要一个相应的映射关系了。当然,如果矩阵有(准)循环关系,那么这个过程将容易很多。譬如此处只要知道了第一行的非零项出现在第3列,那么地址为2,第n行地址为n+1(模4)。准循环也有类似的特性。
图 13 存储顺序
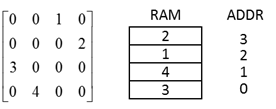
观察MATLAB代码,初始化和变量节点更新过程的地址是顺序的,也就意味着这个过程对应FPGA是RAM地址从0增加到4095的过程。但校验节点更新时采用了rowIndex这一数组。这就是上面说的"需要有一个映射关系"了。最简单的想法是将rowIndex存在一个RAM内,读取即可,但这样太耗资源了。我们注意到这些矩阵都是准循环矩阵(还有对角阵,对角阵行列地址一致,无需考虑),如图 14所示。
图 14 准循环矩阵
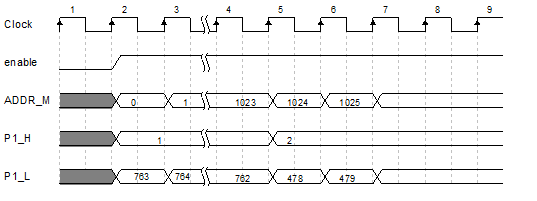
对于如图 14所示的准循环矩阵,首先我们判断非零值出现在哪一小块,之后得到初始地址就能够得出所有的地址了。如图 15所示,P1_H和P1_L共同控制其所处的位置,得到更新所需要的地址。共计有14个准循环矩阵。
图 15 行更新地址产生 |

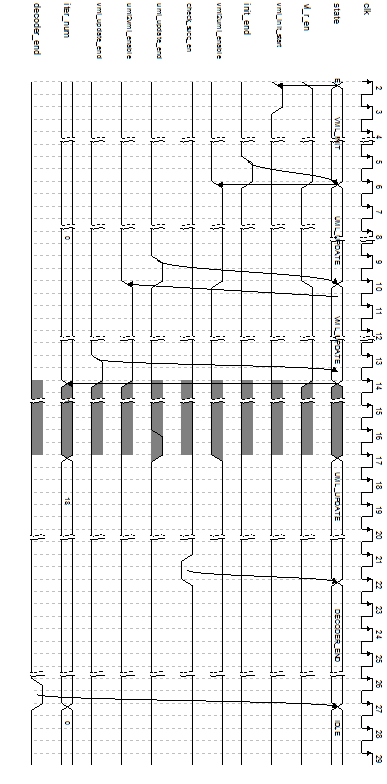
完成了以上工作,那么现在,问题变成了如何将这些模块连接起来,以及如何控制操作的顺序以完成译码工作。 先考虑控制部分,即控制译码状态。译码器至少需要5个状态
图 16 状态控制时序图 如图 16所示,译码器总体控制中采用了多个信号。(注:代码和时序图不同,代码有待修改) 那么,接下来的问题是每一个不同状态下都做了什么?信号之间的延迟关系是什么? VML_INIT
图 17 VML_INIT读写时序图
如图 17所示,状态跳转至VML_INIT时,vl_r_en使能,此时开始读取vl中数据,输出并写入到vml中,待到vml数据写满(此时地址为4095),init_end信号置高,此时结束VML_INIT,跳转到下一个状态。
UML_UPDATE(这里没有考虑校验)
图 18 UML_UPDATE读写时序图
如图 17所示,在UML_UPDATE状态下,vml2uml_enable使能,此时vml2uml_addra开始产生读取地址(即rowIndex)。地址用于读取vml的数据,输出送入计算模块,分别延时4或8周期后写入到uml中。写入uml的地址控制实际上是vml2uml_addra的延时(5或8周期)。当写满时uml_update_end信号置高,进入下一个状态。
CHECKMATRIX 在读取VML数据的同时,VML输出9位中最高位实际上是此处的译码结果(上次迭代)。将其送入到checkmatrix模块中进行校验,如果满足校验方程。信号check_succ_en置低一个周期,状态将跳转至DECODER_END。信号check_succ_en先于uml_update_end响应。(如果达到最大迭代次数,也应该直接跳转到DECODER_END状态,但是现有代码没有写……)
VML_UPDATE VML_UPDATE过程和UML_UPDATE类似,此处不再重复。
DECODER_END 这里执行的操作真是傻呼呼的……读取VML中的译码结果,然后写入到输出译码缓存中。为什么说傻呼呼的呢?因为这里要花约4096个周期才能够完成,既然都有一个专门的输入缓存了,那么实际上在VML_UPDATE中就能够将译码结果写入到缓存区。这样在DECODER_END状态下只需要给出使能或标志信号说明译码结束即可跳转回IDLE状态了。 |
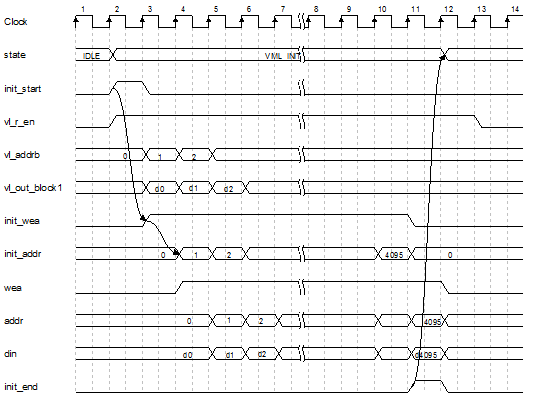


|
点击Synthesize –XST,待XST综合完成后,查看Design Summary/Reports中的Summary和Synthesis Report。Summary中资源消耗(器件使用率)如图 19所示。
图 19 资源消耗
Synthesis Report中则提供了更多的信息,包括上百个的Warnings和Infos。Synthesis Report中目录如下 1) Synthesis Options Summary 2) HDL Compilation 3) Design Hierarchy Analysis 4) HDL Analysis 5) HDL Synthesis 5.1) HDL Synthesis Report 6) Advanced HDL Synthesis 6.1) Advanced HDL Synthesis Report 7) Low Level Synthesis 8) Partition Report 9) Final Report 9.1) Device utilization summary 9.2) Partition Resource Summary 9.3) TIMING REPORT 各部分内容如下所述,具体可参见[7][8]中对应章节。
Synthesis Options Summary 综合过程中的一些选项的总结报告,包括源参数(输入文件,输入格式等),目标参数(输出文件,格式),源设置,目标设置,通用设置,其他设置等。 譬如此处为 ---- Source Parameters Input File Name : "Decoder_top.prj" Input Format : mixed Ignore Synthesis Constraint File : NO
---- Target Parameters Output File Name : "Decoder_top" Output Format : NGC Target Device : xc5vfx130t-2-ff1738 输入工程,输出网表文件(NGC),其他设置保持默认不变。
HDL Compilation & Design Hierarchy Analysis & HDL Analysis 在这三个过程中,XST解析并分析了VHDL或Verilog文件,识别设计的层级,同时给出了编译库的名称(Gives the names of the libraries into which they are compiled)。在这些步骤中,XST可能会报告以下内容 • Potential mismatches between synthesis and simulation results 在本工程中,HDL Analysis报告了以下警告
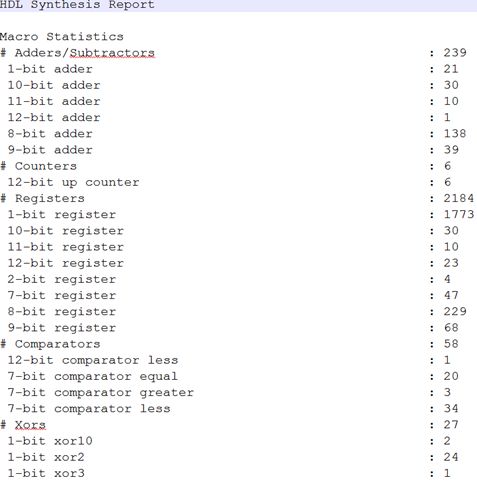
HDL Synthesis 在HDL综合过程中,XST试图识别尽可能多的基本单元(macros)来创建technology-specific implementation。这将会产生一组基本模块,这一步骤结束后,将生成HDL综合报告。 最后提供的HDL Synthesis Report如图 20所示
图 20 HDL Synthesis Report
HDL综合过程中出现的警告有多处信号定义了却没有使用,譬如计算加法后只取了符号,低位没有使用。 同时还提供了一些INFO,包括寄存器被定义为常数,被逻辑单元代替。以及建议INFO:Xst:1767 - HDL ADVISOR - Resource sharing has identified that some arithmetic operations in this design can share the same physical resources for reduced device utilization. For improved clock frequency you may try to disable resource sharing. 由warning和INFO大体也能直销HDL Synthesis过程中XST的操作。
Advanced HDL Synthesis 在这一个过程中,当然进行的是上面HDL Synthesis的高级版本了。XST进行了高级单元识别和推理,包括
工程中恰巧有一个状态机,在Advanced HDL Synthesis中对其进行了格雷编码,如图 21。
图 21 编码状态机
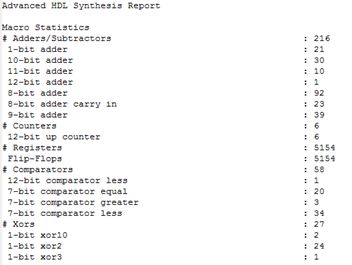
图 22是Advanced HDL Synthesis Report,对比HDL Synthesis Report,差异仅仅出现在Registers项中,即在这一过程中寄存器被划分为了单个的Flip-Flops。引脚没有连接的警告在此处又出现了一遍。(为什么这两个报告要分开?)
图 22 Advanced HDL Synthesis Report
Low Level Synthesis 在这个过程中,XST报告了潜在的替换,譬如
这一部分内容直接观察报告会更容易理解。譬如在读取vml数据时,产生了多个地址,这些地址间可能有潜在的等价关系。这是XST识别出来并对其进行了替换,这种替换产生了一个INFO,如 INFO:Xst:2261 - The FF/Latch <upadte_addr_control/uml_addr_P9_temp_107> in Unit <Decoder_top> is equivalent to the following 3 FFs/Latches, which will be removed : <upadte_addr_control/uml_addr_P6_temp_107> <upadte_addr_control/uml_addr_P5_temp_107> <upadte_addr_control/uml_addr_P2_temp_107> 还有一堆寄存器的报告,大抵就是所说的register replication吧,不过我没怎么看懂。 Partition Report If the design is partitioned, the XST FPGA log file Partition Report contains information detailing the design partitions. 本工程不是,此处略。
Final Report XST的Final Report包括
====================================================================== * Final Report * ====================================================================== Final Results RTL Top Level Output File Name : Decoder_top.ngr Top Level Output File Name : Decoder_top Output Format : NGC Optimization Goal : Speed Keep Hierarchy : No
Design Statistics # IOs : 15
Cell Usage : # BELS : 5140 # GND : 49 # INV : 77 # LUT1 : 75 # LUT2 : 1243 # LUT3 : 376 # LUT4 : 260 # LUT5 : 467 # LUT6 : 646 # MUXCY : 909 # MUXF7 : 28 # VCC : 49 # XORCY : 961 # FlipFlops/Latches : 3102 # FD : 840 # FDE : 604 # FDR : 1428 # FDRE : 191 # FDS : 37 # FDSE : 2 # RAMS : 54 # RAMB18 : 2 # RAMB36_EXP : 52 # Shift Registers : 365 # SRLC16E : 365 # Clock Buffers : 1 # BUFGP : 1 # IO Buffers : 3 # IBUF : 1 # OBUF : 2 ======================================================================
Device utilization summary: ---------------------------
Selected Device : 5vfx130tff1738-2
Slice Logic Utilization: Number of Slice Registers: 3102 out of 81920 3% Number of Slice LUTs: 3509 out of 81920 4% Number used as Logic: 3144 out of 81920 3% Number used as Memory: 365 out of 25280 1% Number used as SRL: 365
Slice Logic Distribution: Number of LUT Flip Flop pairs used: 3762 Number with an unused Flip Flop: 660 out of 3762 17% Number with an unused LUT: 253 out of 3762 6% Number of fully used LUT-FF pairs: 2849 out of 3762 75% Number of unique control sets: 23
IO Utilization: Number of IOs: 15 Number of bonded IOBs: 4 out of 840 0%
Specific Feature Utilization: Number of Block RAM/FIFO: 53 out of 298 17% Number using Block RAM only: 53 Number of BUFG/BUFGCTRLs: 1 out of 32 3%
--------------------------- Partition Resource Summary: ---------------------------
No Partitions were found in this design.
---------------------------
最后单独讨论Timing Report,Timing Report的最开始有这么一条注释 NOTE: THESE TIMING NUMBERS ARE ONLY A SYNTHESIS ESTIMATE. FOR ACCURATE TIMING INFORMATION PLEASE REFER TO THE TRACE REPORT GENERATED AFTER PLACE-and-ROUTE. 也就是说,综合报告的时序报告是不准确的(布线前无法预估路径延时什么的)。按我的理解,这应该是最理想情况下的报告,最终结果会比这里的差,当然这一点暂时没有得到确认。 时序报告首先识别出了时钟信息,之后是异步控制信号信息(应该是异步复位信号,但是本工程里没有异步复位,所有就全部变成GND了,不是太确定)。之后是四个关键数据(不知道第四个是什么) Minimum period: 3.550ns (Maximum Frequency: 281.654MHz) Minimum input arrival time before clock: 3.311ns Maximum output required time after clock: 2.835ns Maximum combinational path delay: No path found 周期约束描述的是寄存器和寄存器之间的关系。由于时钟的偏斜、抖动和寄存器之间的处理时延,使得周期不能无限的小。计算得到的最小周期就是能够正常运行的最小时钟周期。 最小输入到达时间和最大输出需要时间是类似的。弄懂这一点前,我们需要搞清楚OFFSET是什么。时序约束方面可以参考[9],此处也不例外。
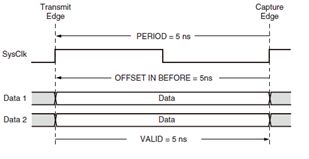
图 23 OFFSET IN示例
OFFSET IN指的是捕获时钟沿到达前数据有效的时间。这是一个约束,而此处的最小到达时间是本工程中输入在被捕获之前需要保持有效的时间。OFFSET OUT与之恰恰相反。Maximum combinational path delay我还不知道是什么。 最后是具体的报告,即限制最大时钟周期的之类的模块是什么。譬如图 24,我们可以根据这里的信息来有针对的调整代码。
图 24 详细报告 |



|
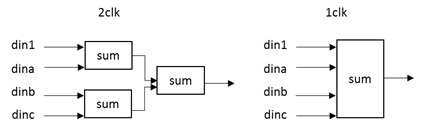
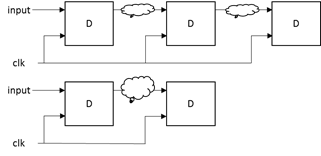
这个标题取得有点太大了,关于时序收敛,Xilinx有一本文档专门讲这个[9],而且我还没太搞明白。这里主要还是谈谈流水线。 上一节观察综合报告中的报告都是修改之后的结果,这里的修改就是加上了一级流水线。这一点在变量节点更新中也有提及。如果不能满足周期约束,可以选择降低时钟频率或是修改代码。流水线就是提高最大运行频率的一种技巧,这一想法实际上也很简单。譬如在做四输入加法的时候
图 25 四输入加法的两种实现方式
两种实现方式功能一样,只不过左侧延时了两个周期,且会多用两个寄存器。如果考虑寄存器之间的操作,如图 26所示,就是将寄存器之间复杂的操作划分为两个较为简单的操作。简单的操作给人的感觉是延时低,自然就提高了时钟频率。
图 26 流水操作
当然,上面的只是一个想法,但是FPGA采用查找表实现各种运算,为何会有不同的延时呢?这个我也不懂……不够我们可以试试两种不同方式实现四输入加法的结果。 注意,为了产生Register to Register Timing,输入要添加寄存器,输出也要有,否则就没有这一条路径了。采用图 25中两种方式,综合报告中的最小时钟周期分别为1.756ns和3.213ns,充分说明了流水线的作用。 包括流水线在内的一系列的编程技巧目的都在于提高工程的处理能力。一个很重要的指标在于工程能否在指定的时序约束上运行,这就是时序收敛。[10]中对时序约束和收敛有些许介绍,但是真正详尽的介绍还是在[9]中。真正要明白的话,除了好好阅读,还需要多练习思考。然而这些我都没有做到。简单的谈谈时序方面的问题。第一是看报告,Timing Report有多个,包括
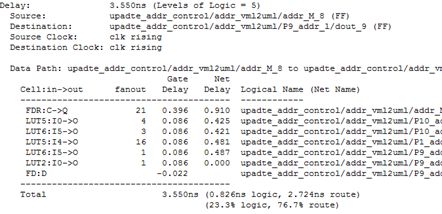
综合报告的时序报告上节已经讨论过了,这里先看看Post-Map Static Timing Report。 首先,报告中列出了时序约束,这里只有一条,即 Timing constraint: TS_clk = PERIOD TIMEGRP "clk" 5 ns HIGH 50%; 之后是各个模块的延时估计(没太看懂),譬如 Paths for end point uml2vml_caculate/block7/stage0_sum2/dinsum_ab_7 (SLICE_X95Y11.CIN), 14 paths -------------------------------------------------------------------------------- Slack (setup path): 0.417ns (requirement - (data path - clock path skew + uncertainty)) Source: vl_control/vlSrotage/U0/xst_blk_mem_generator/gnativebmg.native_blk_mem_gen /valid.cstr/ramloop[0].ram.r/v5_init.ram/SDP.SINGLE_PRIM18.SDP (RAM) Destination: uml2vml_caculate/block7/stage0_sum2/dinsum_ab_7 (FF) Requirement: 5.000ns Data Path Delay: 4.548ns (Levels of Logic = 2) Clock Path Skew: 0.000ns Source Clock: clk_BUFGP rising at 0.000ns Destination Clock: clk_BUFGP rising at 5.000ns Clock Uncertainty: 0.035ns
Clock Uncertainty: 0.035ns ((TSJ^2 + TIJ^2)^1/2 + DJ) / 2 + PE Total System Jitter (TSJ): 0.070ns Total Input Jitter (TIJ): 0.000ns Discrete Jitter (DJ): 0.000ns Phase Error (PE): 0.000ns Slack大于0说明时序约束得到了满足,这是因为。Clock Path Skew是时钟的延时,Clock Uncertainty是时钟的不确定时间,Data Path Delay是数据路径的延时。只要data path - clock path skew + uncertainty小于需要的最小周期,说明时序约束得到了满足。之后还有最大延时的路径详细说明(部分省略) Maximum Data Path: XXXXXX Location Delay type Delay(ns) Physical Resource Logical Resource(s) ------------------------------------------------- ------------------- RAMB36_X7Y13.DOBDOL0 Trcko_DOWB 1.892 XXXXXX XXXXXX SLICE_X95Y10.A5 net (fanout=10) e 2.067 vl_out_block7<0> SLICE_X95Y10.COUT Topcya 0.438 XXXXXX XXXXXX XXXXXX SLICE_X95Y11.CIN net (fanout=1) e 0.000 XXXXXX SLICE_X95Y11.CLK Tcinck 0.151 XXXXXX XXXXXX XXXXXX ------------------------------------------------- --------------------------- Total 4.548ns (2.481ns logic, 2.067ns route) (54.6% logic, 45.4% route) 从这份报告中也可以得到一些修改的建议。譬如高扇出(fanout=10)带来的延时可以通过复制网络来解决等。这部分内容可以参考[9][10]。 Post-PAR Static Timing Report和Post-Map结构基本一致,此处不再说明。 |

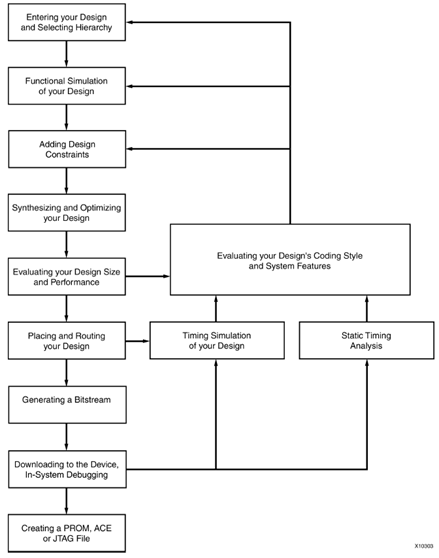
提及FPGA设计,书上多半写的是FPGA Design Flow,对应也会有一幅图,如图 27所示。但是这个框图,展现的更多的是整个操作的流程,包括何时设计,何时优化,何时评估,何时修改一直到下板子调试。但是更重要的问题在于,在编写代码的时候,应该怎么编写,如何修改,对于设计过程中的错误,应该用什么策略去应对? 在讨论这些问题之前,先看看FPGA的代码是怎么样的。如上文所述,FPGA代码被分为了很多不同的模块,最后我们将这些模块组合起来实现了特定的功能。这种设计方法叫做层次设计。FPGA代码也可以写成是扁平的,将所有的功能卸载一个模块内。这两种方法各有优劣[11]。 这两种方法各有优劣,但需要构建的FPGA期间越多(As higher density FPGA devices are created),层次化设计的优点将大大超出其缺点。 层次化设计的优点包括
缺点包括
图 27 设计流程框图
由此看来,要采用FPGA实现一个较为复杂的功能不是一件简单的事情。仅仅从HDL代码编写来看,首先要针对实现的功能设计出合适的层次,之后还要对每一个功能模块进行验证。更为麻烦的是,很多功能和设计是需要反复推敲和修改的,甚至连需求都有改变的可能性。对于这一点来说,FPGA的设计流没有给出合适的解决方案。图 27只告诉我们,不对、不好,回去前面的步骤修改。问题是怎么修改,怎么修改好? 软件工程师对他们的设计策略已经有了深刻的认识。他们意识到自己的程序不可能没有bug,软件的开发流程也比较长,所以有一套不同的策略来应对不同的需求。除了软件功能实现之外,很久以前他们就探讨了如何带领团队在更短的时间内完成高质量的软件设计,并使得软件能够有尽可能长的生命周期。对于这一方面,一本享誉盛名的书是40年前的《人月神话》。 扯了那么多,先了解了解软件开发的设计策略。这里的设计策略,主要指软件开发模型,因为其他的在这里也用不上。常见的开发模型有[12]
开始我觉得,在FPGA程序编写过程中应该算是结合了多种软件开发模型思想吧,因为具有多个模型的特点,直到在网上发现了一个叫做 "Build-and-Fix Model",就是边做边改模型。(百度百科上的,不知道是不是百度百科自创的,WIKI上有一个叫做Code and fix与之类似) 在这个模型中,开发人员拿到项目立即根据需求编写程序,调试通过后生成软件的第一个版本。在提供给用户使用后,如果程序出现错误,或者用户提出新的要求,开发人员重新修改代码,直到用户满意为止。 这是一种类似作坊的开发方式,对编写几百行的小程序来说还不错,但这种方法对任何规模的开发来说都是不能令人满意的,其主要问题在于:
看着主要问题,仔细一想,我就是这样做的好不好。当然,唯一的不同是,近段时间里写的代码最后还是有一个类似文档的东西的,就像我现在所写的东西一样。这个时候回去看看图 27,只有一个评估代码风格和系统特性后回去修改的箭头,而且这个箭头指向了每一个上层模块。可能这就是所谓的设计流吧,不会出错,需求不会改变,只可能性能要有一定的调整。反正我是做不到不会出错的,有的时候代码甚至会推翻重来。 选择一个合适的FPGA开发设计策略不是在我能力范围内的事情,但可以利用下一次机会做出一些尝试。
对于FPGA代码编写来说,可以参考瀑布模型的"文档驱动",即以文档作为一项特定功能完成的标志。但FPGA代码编写完全不需要完成一个步骤后才能够进行下一个步骤,每一个模块都能够单独测试。同时,对于不熟悉的功能实现,可以采用抛弃式策略,测试功能实现,但是这类代码不应该出现在最终程序中。采用增量设计可以使得我们可以有足够的调试空间,但是必须要定义良好的接口,否则就不知道怎么"增"了。软件开发中有更多的思想,包括敏捷开发技术都值得学习,但是现在不涉及到和他人的合作,此处不做说明。 除此之外,模型和他人的经验固然重要,但多尝试、多练习更为实际。另一个可以参考的他人的成果,譬如各个IP核的说明文档/用户指南。 |

整个过程中,我想我犯了很多错误,而且很多错误犯了不止一次。很多经验教训在[5]中就有提及,可是我还是没有引起足够的重视。具体表现如下
这些问题,或许都算不上什么,本文撰写过程中,倒是发现了一个致命的问题——用了太多的"先考虑",却没有"再考虑"。过多的着眼于现在,对未来考虑欠妥或是根本就没有去想过,或许是带来上诉问题的根本原因。 |


从2015年5月3日写到2015年5月8日,将近一个星期,真的是要写吐了。写到现在还不是一个完整的总结。虽然总结、学习和提高很重要,但是快乐和心甘情愿更可贵。这个总结到这里暂停一段时间吧,我想我可能真的要吐了。 |

参考 |
|
