实操:Python爬虫读取豆瓣TOP250生成数据表存储后借助Flask可视化展示
from bs4 import BeautifulSoup
from collections import OrderedDict
import urllib.request
import urllib.error
import re
import xlwt
import sqlite3
class doubanCatch:
def __init__(self,baseurl,head,savepath,complileDict,dbpath):
self.baseurl = baseurl
self.head = head
self.savepath = savepath
self.complileDict = complileDict
self.datalist = []
self.conn = sqlite3.connect(dbpath)
# 1.准备工作
def preWork(self):
#TODO 验证传入的参数是否符合规范,初始化数据啼
return 1
# 2.爬取网页
def askURL(self):
htmls = []
for i in range(10): # 调用获取页面信息的函数
url = self.baseurl + str(i * 25)
request = urllib.request.Request(url,headers=self.head)
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
htmls.append(html)
except urllib.error.URLError as e:
if hasattr(e,'code'):
print('askURL: ',e.code)
if hasattr(e,'reson'):
print('askURL: ',e.reason)
return htmls
# 3.解析网页
def getData(self,html):
soup = BeautifulSoup(html,'html.parser')
for item in soup.find_all('div',class_='item'):
data = OrderedDict()
item = str(item)
#complileDict = {'findLink': findLink, 'findImg': findImg, 'findTitle': findTitle,
# 'findRating': findRating, 'findJudge': findJudge, 'findInq': findInq, 'findBd': findBd}
data['Link'] = re.findall(self.complileDict['findLink'],item)[0]
data['Img'] = re.findall(self.complileDict['findImg'],item)[0]
titles = re.findall(self.complileDict['findTitle'],item)
if len(titles) == 2 :
data['cTitle'] = titles[0]
data['oTitle'] = titles[1].replace('/','')
else:
data['cTitle'] = titles[0]
data['oTitle'] = ' '
data['Rating'] = re.findall(self.complileDict['findRating'],item)[0]
data['Judge'] = re.findall(self.complileDict['findJudge'], item)[0]
inqs = re.findall(self.complileDict['findInq'], item)
if len(inqs) != 0:
data['Inq'] = inqs[0].replace('.','')
else:
data['Inq'] = ' '
bd = re.findall(self.complileDict['findBd'], item)[0]
bd = re.sub(' findImg = re.compile(r'
findImg = re.compile(r'肖申克的救赎
findTitle = re.compile(r'(.*)')
#
findRating = re.compile(r'')
#2147325人评价
findJudge = re.compile(r'(\d*)人评价')
#希望让人自由。
findInq = re.compile(r'(.*?)')
#
# 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
# 1994 / 美国 / 犯罪 剧情
#
findBd = re.compile(r'(.*?)
',re.S)
#正则匹配字典构造
complileDict= {'findLink':findLink,'findImg':findImg,'findTitle':findTitle,'findRating':findRating,'findJudge':findJudge,'findInq':findInq,'findBd':findBd}
try:
d = doubanCatch(baseurl,head,savepath,complileDict,dbpath)
d.run()
except Exception as e:
print('main: ',e)
finally:
pass
由于run调用了存储数据在Excel和SQLite所以如下检查:


查看SQLite数据库是否存储数据

查看Excel文件是否存储数据

有了数据就可以做分析了
from flask import Flask,render_template
import sqlite3
import jieba
from matplotlib import pyplot as plt
from wordcloud import WordCloud
import numpy as np
from PIL import Image
import threading
app = Flask(__name__)
@app.route('/')
def root():
return render_template('temp.html')
@app.route('/index')
def index():
return render_template('index.html')
@app.route('/movie')
def movie():
datalist = []
con = sqlite3.connect('douban.db')
cur = con.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
datalist.append(item)
cur.close()
con.close()
return render_template('movie.html',movies=datalist)
@app.route('/word')
def word():
def wordcloud():
con = sqlite3.connect('douban.db')
cur = con.cursor()
sql = "select instroduction from movie250"
data = cur.execute(sql)
text = ''
for item in data:
text += item[0]
cur.close()
con.close()
cut = jieba.cut(text)
string = ' '.join(cut)
img = Image.open(r'./static/assets/img/tree.jpg')
img_array = np.array(img)
wc = WordCloud(
background_color='white',
mask = img_array,
font_path='/home/yzx/PycharmProjects/douban_flask/templates/MSYH.TTF'
)
wc.generate_from_text(string)
#绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off')
plt.show()
# plt.savefig('./static/assets/img/word.jpg',dpi=500)
t = threading.Thread(target=wordcloud,name='wordcloud',daemon=True)
t.start()
return render_template('word.html')
@app.route('/team')
def team():
return render_template('team.html')
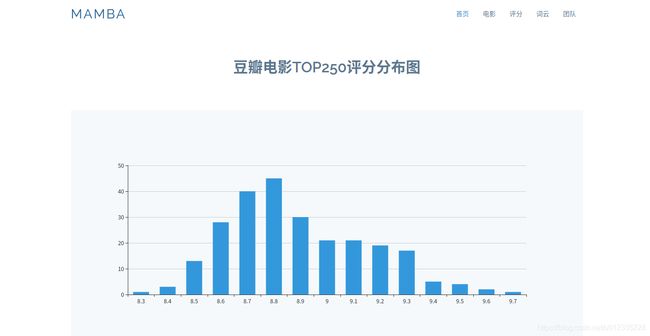
@app.route('/score')
def score():
score = []
count = []
con = sqlite3.connect('douban.db')
cur = con.cursor()
sql = "select score,count(score) from movie250 group by score"
data = cur.execute(sql)
for item in data:
score.append(item[0])
count.append(item[1])
cur.close()
con.close()
return render_template('score.html',score=score,count=count)
if __name__ == '__main__' :
app.run()
index.html
Mamba Bootstrap Template - Index
movie.html
Mamba Bootstrap Template - Index
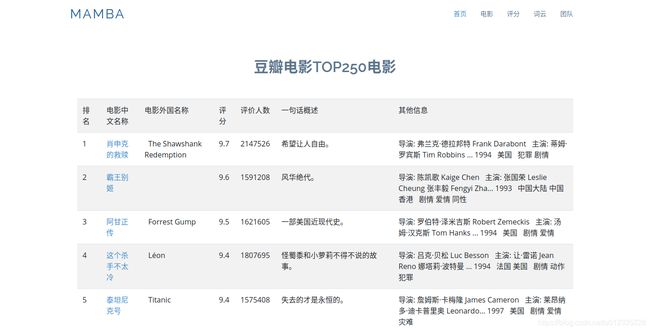
豆瓣电影TOP250电影
排名
电影中文名称
电影外国名称
评分
评价人数
一句话概述
其他信息
{% for movie in movies %}
{
{ movie[0] }}
{
{ movie[3] }}
{
{ movie[4] }}
{
{ movie[5] }}
{
{ movie[6] }}
{
{ movie[7] }}
{
{ movie[8] }}
{% endfor %}
score.html
Mamba Bootstrap Template - Index
豆瓣电影TOP250评分分布图
word.html
Mamba Bootstrap Template - Index

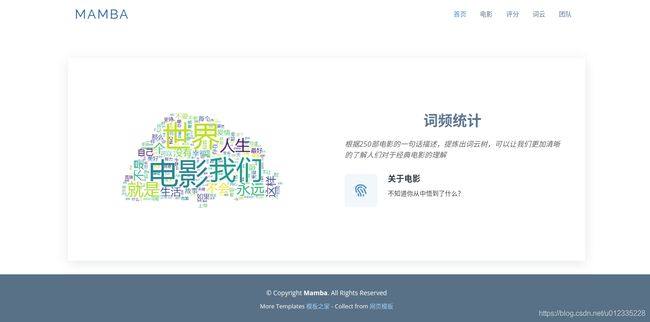
词频统计
根据250部电影的一句话描述,提炼出词云树,可以让我们更加清晰的了解人们对于经典电影的理解
team.html
Mamba Bootstrap Template - Index
我们的团队

Walter White
Chief Executive Officer

Sarah Jhonson
Product Manager

William Anderson
CTO

Amanda Jepson
Accountant
使用的模板文件
Mamba Bootstrap Template - Index
[email protected]
+1 5589 55488 55
About Us
Magnam dolores commodi suscipit. Necessitatibus eius consequatur ex aliquid fuga eum quidem. Sit sint consectetur velit. Quisquam quos quisquam cupiditate. Et nemo qui impedit suscipit alias ea.
Lorem Ipsum
Voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident
Nemo Enim
At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque
Collect from 网站模板
01
Lorem Ipsum
Ulamco laboris nisi ut aliquip ex ea commodo consequat. Et consectetur ducimus vero placeat
02
Repellat Nihil
Dolorem est fugiat occaecati voluptate velit esse. Dicta veritatis dolor quod et vel dire leno para dest
03
Ad ad velit qui
Molestiae officiis omnis illo asperiores. Aut doloribus vitae sunt debitis quo vel nam quis
04
Repellendus molestiae
Inventore quo sint a sint rerum. Distinctio blanditiis deserunt quod soluta quod nam mider lando casa
05
Sapiente Magnam
Vitae dolorem in deleniti ipsum omnis tempore voluptatem. Qui possimus est repellendus est quibusdam
06
Facilis Impedit
Quis eum numquam veniam ea voluptatibus voluptas. Excepturi aut nostrum repudiandae voluptatibus corporis sequi
232
Happy Clients
521
Projects
1,463
Hours Of Support
15
Hard Workers
Services
Lorem Ipsum
Voluptatum deleniti atque corrupti quos dolores et quas molestias excepturi sint occaecati cupiditate non provident
Dolor Sitema
Minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat tarad limino ata
Sed ut perspiciatis
Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur
Magni Dolores
Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum
Nemo Enim
At vero eos et accusamus et iusto odio dignissimos ducimus qui blanditiis praesentium voluptatum deleniti atque
Eiusmod Tempor
Et harum quidem rerum facilis est et expedita distinctio. Nam libero tempore, cum soluta nobis est eligendi
Our Portfolio
Magnam dolores commodi suscipit. Necessitatibus eius consequatur ex aliquid fuga eum quidem. Sit sint consectetur velit. Quisquam quos quisquam cupiditate. Et nemo qui impedit suscipit alias ea. Quia fugiat sit in iste officiis commodi quidem hic quas.
- All
- App
- Card
- Web
Our Team
Magnam dolores commodi suscipit. Necessitatibus eius consequatur ex aliquid fuga eum quidem.
Walter White
Chief Executive Officer
Sarah Jhonson
Product Manager
William Anderson
CTO
Amanda Jepson
Accountant
Frequently Asked Questions
Non consectetur a erat nam at lectus urna duis?
Feugiat pretium nibh ipsum consequat. Tempus iaculis urna id volutpat lacus laoreet non curabitur gravida. Venenatis lectus magna fringilla urna porttitor rhoncus dolor purus non.
Feugiat scelerisque varius morbi enim nunc faucibus a pellentesque?
Dolor sit amet consectetur adipiscing elit pellentesque habitant morbi. Id interdum velit laoreet id donec ultrices. Fringilla phasellus faucibus scelerisque eleifend donec pretium. Est pellentesque elit ullamcorper dignissim.
Dolor sit amet consectetur adipiscing elit pellentesque habitant morbi?
Eleifend mi in nulla posuere sollicitudin aliquam ultrices sagittis orci. Faucibus pulvinar elementum integer enim. Sem nulla pharetra diam sit amet nisl suscipit. Rutrum tellus pellentesque eu tincidunt. Lectus urna duis convallis convallis tellus.
Ac odio tempor orci dapibus. Aliquam eleifend mi in nulla?
Dolor sit amet consectetur adipiscing elit pellentesque habitant morbi. Id interdum velit laoreet id donec ultrices. Fringilla phasellus faucibus scelerisque eleifend donec pretium. Est pellentesque elit ullamcorper dignissim.
Tempus quam pellentesque nec nam aliquam sem et tortor consequat?
Molestie a iaculis at erat pellentesque adipiscing commodo. Dignissim suspendisse in est ante in. Nunc vel risus commodo viverra maecenas accumsan. Sit amet nisl suscipit adipiscing bibendum est. Purus gravida quis blandit turpis cursus in
Tortor vitae purus faucibus ornare. Varius vel pharetra vel turpis nunc eget lorem dolor?
Laoreet sit amet cursus sit amet dictum sit amet justo. Mauris vitae ultricies leo integer malesuada nunc vel. Tincidunt eget nullam non nisi est sit amet. Turpis nunc eget lorem dolor sed. Ut venenatis tellus in metus vulputate eu scelerisque.
Contact Us
Our Address
A108 Adam Street, New York, NY 535022
Email Us
Call Us
+1 5589 55488 55
+1 6678 254445 41










效果图展示