Python-数据预处理
1、缺失数据处理:存在缺失值的特征或者样本删除,均值替换缺失值
import pandas as pd
from io import StringIO #StringIO字符串的缓存
csv_data = ''' A,B,C,D
1.0,2.0,3.0,4.0
5.0,6.0,,8.0
0.0,11.0,12.0,'''
df=pd.read_csv(StringIO(csv_data))
df.isnull().sum() #计算空值的个数
df.values
原数据和每列的缺失值个数


#删除缺失值
df.dropna() #行
df.dropna(axis=1) #竖列
df.dropna(how='all') #删除所有列是NAN
df.dropna(thresh=4) #删除一行最少4个非NA的列
df.dropna(subset=['C']) #删除C列有NA的行
#缺失值均值填充
from sklearn.preprocessing import Imputer
imr=Imputer(missing_values='NaN',strategy='mean',axis=1) #axis=1每行均值替换 axis=0每列均值替换。strategy可选项median或most_frequent
imr=imr.fit(df)
imputed_data=imr.transform(df.values)
imputed_data

2、处理类别数据–标称特征(如颜色红、黄、蓝)和有序特征(如尺码XL>L>M)
import pandas as pd
df= pd.DataFrame([['green','M',10.1,'class1'],
['red','L',13.5,'class2'],
['blue','XL',15.3,'class3']
])
df.columns =['color','size','price','classlabel']
df

size_mapping ={
'XL':3,
'L':2,
'M':1}
df['size']=df['size'].map(size_mapping)
df
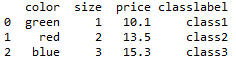
import numpy as np
class_mapping ={label:idx for idx,label in enumerate(np.unique(df['classlabel']))}
class_mapping
df['classlabel'] = df['classlabel'].map(class_mapping)

inv_class_mapping = {v:k for k,v in class_mapping.items()}
df['classlabel'] = df['classlabel'].map(inv_class_mapping)
df

from sklearn.preprocessing import LabelEncoder #LabelEncoder 类更方便完成对类标的整数编码
class_le = LabelEncoder()
y = class_le.fit_transform(df['classlabel'].values)
y
class_le.inverse_transform(y) #inverse_transform将整数类标还原为原始的字符串
![]()
![]()
#使用LabelEncoder类将字符串类标转换为整数
X=df[['color','size','price']].values
color_le = LabelEncoder()
X[:,0] =color_le.fit_transform(X[:,0])
X
![]()
#上述方法假定blue=0 green=1 red=2,在学习算法时可能会假定red>green>bule,这个假定显然不太合理。
#如下为解决方案,标称特征上的独热编码技术。理念:创建一个新的虚拟特征,虚拟特征每一列各代表标称数据的一个值。使用二进制值标识值,blue=1 green=0 red=0
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(categorical_features=[0])
ohe.fit_transform(X).toarray()
pd.get_dummies(df[['price','color','size']]) #get_dumnies只对字符串进行转换

#为避免共线性问题,降低变量间的相关性,删除one-hot数组中特征值的第一列
pd.get_dummies(df[['size','color','price']],drop_first = True)
3、将数据集分为训练数据集和测试数据集
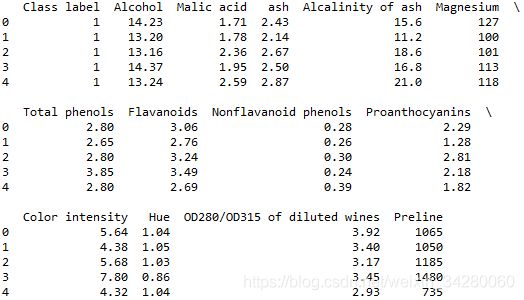
df_wine = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns= ['Class label','Alcohol',
'Malic acid','ash',
'Alcalinity of ash','Magnesium',
'Total phenols','Flavanoids',
'Nonflavanoid phenols',
'Proanthocyanins',
'Color intensity','Hue',
'OD280/OD315 of diluted wines',
'Preline']
print('Class label',np.unique(df_wine['Class label']))
df_wine.head()
#将数据集划分为训练数据集和测试数据集
from sklearn.cross_validation import train_test_split
x,y = df_wine.iloc[:,1:].values,df_wine.iloc[:,0].values #第一列赋值给y,1-13个特征值赋值给X
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=0) #30%划为test 70%为train
4、特征值缩放
#将特征额值缩放到相同的区间:例如一个样本区间为1-100,另一个为1-10000,可通过归一化l和标准化解决这个问题
#归一化 (x-min(x))/(max(x)-min(x))
from sklearn.preprocessing import MinMaxScaler
mms=MinMaxScaler()
X_train_norm = mms.fit_transform(x_train)
X_test_norm = mms.transform(x_test)
#标准化 (x-均值)/标准差
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
x_train_std = stdsc.fit_transform(x_train)
x_test_std = stdsc.transform(x_test)
5、选择有意义的特征
过拟合是指模型参数对于训练数据集的特定观测值拟合的非常接近,但训练数据集的分布与真实数据并不一致–我们称之为模型具有较高方差
常用的降低泛化误差的方案:1、收集更多的训练数据(难以实现) 2、通过正则化引入罚项 3、选择一个参数相对较小的模型 4、降低数据维度

#L1正则化满足数据稀疏化
from sklearn.linear_model import LogisticRegression
LogisticRegression(penalty='l1')
lr = LogisticRegression(penalty='l1',C=0.1)
lr.fit(x_train_std,y_train)
print('training accuracy:',lr.score(x_train_std,y_train)) #training accuracy: 0.983870967742
print('test accuracy:',lr.score(x_test_std,y_test)) #test accuracy: 0.981481481481
lr.intercept_ #array([-0.38381257, -0.15806046, -0.70042228])
lr.coef_

训练和测试的精确度均为98%,显示此模型未出现过拟合。lr.intercept_属性得到截距项为包含三个数值的数组。
lr.coef_包含13个权重值()如上图),通过与13维的葡萄酒数据集中的特征数据相乘计算模型净输入:z=w1x1+W2X2+…X13*X13
如下展示将权重系数(正则化参数)应用于多个特征上时所产生的不同的正则化效果
import matplotlib.pyplot as plt
fig = plt.figure()
ax = plt.subplot(111)
colors=['blue','green','red','cyan','magenta','yellow','black','pink','lightgreen','lightblue','gray','indigo','orange']
weights,params = [], []
for c in np.arange(-4, 6):
lr = LogisticRegression(penalty='l1',C=10**c,random_state=0)
lr.fit(x_train_std,y_train)
weights.append(lr.coef_[1])
params.append(10**c)
weights = np.array(weights)
for column,color in zip(range(weights.shape[1]),colors):
plt.plot(params,weights[:,column],label=df_wine.columns[column+1],color=color)
plt.axhline(0,color='black',linestyle='--',linewidth=3)
plt.xlim([10**(-5),10**5])
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.xscale('log')
plt.legend(loc='upper left')
ax.legend(loc='upper cenrer',bbox_to_anchor=(1.38,1.03),ncol=1,fancybox=True)
plt.show()
在强的正则化参数(C<0.1)作用下,罚项使得所有特征权重都趋近于0,C是正则化参数的倒数。
【序列特征选择算法】:是一种贪婪搜索算法,用于将原始的d维特征空间压缩到一个K维特征子空间,其中k
步骤 1、设k=d 进行算法初始化,其中d是特征空间xd的维度。 2、定义X为满足标准X=argmaxJ(Xk-x)最大化的特征,其中X属于Xk. 3、将特征值从特征集删除 4、如果K等于目标特征数量,算法终止,否则跳到第2步。
from sklearn.base import clone
from itertools import combinations
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score #accuracy_score去衡量分类器的模型和评估器在特征空间上的性能
class SBS():
def __init__ (self,estimator,k_features,scoring=accuracy_score,test_size =0.25,random_state=1):
self.scoring =scoring
self.estimator = clone(estimator)
self.k_features = k_features
self.test_size = test_size
self.random_state = random_state
#在fit方法的循环中,通过itertools.combinatio函数创建子集循环地进行评估和删减,直到特征子集达到预期维度。
def fit(self,x,y):
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=self.test_size,random_state=self.random_state)
dim = x_train.shape[1]
self.indices_ = tuple(range(dim))
self.subsets_ = [self.indices_]
score = self._calc_score(x_train,y_train,x_test,y_test,self.indices_)
self.scores_ = [score]
while dim > self.k_features:
scores = []
subsets = []
for p in combinations(self.indices_,r=dim-1):
score = self._calc_score(x_train,y_train,x_test,y_test,p)
scores.append(score)
subsets.append(p)
best = np.argmax(scores)
self.indices_ = subsets[best]
self.subsets_.append(self.indices_)
dim -= 1
self.scores_.append(scores[best])
self.k_score_ =self.scores_[-1]
return self
def transform(self,x):
return x[:,self.indices_]
def _calc_score(self,x_train,y_train,x_test,y_test,indices):
self.estimator.fit(x_train[:,indices],y_train)
y_pred = self.estimator.predict(x_test[:,indices])
score = self.scoring(y_test,y_pred)
return score
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
knn = KNeighborsClassifier(n_neighbors=2)
sbs = SBS(knn,k_features=1)
sbs.fit(x_train_std,y_train)
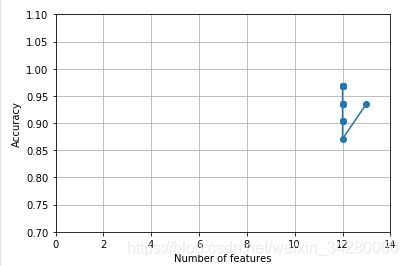
k_feat = [len(k) for k in sbs.subsets_]
plt.plot(k_feat,sbs.scores_,marker='o')
plt.ylim([0.7,1.1])
plt.xlim([0,14])
plt.ylabel('Accuracy')
plt.xlabel('Number of features')
plt.grid()
plt.show()
SBS的fit方法将建立一个新的训练自己用于测试(验证)和训练。这也是一种避免原始测试数据集变成训练数据集的必要方法。
绘制KNN分类器的分类准确率,准确率数值如下:(代码貌似还有问题)
k5 = list(sbs.subsets_[8])
print(df_wine.columns[1:][k5])
红色的五个特征在验证数据集上表现很好

knn.fit(x_train_std,y_train)
print('Training accuracy:',knn.score(x_test_std,y_test)) #Training accuracy: 0.944444444444
knn.fit(x_train_std[:,k5],y_train)
print('Training accuracy:',knn.score(x_train_std[:,k5],y_train)) #Training accuracy: 0.967741935484
print('Test accuracy:',knn.score(x_train_std[:,k5],y_train)) #Test accuracy: 0.967741935484
当特征数量不及葡萄酒一半的时候,在测试集上的预测准确率高了2个百分点。通过测试和训练数据集上准确率的细微差别可以看到过拟合现象得以缓解。
6、随机森林判定特征的重要性
from sklearn.ensemble import RandomForestClassifier
feat_labels = df_wine.columns[1:]
forest = RandomForestClassifier(n_estimators=10000,random_state=0,n_jobs=-1)
forest.fit(x_train,y_train)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1,30,feat_labels[f],importances[indices[f]]))
plt.title('Feature Impartances')
plt.bar(range(x_train.shape[1]),importances[indices],color='lightblue',align='center')
plt.xticks(range(x_train.shape[1]),feat_labels,rotation=90)
plt.xlim([-1,x_train.shape[1]])
plt.tight_layout()
plt.show()
x_selected = forest.transform(x_train,threshold=0.15)
x_selected.shape

在葡萄酒数据集上训练10000颗树,分别根据重要程度对13个特征给出重要性等级。这些特征经过归一化处理。由直方图可以看出Alcohol最具判别效果
x_selected = forest.transform(x_train,threshold=0.15)
x_selected.shape #(124, 3)
将阈值设为0.15,可以将数据集压缩到最重要的特征: