上周,涛思数据与EMQ在线上Meetup上联合发布了工业互联网一体化解决方案,基于TDengine、EMQ X搭建一个集工业数据采集、汇聚、清洗、存储分析以及可视化展示等能力于一体的轻量级边缘计算工业互联网平台。目前TDengine已经全面支持ARM 32和ARM 64处理器,那么为什么,TDengine是边缘侧数据更高效的存储选择?它比SQLite好在哪里?在Meetup上,涛思数据联合创始人侯江燚分享了这背后的技术原理。
从互联网到移动互联网再到现在我们的物联网,计算机、移动终端、可穿戴设备、汽车、甚至家里的灯以及工厂里各种设备都已经接入网络。整体来说,各种各样的设备不断地采集实时状态数据,再把这个数据汇集到云端的一个计算平台,这是物联网云计算的大概思路。
整个物联网技术链有4层结构:通过传感器采集设备的状态数据 -> 通过通讯模组将数据发往云端 -> 在云端进行存储、查询和计算 -> 最后接入分析及应用系统。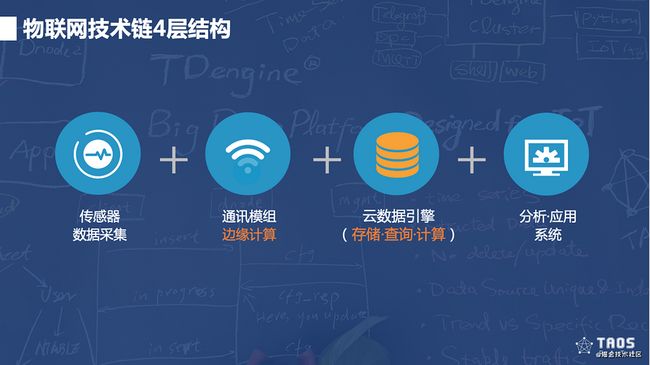
然而,在云计算模式中,数据必须要传到云上进行集中式的存储、归档及分析等。边缘侧的节点可能是一个网关,也可能是我们真正使用的一个终端。如果它没有自身的计算能力,必须把采集的数据发给云端,依托云端计算资源进行复杂的计算,得到一个指导性的结论,再通过网络下发给终端。很容易看出,这个过程中终端的工作非常依赖于网络。如果网络一旦出现一些中断或故障的话,终端无法与云端进行交互,其某些工作就会大受影响。因此这种中心侧(云端)主控的思路,对边云之间的通信要求非常高,应用起来往往要使用高成本的高速通信网络。从另一个层面说,随着数据量不断增长,云端的存储成本和计算成本也会不断升高。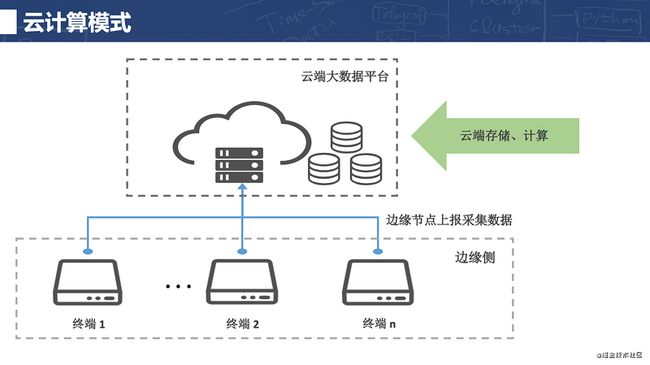
解决这个问题的一个很好的思路就是边缘计算,即把一部分的存储和计算的能力下沉到边缘侧(即设备侧),终端设备较独立地进行数据存储、计算、决策和应用。这样边缘侧就变得更智能,对云端依赖更小,数据处理的时效性也更高,且不再受网络影响。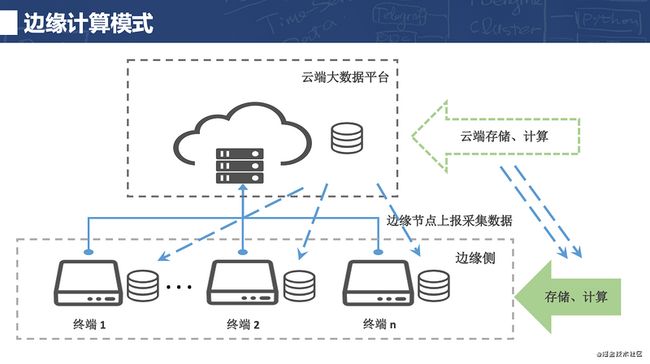
边缘计算带来的优势简单总结如下。
然而边缘计算目前有什么困难还没解决呢?我们知道,边缘侧往往是一些能够大量铺设的小型智能终端,处于成本考虑,其配置的内存、CPU等硬件资源和计算能力都很有限。边缘计算的难点就在于能否在有限的计算资源下,实现最高效的数据存储、分析和计算。这就让边缘侧的数据库选择显得尤为重要。边缘侧的终端设备采集的数据有很明显的特征,一般都是带有时间戳的、结构化的时序数据流。因此边缘计算对数据库能力的要求就反映在以下几个方面:
- 超高读写性能
- 低硬件开销
- 通用接口,适配边缘侧多样计算需求
- 实时数据的缓存能力、流式计算能力
- 历史数据持久化存储、高效压缩能力
- 历史数据回溯能力、按时间窗口的统计聚合能力
- 云边协同能力
TDengine——更适合边缘侧的大数据引擎
时序数据库是具备上述各项能力的,也是边缘侧采集数据存储的最佳选择。但如OpenTSDB(底层基于HBase改造)、InfluxDB等时序数据库对于边缘侧来说还是太重了,运行起来的硬件资源开销过高。一个极轻量化的开源时序数据库就是TDengine,整个安装包只有2MB多。其核心功能是一个高性能分布式时序数据库;除此之外,还自带了消息队列、缓存、流式计算、数据订阅等功能,为时序结构化数据存储提供一个All-in-One的解决方案。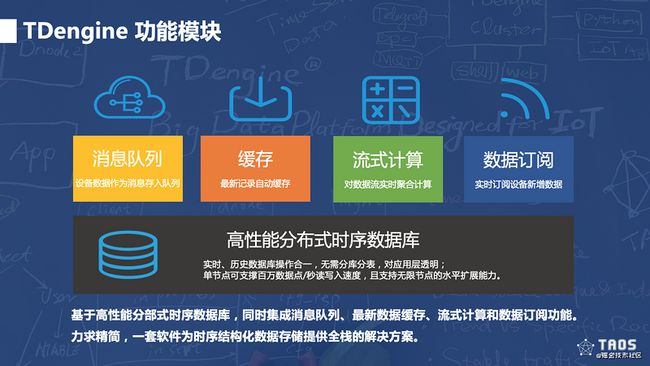
目前TDengine社区已经发布了支持ARM32和ARM64处理器的版本,可以顺畅地运行在树莓派等主流的边缘侧硬件上,同时提供对实时数据的缓存、历史数据回溯、按时间段聚合计算等多种能力。虽然在边缘侧用到分布式集群的概率比较小,但如果哪几个树莓派、盒子或网关想要搭建一个集群,也是完全可以的。
TDengine ARM版本支持的接口也有很多种,与正常集群版几乎没有区别。同时,还提供了一个 taos shell客户端,让调试人员可以方便地去查看TDengine的运行状态。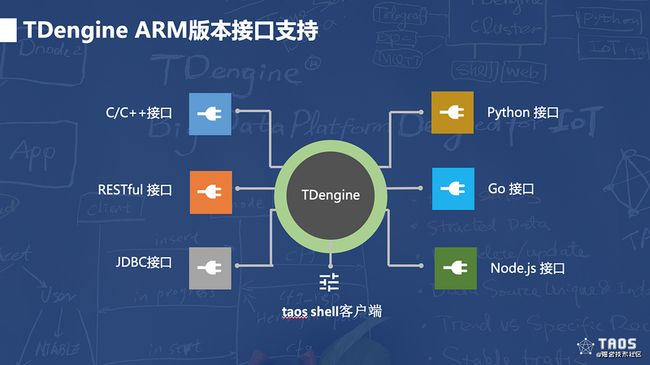
TDengine 边云协同思路
边缘侧资源有限,能存储的数据总量也是有限的,因此还是要向云端做数据备份和协同。边云协同思路也有很多,这里讲一下我们的一些思路。
举个例子方便大家更好的理解。边缘侧厂区有很多网关,我们可以在每个网关里都装一个TDengine的边缘侧版本,那么TDengine就成为边缘侧的一个存储引擎,可以把网关采集到的数据持久化存储。取决于数据采集频率和压缩情况,边缘侧可以根据现有的存储资源选择性存储一定时间长度的原始数据(比如一个月到半年等)。对于整型或者浮点型数据,TDengine可以将其压缩到原来的10%左右,当然这个取决于具体的数据类型,如果数据的值随机变化非常大,这个压缩比确实会受一定影响,但整体来讲,从实际情况来看,压缩比还是在10%左右。因此,如果我们在网关里配一个2GB甚至1GB的SD卡的话,大概可以存储10GB的原始数据量。这个量级对边缘侧实时分析来说已经足够。
然而如果需要存储更久的历史数据,进一步做大数据挖掘等分析,则要把数据同步到云端数据中心存储。TDengine边缘侧的版本可以被云端的TDengine客户端直接访问(网络畅通情况下),因此从边到云的数据同步变得非常简单。云端的应用程序可以通过TDengine的订阅模块实时拉取边缘侧网关中的最新数据,再把收到增量数据实时写入本地TDengine集群做历史归档。这个技术实现上,本质是一个定时查询,因此TDengine允许用户添加一些数据筛选条件,有选择性地同步边缘侧的数据(比如只拉取采集之大于某个阈值的记录,没有就不要),而不用把所有的历史数据都上报给云端。
基于TDengine在边缘侧的存储优势以及边云协同的整体思路,涛思数据和EMQ也联合做了一个边缘侧的解决方案。简单来说,边缘侧网关中部署EMQ X Neuron、EMQ X Edge和EMQ X Kuiper以及TDengine,将设备采集的流式数据通过Neuron做协议解析转换成MQTT消息,然后发布Edge(边缘侧MQTT Broker),再通过Kuiper存入在边缘部署的 TDengine 中。这样在边缘端运行的应用即可从 TDengine 中获取和处理数据,做实时显示和报警。EMQ 在边缘端运行的 Edge Manager 提供了一个管理控制台,可以很方便地实现软件配置和管理其他三个组件。点击「这里」,详细了解该方案的配置方法。这种方案相当于把协调的工作交给了EMQ。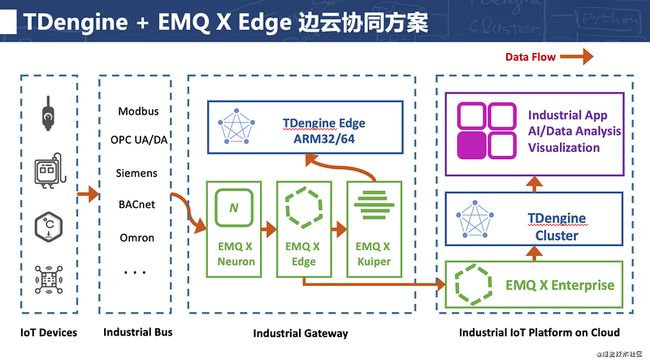
但也可能有的用户已经在云端用了TDengine的集群,现在也有一些工业设备,想直接通过TDengine Cluster客户端直接去访问边缘侧的TDengine。这种也可以通过TDengine的数据订阅的模块直接实现,即云端的应用调用数据订阅模块创建一系列的订阅任务,直接去实时拉取边缘侧TDengine中的最新增量数据。这种方案相当于把协同的工作又交给了TDengine,当然这里要保证网络是畅通的。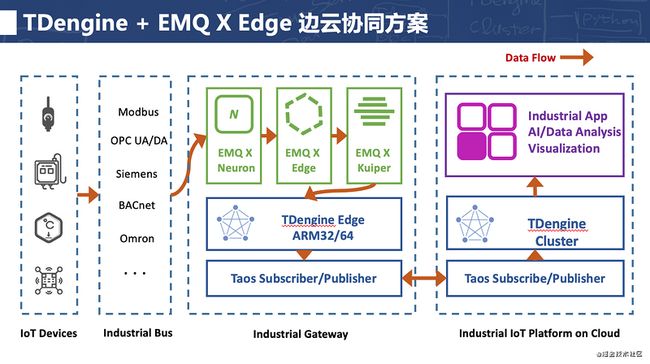
TDengine边缘版本在树莓派上的编译
下面也简单介绍一下在树莓派上编译、安装、运行TDengine的实战步骤。
环境准备
1. 烧录操作系统
烧制操作系统到SD卡。TDengine支持Ubuntu16.04、CentOS7.0及以上等主流操作系统。
2. 网络设置
配置树莓派上的网络环境,为开发版设置静态IP和hostname等,并连接到网络。
3. 下载编译TDengine
从www.github.com/taosdata/TDengine 克隆TDengine源码到树莓派,编译并运行。
编译过程
# clone source code
$ git clone --recursive --recurse-submodules https://github.com/taosdata/TDengine.git
# checkout to the latest version
$ cd TDengine/
$ git checkout ver-2.0.7.0
# compile and install
$ mkdir build && cd build
$ cmake ../ -DCPUTYPE=aarch64 -DVERNUMBER=2.0.7.0 -DVERCOMPATIBLE=2.0.0.0
$ make && make install
# start taosd
$ systemctl start taosd
$ taosdemo编译安装完成后,就可以看到我们提供的taosdemo程序,方便大家进行极速体验。大家可以通过taosdemo来测试一下TDengine的数据写入和查询效率。
TDengine与SQLite的简单比较
边缘侧、嵌入式设备中的数据存储不得不提SQLite。SQLite是一个不需要后台的超轻量级数据库,可谓即插即用,也是世界上装机量最高的数据库。SQLite甚至在官网上将自己定位与fopen()对标,而不是数据库:Think of SQLite not as a replacement for Oracle but as a replacement for fopen() SQLite is a compact library. 当然,SQLite提供的一系列API都是对标关系型数据库的,它甚至还支持了事务,因此业界常常把它用作嵌入式关系型数据库。
两者相对比一下,SQLite在Linux上的安装包为1.9MB,TDengine为2.7MB。两者都是把轻量化做到极致。由于TDengine是专门针对时序结构化数据的一种方案,不支持事务和复杂的表关系处理,但会提供时序数据的时间索引、实时流计算、列式存储及更好的压缩比、按照时间的降采样聚合能力、数据保存时限等。从这个角度来说,TDengine要比SQLite更贴近边缘侧生产环境中对时序数据的处理需求。TDengine边缘侧版本也可以做到云端的产品无缝对接,如果网络不畅,TDengine可以实现数据自动缓存,联网后自动续传,实现边云协同的能力。下面用一张图来简单总结下TDengine和SQLite的区别。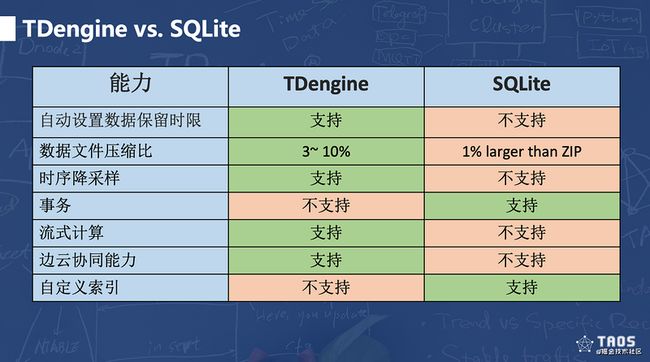
作为新兴的时序数据库代表,TDengine的诸多优点,在边缘侧的存储选择上着实挑战到了一代宗师SQLite,倒真有点年轻人不讲武德啊。但需要认识到的一点,TDengine和SQLite要处理的问题侧重点不同,两者并非必须取舍,而是可以根据自己的业务需求,灵活搭配使用,由TDengine处理时序数据,由SQLite处理关系数据,更好地实现边缘侧的数据自治。
关注公众号“TDengine”,后台回复“1117”,获取PPT完整版