带你用Python爬取豆瓣电影Top250
刚开始使用python爬取网页信息的小伙伴一般都会利用爬取豆瓣电影Top250来作为自己的一个基础实战项目,接下来我将使用基础的爬虫库演示一下这个案例。
项目分析
这个项目我们需要的库有:requests库,BeautifulSoup库,openpyxl库
我们首先打开豆瓣电影top100查看一下网页的结构


可以看到每页的电影共有25个总共10页,这样我们就有了我们的总体思路,首先我们解析网页,可以得到页面各个电影的信息,然后通过翻页获取下一个页面的url继续第一页的操作,最后写入到excel中。
现在我们知道我们要解决的问题有个:第一获取每个电影信息,第二实现翻页,第三excel的读写。
下面我们一步一步解决我们的问题
- 要获取每个电影的信息,我们来查看一下网页的源代码
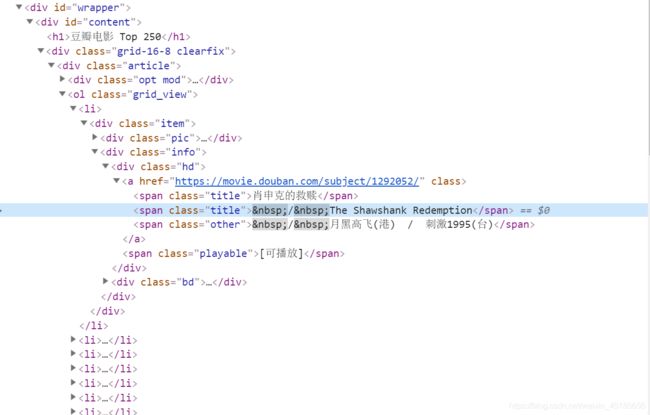
可以看到每个电影的信息都存在‘li’标签中,每个电影标题,详细页url,评分等信息都可以读取,接下来我们会用BeautifulSoup库进行网页解析与信息读取
2. 第二实现翻页
我们进行翻页可以看到1,2,3的url为
https://movie.douban.com/top250
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=这样我们很容易找到规律进行翻页操作
3. excel的读写
我们使用openpyxl库,openpyxl是一个用来读写Excel 2010 xlsx/xlsm 文件的Python库。文档地址[openpyxl官方文档](https://openpyxl.readthedocs.io/en/default/)
我们只要使用其中的append方法向其中添加信息。
代码编写
导入库
import requests
from bs4 import BeautifulSoup
import openpyxl我们的主体框架

进行网页请求
def getHTMLtext(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
try:
r = requests.get(url=url, headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print('访问失败')网页解析获取数据
def parseHTMLtext(html,name_list,info_list):
soup=BeautifulSoup(html,'html.parser')
li=soup.find('ol',class_="grid_view").find_all('li')
# print(li)
for info in li:
name_list.append(info.find('span',class_='title').string)
info_list.append(info.find('span',class_='rating_num').string)
pass翻页操作
def nextPage(page):
url='https://movie.douban.com/top250?start='+str(page*25)
return url信息保存
def savelxsl(index_list,name_list,info_list):
wb=openpyxl.Workbook()
ws=wb.active
ws.append(['序号', '名称', '评分'])
for index in range(len(index_list)):
ws.append([index_list[index],name_list[index],info_list[index]])
wb.save('豆瓣电影top250.xlsx')
pass主函数
def main():
start_url='https://movie.douban.com/top250'
index_list=range(1,251)
name_list=[]
info_list=[]
url=start_url
for page in range(1,11):
html=getHTMLtext(url)
parseHTMLtext(html,name_list,info_list)
url=nextPage(page)
pass
savelxsl(index_list,name_list,info_list)
print('下载成功')
pass这就是爬虫的所有代码,我也是python爬虫里的一只小白,代码可能并不完善但还是希望得到大家的支持,以后我也会推出更多的文章来一起学习!!
我们的爬虫结束了,接下来我们看看最终的结果:

这里我也只是爬取了电影名称和评分,获取更多的内容大家可以下去自己尝试一下。