PaddlePaddle百度架构师手把手带你零基础实践深度学习Note1——零基础入门深度学习
PaddlePaddle百度架构师手把手带你零基础实践深度学习学习笔记——零基础入门深度学习
- 1 前言
- 2 机器学习和深度学习综述
-
- 2.1 三个概念的定义和关系
- 2.2 深度学习的历史和今天
- 3 使用Python语言和Numpy库来构建神经网络模型
-
- 3.1 波士顿房价预测问题
- 3.2 处理数据&设计模型
-
- 3.2.1 数据处理
-
- 数据导入
- 数据形状变换
- 数据集划分
- 数据归一化处理
- 封装成load data函数
- 3.2.2 模型设计
- 3.3 训练配置
- 3.4 训练过程
-
- 3.4.1 梯度下降的代码实现及公式推导
- 3.4.2 计算梯度的单个样本代码实现
- 3.4.3 基于numpy广播机制进行多样本梯度计算
-
- 计算所有样本对梯度的贡献
1 前言
此课程为入门课程,感兴趣的小伙伴可以先补一下Python基础的代码编写阅读能力以及了解基础的机器学习和深度学习的理论知识。
课程特色:
特色一:原理与代码结合,讲解深入浅出,帮助学员快速掌握理论知识。
特色二:工业实践案例+作业题结合,帮助学员快速具备深度学习应用能力。
特色三:PaddlePaddle系列产品的一手资料
如想了解更多关于飞桨、深度学习、机器学习或Python课程,可以通过如下三个途径获取。
AI Studio:https://aistudio.baidu.com/
飞桨官网:https://www.paddlepaddle.org.cn/
百度技术学院:http://bit.baidu.com/index
2 机器学习和深度学习综述
2.1 三个概念的定义和关系

人工智能、机器学习和深度学习覆盖的技术范畴是逐层递减的。人工智能是最早提出的也是最宽泛的概念。机器学习是当前比较有效的一种实现人工智能的方式。深度学习是机器学习算法中最热门的一个分支,近些年取得了显著的进展,并替代了大多数传统机器学习算法。三者的关系如上图所示,即:人工智能 > 机器学习 > 深度学习。
机器学习三要素:假设、评价、优化
2.2 深度学习的历史和今天
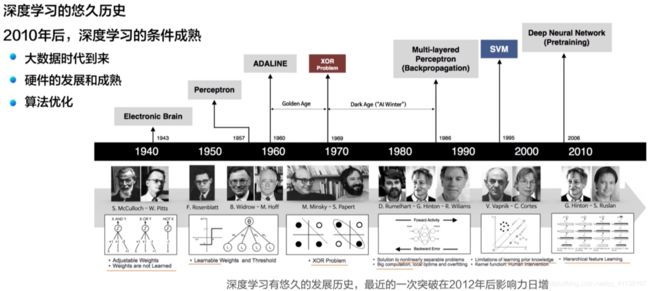
经过半个多世纪的发展,深度学习的理论和应用逐步走向成熟。

3 使用Python语言和Numpy库来构建神经网络模型
3.1 波士顿房价预测问题
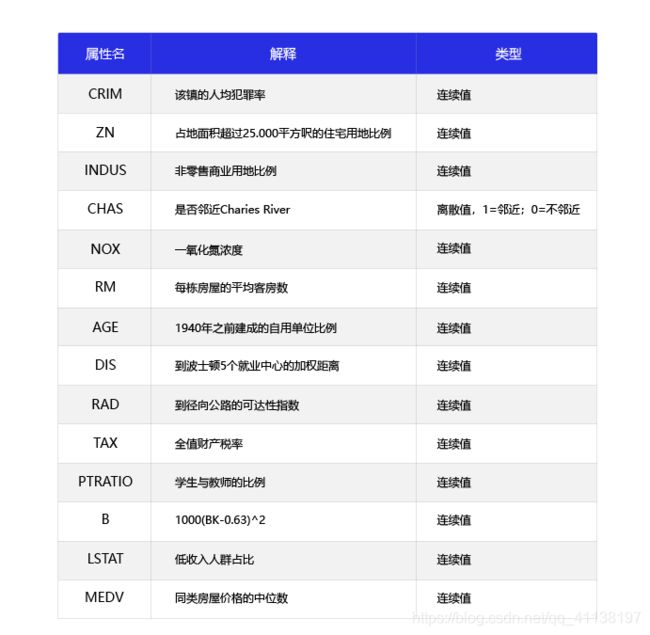
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如下图所示。
对于预测类问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
线性回归模型
假设房价和各影响因素之间能够用线性关系来描述: y = ∑ j = 1 M x j w j + b y=\sum_{j=1}^{M} x_{j} w_{j}+b y=∑j=1Mxjwj+b
模型的求解即是通过数据拟合出每个 w j w_{j} wj 和 b b b。其中, w j w_{j} wj 和 b b b分别表示该线性模型的权重和偏置。一维情况下, w j w_{j} wj 和 b b b是直线的斜率和截距。
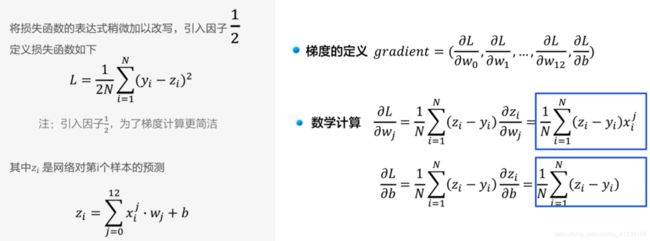
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异: M S E = 1 n ∑ i = 1 n ( Y ^ i − Y i ) 2 M S E=\frac{1}{n} \sum_{i=1}^{n}\left(\hat{Y}_{i}-Y_{i}\right)^{2} MSE=n1∑i=1n(Y^i−Yi)2
此处,之所以用均方差作为损失函数,主要是为了后面求梯度下降的时候通过求导能够得到一个梯度下降趋势的反馈,以便于找到较小的Loss值。
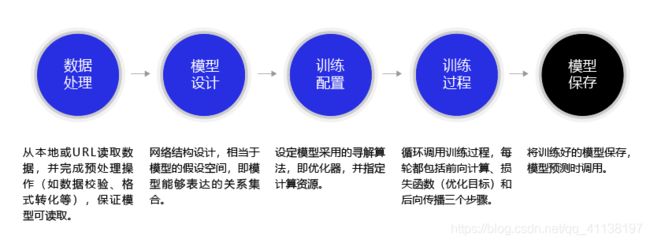
构建模型并完成训练大体可分为以下五步:
数据处理、模型设计、训练配置、训练过程和模型保存
3.2 处理数据&设计模型
3.2.1 数据处理
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。
数据导入
housing.data下载地址:http://paddlemodels.bj.bcebos.com/uci_housing/housing.data
# 导入需要用到的package
import numpy as np
import json
# 读入训练数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
data
数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推....
# 这里对原始数据做reshape,变成N x 14的形式
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 查看数据
x = data[0]
print(x.shape)
print(x)
数据集划分
将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。为什么要对数据集进行拆分,而不能直接应用于模型训练呢?可以类比于期末考试,我们的目的当然是希望训练后的机器除了能够识别出训练数据(“考点”),还能够识别出训练集之外的数据(“新题型”)。本案例中,我们将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape
数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
封装成load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
# 查看数据
print(x[0])
print(y[0])
3.2.2 模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
如果将输入特征和输出预测值均以向量表示,输入特征 x x x有13个分量, y y y有1个分量,那么参数权重的形状(shape)是13×1。假设以如下任意数字赋值参数做初始化: w = [ 0.1 , 0.2 , 0.3 , 0.4 , 0.5 , 0.6 , 0.7 , 0.8 , − 0.1 , − 0.2 , − 0.3 , − 0.4 , 0.0 ] w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,-0.1,-0.2,-0.3,-0.4,0.0] w=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,−0.1,−0.2,−0.3,−0.4,0.0]
w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]
w = np.array(w).reshape([13, 1])
# 取出第1条样本数据,观察样本的特征向量与参数向量相乘的结果。
x1=x[0]
t = np.dot(x1, w)
print(t)
# 完整的线性回归公式,还需要初始化偏移量b。同样随意赋初值-0.2。那么,线性回归模型的完整输出是z=t+b,这个从特征和参数计算输出值的过程称为“前向计算”。
b = -0.2
z = t + b
print(z)
前向计算:由前到后,输出结果
后向传播:由后到前,更新参数
将上述计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数 w w w 和 b b b。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程,代码如下所示。
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,
# 此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
# 基于Network类的定义,模型的计算过程如下
net = Network(13)
x1 = x[0]
y1 = y[0]
z = net.forward(x1)
print(z)
3.3 训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
通过模型计算 x 1 x_{1} x1表示的影响因素所对应的房价应该是 z z z, 但实际数据告诉我们房价是 y y y。这时我们需要有某种指标来衡量预测值 z z z跟真实值 y y y之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义为:
Loss s = ( y − z ) 2 \operatorname{Loss} s=(y-z)^{2} Losss=(y−z)2
因为计算损失函数时需要把每个样本的损失函数值都考虑到,所以我们需要对单个样本的损失函数进行求和,并除以样本总数 N N N:
Loss = 1 N ∑ i = 1 N ( y i − z i ) 2 \operatorname{Loss}=\frac{1}{N} \sum_{i=1}^{N}\left(y_{i}-z_{i}\right)^{2} Loss=N1∑i=1N(yi−zi)2
# Network类下面添加损失函数的计算过程
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
net = Network(13)
# 此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1)
print('loss:', loss)
3.4 训练过程
3.4.1 梯度下降的代码实现及公式推导

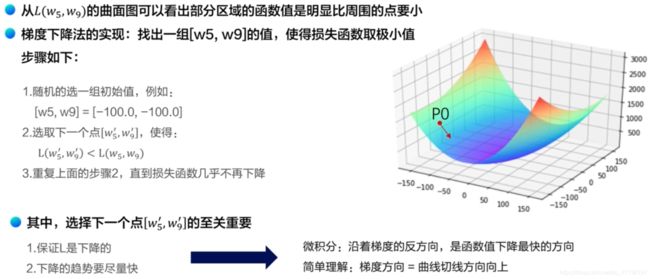
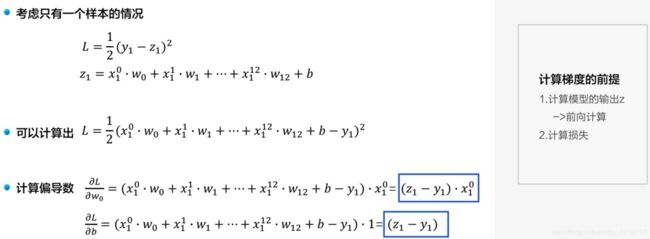
3.4.2 计算梯度的单个样本代码实现
查看单个样本的数据及其维度
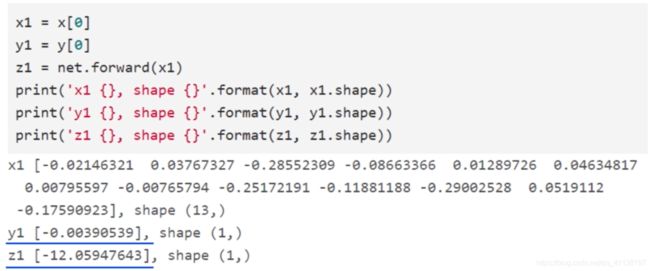
gradient_w0 = (z1 - y1) * x1[0]
print('gradient_w0 {}'.format(gradient_w0))
gradient_w1 = (z1 - y1) * x1[1]
print('gradient_w1 {}'.format(gradient_w1))
gradient_w2= (z1 - y1) * x1[2]
print('gradient_w1 {}'.format(gradient_w2))
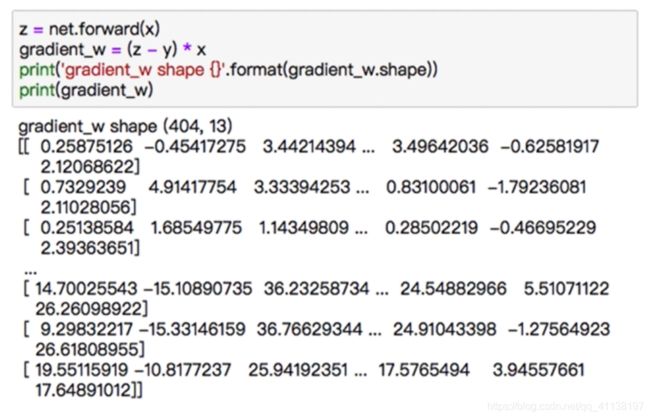
3.4.3 基于numpy广播机制进行多样本梯度计算
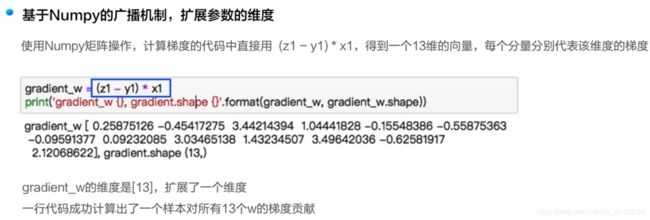
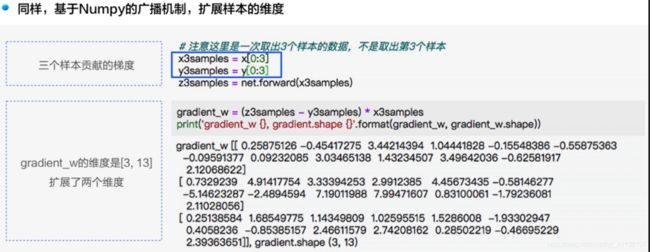
计算所有样本对梯度的贡献