关系抽取(Entity-Relation-Extraction)流水线方案
关系抽取(Entity-Relation-Extraction)流水线方案
概要
关系抽取任务(Entity Relation Extraction Task)可以分为流水线方式和关联学习两种方式,本篇解读的是基于BERT预训练模型的流水线方式关系抽取方案,原作者是把整个任务分为两个模型,即关系抽取和实体识别。关系抽取为多标签分类问题,命名实体识别为序列标注问题。
资料
- bert实践:关系抽取解读
- 原作者 Github: Entity-Relation-Extraction
- 本人 Github
过程
- 第一个模型是关系多标签分类,把句子的所有关系识别出来
- 第二个模型是多分类与序列标注多任务学习模型,需要把抽取的关系加入句子尾部,然后识别出序列标签
方案弊端
原作者在他的博客已经列了三点关于流水线方式存在的问题:
- 误差传递问题。第一个模型错影响整体的效果。
- 忽略了关系和实体之间的联系。这一点我不太理解,希望能有人帮我
- 两两组合预测,低效率。在预测阶段时,第一个模型的关系结果要和句子两两组合作为第二个模型的输入。
数据预处理
-
数据
来源2019语言与智能技术竞赛 提供的数据,包含50种关系。
{
"postag": [{
"word": "内容", "pos": "n"}, {
"word": "简介", "pos": "n"}, {
"word": "《", "pos": "w"}, {
"word": "宜兴紫砂图典", "pos": "nw"}, {
"word": "》", "pos": "w"}, {
"word": "由", "pos": "p"}, {
"word": "故宫出版社", "pos": "nt"}, {
"word": "出版", "pos": "v"}], "text": "内容简介《宜兴紫砂图典》由故宫出版社出版", "spo_list": [{
"predicate": "出版社", "object_type": "出版社", "subject_type": "书籍", "object": "故宫出版社", "subject": "宜兴紫砂图典"}]}
字段描述
postag:分词和词性
text:句子
spo_list:关系类型、主体、客体以及它们的类型
本模型使用的是text和spo_list字段,数据预处理阶段需要对这两个字段处理,text是作为文本输入,spo_list是作为标签。
-
预处理
由于是分阶段训练两个模型,也要分别为两个模型做文本预处理。处理内容包括利用bert的tokenization处理句子,利用实体打序列标签,划分数据集等。
1. 关系分类模型
处理程序:bin\predicate_classifiction\predicate_data_manager.py
输入文件:raw_data/train_data.json,raw_data/dev_data.json,raw_data/test1_data_postag.json
输出文件:包含train、valid、test三个文件夹,文件结构如下:
|____
|_____text.txt # 句子
|_____token_in.txt # tokenization处理后的数据
|_____token_in_not_UNK.txt # tokenization处理后的数据,不包括[UNK]
|_____predicate_out.txt # 标签,其中test文件夹下,没有此文件
text.txt
内容简介《宜兴紫砂图典》由故宫出版社出版
《中国风水十讲》是2007年华夏出版社出版的图书,作者是杨文衡
《空城未央》是夙言以信创作的网络小说,发表于17K小说网
token_in.txt和token_in_not_UNK.txt:
内 容 简 介 《 宜 兴 紫 砂 图 典 》 由 故 宫 出 版 社 出 版
《 中 国 风 水 十 讲 》 是 2007 年 华 夏 出 版 社 出 版 的 图 书 , 作 者 是 杨 文 衡
《 空 城 未 央 》 是 夙 言 以 信 创 作 的 网 络 小 说 , 发 表 于 17 ##k 小 说 网
predicate_out.txt:
出版社
出版社 作者
作者 连载网站
2. 序列标注模型
处理过程:使用实体对文本打标,划分数据集
处理程序:bin\predicate_classifiction\sequence_labeling_data_manager.py
输入文件:raw_data/train_data.json,raw_data/dev_data.json,raw_data/test1_data_postag.json
输出文件:包含train、valid两个个文件夹,文件结构如下:
|____
|_____text.txt # 句子
|_____token_in.txt # tokenization处理后的数据
|_____token_in_not_UNK.txt # tokenization处理后的数据,不包括[UNK]
|_____token_label_and_one_prdicate_out.txt # 标签
|_____bert_tokener_error_log.txt # 错误数据日志
text:
内容简介《宜兴紫砂图典》由故宫出版社出版
《中国风水十讲》是2007年华夏出版社出版的图书,作者是杨文衡
《空城未央》是夙言以信创作的网络小说,发表于17K小说网
token_in.txt:
内 容 简 介 《 宜 兴 紫 砂 图 典 》 由 故 宫 出 版 社 出 版 出版社
《 中 国 风 水 十 讲 》 是 2007 年 华 夏 出 版 社 出 版 的 图 书 , 作 者 是 杨 文 衡 出版社
《 中 国 风 水 十 讲 》 是 2007 年 华 夏 出 版 社 出 版 的 图 书 , 作 者 是 杨 文 衡 作者
token_label_and_one_prdicate_out.txt
O O O O O B-SUB I-SUB I-SUB I-SUB I-SUB I-SUB O O B-OBJ I-OBJ I-OBJ I-OBJ I-OBJ O O 出版社
O B-SUB I-SUB I-SUB I-SUB I-SUB I-SUB O O O O B-OBJ I-OBJ I-OBJ I-OBJ I-OBJ O O O O O O O O O O O O 出版社
O B-SUB I-SUB I-SUB I-SUB I-SUB I-SUB O O O O O O O O O O O O O O O O O O B-OBJ I-OBJ I-OBJ 作者
模型
-
输入
对于关系分类模型,输入和普通的分类模型一样,即一个句子。但对于序列标注模型的输入,需要在句子后加入和句子长度一致的类别标签id序列(tokens_b),类别标签id序列的形成代码如下:
tokens_b = [text_predicate] * len(text_token)
......
# bert_tokenizer.convert_tokens_to_ids(["[SEP]"]) --->[102]
# 1-100 dict index not used
bias = 1
for token in tokens_b:
# add bias for different from word dict
input_ids.append(predicate_id + bias)
segment_ids.append(1)
token_label_ids.append(token_label_map["[category]"])
input_ids.append(tokenizer.convert_tokens_to_ids(["[SEP]"])[0]) # 102
segment_ids.append(1)
token_label_ids.append(token_label_map["[SEP]"])
结果如下:
[CLS] 内 容 简 介 《 宜 兴 紫 砂 图 典 》 由 故 宫 出 版 社 出 版 [SEP] 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 出版社 [SEP] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding] [Padding]
101 1079 2159 5042 792 517 2139 1069 5166 4773 1745 1073 518 4507 3125 2151 1139 4276 4852 1139 4276 102 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 13 102 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
-
模型结构
1. 关系分类模型
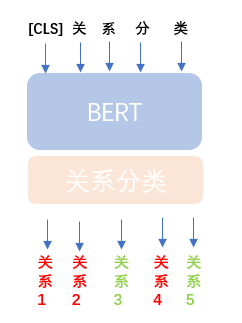
注意:由于是多标签分类,所以计算概率选择sigmod函数:
probabilities = tf.sigmoid(logits)
2. 序列标注模型
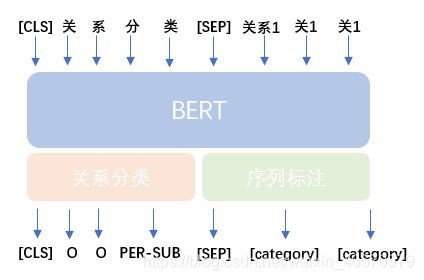
可以观察到此模型其实包含了两个任务,既要做关系分类的任务,又要做系列标注的任务,代码中体现在 “predicate_loss” 和 “token_label_loss” 这两个变量域,最后的 loss 是加权求和得到的。
loss = 0.5 * predicate_loss + token_label_loss
0.5 超参数一般是拍脑袋定的,想具体深入了解,我推荐可以看看 《深度学习的多个 loss 是如何平衡的?》这篇文章。
完整代码如下:
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
token_label_ids, predicate_label_id, num_token_labels, num_predicate_labels,
use_one_hot_embeddings):
"""
Creates a classification model.
"""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. float Tensor of shape [batch_size, hidden_size]
predicate_output_layer = model.get_pooled_output()
intent_hidden_size = predicate_output_layer.shape[-1].value
predicate_output_weights = tf.get_variable(
"predicate_output_weights", [num_predicate_labels, intent_hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
predicate_output_bias = tf.get_variable(
"predicate_output_bias", [num_predicate_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("predicate_loss"):
if is_training:
# I.e., 0.1 dropout
predicate_output_layer = tf.nn.dropout(predicate_output_layer, keep_prob=0.9)
# shape = [batch_size, num_predicate_labels]
predicate_logits = tf.matmul(predicate_output_layer, predicate_output_weights, transpose_b=True)
predicate_logits = tf.nn.bias_add(predicate_logits, predicate_output_bias)
predicate_probabilities = tf.nn.softmax(predicate_logits, axis=-1)
predicate_prediction = tf.argmax(predicate_probabilities, axis=-1, output_type=tf.int32)
predicate_labels = tf.one_hot(predicate_label_id, depth=num_predicate_labels, dtype=tf.float32)
predicate_per_example_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=predicate_logits, labels=predicate_labels), -1)
predicate_loss = tf.reduce_mean(predicate_per_example_loss)
# """Gets final hidden layer of encoder.
#
# Returns:
# float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
# to the final hidden of the transformer encoder.
# """
token_label_output_layer = model.get_sequence_output()
token_label_hidden_size = token_label_output_layer.shape[-1].value
token_label_output_weight = tf.get_variable(
"token_label_output_weights", [num_token_labels, token_label_hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02)
)
token_label_output_bias = tf.get_variable(
"token_label_output_bias", [num_token_labels], initializer=tf.zeros_initializer()
)
with tf.variable_scope("token_label_loss"):
if is_training:
token_label_output_layer = tf.nn.dropout(token_label_output_layer, keep_prob=0.9)
# shape = [batch_size * seq_length, token_label_hidden_size]
token_label_output_layer = tf.reshape(token_label_output_layer, [-1, token_label_hidden_size])
# shape = [batch_size * seq_length, num_token_labels]
token_label_logits = tf.matmul(token_label_output_layer, token_label_output_weight, transpose_b=True)
token_label_logits = tf.nn.bias_add(token_label_logits, token_label_output_bias)
# shape = [batch_size, seq_length, num_token_labels]
# 计算序列标注的loss
token_label_logits = tf.reshape(token_label_logits, [-1, FLAGS.max_seq_length, num_token_labels])
token_label_log_probs = tf.nn.log_softmax(token_label_logits, axis=-1)
token_label_one_hot_labels = tf.one_hot(token_label_ids, depth=num_token_labels, dtype=tf.float32)
token_label_per_example_loss = -tf.reduce_sum(token_label_one_hot_labels * token_label_log_probs, axis=-1)
token_label_loss = tf.reduce_sum(token_label_per_example_loss)
# 计算概率
token_label_probabilities = tf.nn.softmax(token_label_logits, axis=-1)
token_label_predictions = tf.argmax(token_label_probabilities, axis=-1)
# return (token_label_loss, token_label_per_example_loss, token_label_logits, token_label_predict)
loss = 0.5 * predicate_loss + token_label_loss
return (loss,
predicate_loss, predicate_per_example_loss, predicate_probabilities, predicate_prediction,
token_label_loss, token_label_per_example_loss, token_label_logits, token_label_predictions)
-
模型评估
1. 关系分类模型
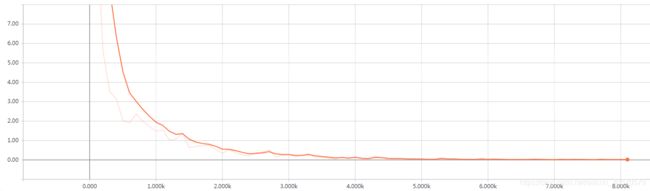
| global_step | eval_accuracy | eval_loss |
|---|---|---|
| 8128 | 0.648 | 2.7102852 |
2. 序列标注模型
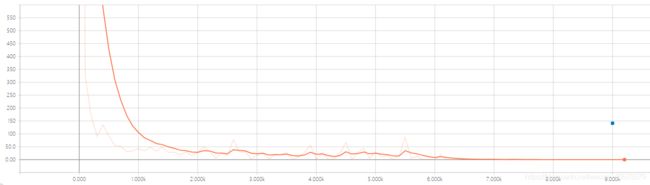
| global_step | eval_token_label_precision | eval_token_label_recall | eval_token_label_f | eval_predicate_loss | eval_token_label_loss |
|---|---|---|---|---|---|
| 9000 | 0.920 | 0.947 | 0.933 | 0.01728 | 0.13838 |
-
总结
预训练模型最终使用的是RoBert,相比Bert而言,Robert在训练过程中Loss会比Bert平稳很多,因为参数数量差距不大,所以速度上其实是差不多的。
第一个模型效果不太理想,也能理解,因为多标签分类模型效果一向不会太好;第二个模型训练出来的效果确实出乎预料,构造输入巧妙,并且最后使用多任务方式的训练,也让这个模型逼格提高了一个档次。