Python爬虫爬取:科幻世界
作为一名科幻的忠实爱好者,《科幻世界》是伴随我长大的朋友,学习之余能看上一篇精彩的科幻小说无疑是一种享受。
今天博主尝试在参考网上爬取免费的《科幻世界》往期期刊。
如图:

话不多说,直接上代码。
import requests
import os
from lxml import etree
import time
if not os.path.exists('fiction'):
os.mkdir('fiction')
url_part='http://www.fx361.com/bk/khsj/2020%d.html'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
for i in range(1,11):
url=format(url_part%i)
html_data=requests.get(url=url,headers=headers).text
tree=etree.HTML(html_data)
div_list=tree.xpath('//*[@id="dirList"]/div')
for div in div_list:
href=div.xpath('./ul/li/a/@href')[0]
title=div.xpath('./ul/li/a/text()')[0]
all_title='fiction/'+title+'.text'
text_url='http://www.fx361.com'+href
response=requests.get(url=text_url,headers=headers)
response.encoding='utf-8'
text_data=response.text
tree2=etree.HTML(text_data)
fiction_data=tree2.xpath('/html/body/div[2]/div[2]/div[1]/div/div[2]//text()')
fiction_data=''.join(fiction_data)
with open(all_title,'w',encoding='utf-8') as fp:
fp.write(fiction_data)
print(title,'存储完毕!')
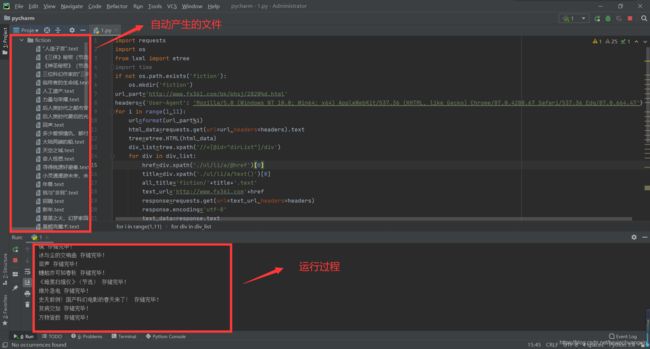
运行截图:
之后我放到wps上看: