faster R-CNN 框架总结
这几天在学习faster R-CNN,看到一篇文章总结得很棒,特转来学习。
转自:https://zhuanlan.zhihu.com/p/32905770
论文:Towards Real-Time Object Detection with Region Proposal Networks
code:matlab ShaoqingRen/faster_rcnn,python AssetionError: training py-faster-rcnn with one class · Issue #34 · rbgirshick/py-faster-rcnn
论文笔记:【目标检测】Faster RCNN算法详解、CNN目标检测(一):Faster RCNN详解,faster-rcnn原理及相应概念解释

上图是论文给出的faster rcnn框架图,再细致一点的话,就是:

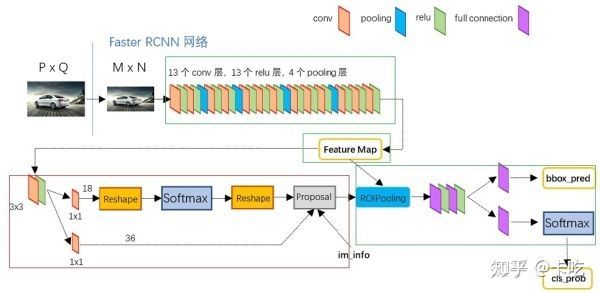
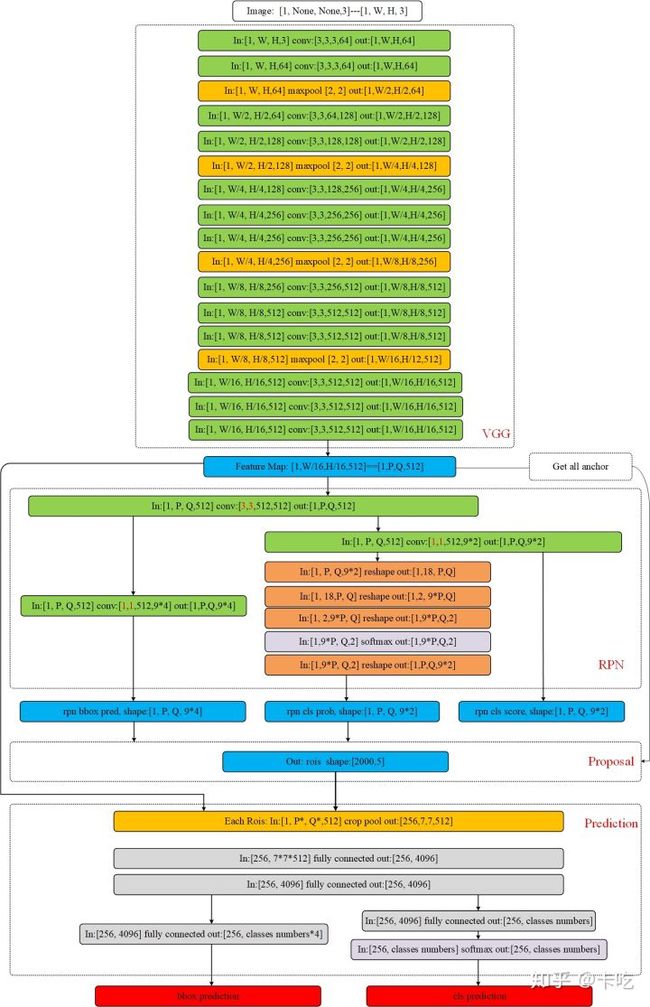
此图来自于https://zhuanlan.zhihu.com/p/35922980
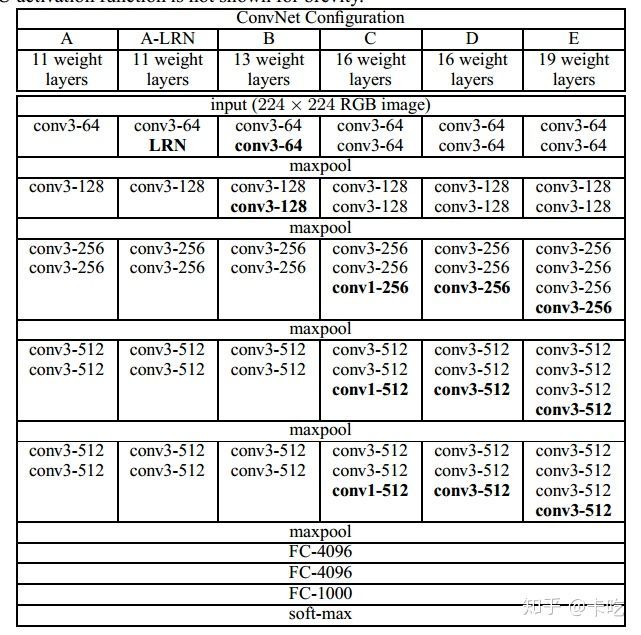
VGG网络
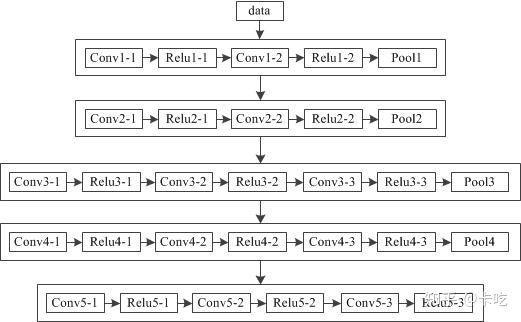
faster rcnn中使用的VGG16,没有全连阶层
论文主要内容
一、论文主要解决三个问题
1.设计RPN网络,生成推荐区域;
2.用fast rcnn 检测推荐区域;
3.使RPN和fast rcnn共享卷积特征提取网络。
二 、主干网过程
主干网可以采用VGG16、resnet101等网络模型,进行特征提取。采用VGG16的话,对输入[1, W, H, 3]的图片(这个batch size我设为1了)。进行多层卷积操作。输出是一个[1, W/16, H/16, 512]维的特征形式,即feature map。
假设输入图片尺寸是[1, 256, 256, 3],那么VGG16之后,feature map中,特征形式为[1, 16, 16, 512],记P=Q=16。
三、获得标准anchor过程
1.anchors(初始的推荐区域)
在feature Map上,对于每一张图像的每一个位置,生成9个初始的推荐区域(即anchors),这9个推荐区域的大小、尺寸是三种面积*三种比例,即 。
在论文公布的代码中,generate_anchor.py运行得到的9个初始化anchor输出如下:
-83 -39 100 56
-175 -87 192 104
-359 -183 376 200
-55 -55 72 72
-119 -119 136 136
-247 -247 264 264
-35 -79 52 96
-79 -167 96 184
-167 -343 184 360
注意,这里面对坐标进行了取整,因此,在进行验证的时候可能计算出来的面积与给定的面积有点出入,但是没有关系。每一行的四个数分别代表{xmin,ymin,xmax,ymax}。这9个初始化anchor的中心点坐标都是[7.5,7.5],这个坐标是在feature map上面的。 三种面积的长宽分别为:
128 128;128/1.414 128*1.414;128*1.414 128/1.414;
256 256;256/1.414 256*1.414;256*1.414 256/1.414;
512 512;512/1.414 512*1.414;512*1.414 512/1.414;
每个点有9个anchor,那么[1, 16, 16, 512]的特征向量共有16*16*9个anchor(~2400)。
anchor得到以后都要映射到原图像上面,对于特征图大小为[16,16]每个点有9个anchor,原图为[256,256]。即
[0,1,2,…,15]--->[0,16,32,…,240]
那么特征图上的坐标[0 0; 0 1; …;14 15; 15 15]对应到原图就是[0 0; 0 16; …;224 240;240 240]。
首先计算出所有以特征图上的坐标为中心的anchor,然后将所有以特征图上的坐标为中心的anchor全部转换到以原图坐标为中心的anchor。一般图像上原点是图像左上角,向下为y轴正方向(高),向右为x正方向(宽)。
记原图上面anchor的中心点为 。那么原图上面,anchor表示为 ,表示anchor的中心点坐标和宽、高。原图上面的这个anchor称为标准的anchor输出,也可以叫做box。

每个点的anchor
四、RPN过程
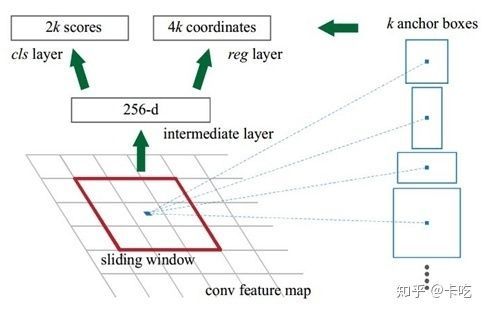
RPN,其中的k指的是k个初始的anchors,论文中k=9
该部分的主要内容是通过卷积网络得到每个anchor是否是前景的概率以及每个anchor的坐标、尺寸的偏差。
偏差计算公式如下:
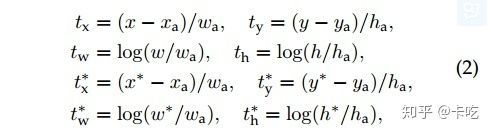
偏差计算公式
其中

即公式中的 即上一部分中的标准的anchor的相关数据。
但是 是如何获得的呢?
论文采用一个3*3的滑动窗口对feature map进行卷积操作。feature map大小为[P, Q, 512],得到的输出大小仍然是[P, Q, 512]。然后再对这个输出分两部分进行操作(这一块要看看代码)。
cls layer:一路进行[1, 1, 512, 18]的卷积操作。输出大小是[P, Q, 9*2]。这里很好理解,每个点有9个anchor,相当于对每个anchor对应生成一个1*2的向量,用来表示这个anchor是不是目标。我们可以令[1, 0]代表这个anchor是目标,[0,1]表示是框的是背景。当然,因为要归一化到0,1所以要经过一个简单的reshape把每个1*2的向量单独分出来再做一个softmax分类。这样分类之后再reshape回去就可以了。这一路输出得到输出大小是[1, P, Q, 9*2],记为rpn_cls_prob。
reg layer:另一路同样经过[1, 1, 512, 9*4]的卷积操作得到[P, Q, 9*4]的输出,对应的是每个点的每个anchor的四个偏移量 。为什么要四个偏移量呢,因为我们前面的anchor就是一个定值,而实际的物体box和前面的anchor肯定有偏差。所以我们再用四个偏差来进行一次box的修正(偏差计算公式),获得 ,这些值都是原图上的。该部分的输出是[1, P, Q, 4*9],记为rpn_reg。
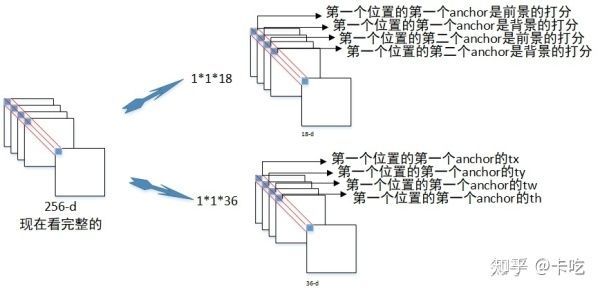
如下图所示,图片中所示的feature map 深度是256,我在前面计算的feature map是512的深度(VGG16网络)。以256深度为例子,介绍cls layer和reg layer。
由于anchor是对于每张图的每个位置,都有9个初始的anchors,那么首先只看一个位置的:

那么对于整个feature map,则是:
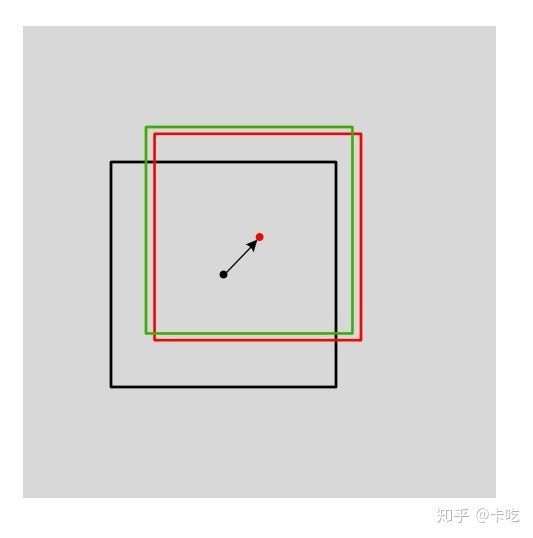
修正后的box,我们称为第一次修正后的box。该box是对标准输出的anchor做平移和尺寸缩放。如下图所示,黑色的box是标准anchor,红色的box是第一次修正后的box,绿色的box是真实的box(ground truth)。
五、proposal过程
RPN过程获得了第一次修正后的所有box以及每个box所对应的概率。proposal过程是根据每个第一次修正后的box的值,选取出合适的部分box,再反向投影到前面得到的[1, P, Q, 512]的feature map上。
首先,对第一次修正后的box进行判断,如果box的大小超出了边界,那么就将这一边改成边界值,我们令这个修正后的输出是proposal_clip_box,其输入是rpn_reg获得的第一次修正后的图。
其次,对所有输出的proposal_clip_box和真实的ground truth box求重合度IoU,进行筛选。
那么IoU是什么?假设proposal_clip_box的面积为SA,真实box面积为SB,两者的重叠面积为 SA and SB。那么IOU:
筛选规则如下:
- 与GT相比,拥有最高的IOU的anchor为前景(可以低于0.7)
- 与任意GT相比,IOU>0.7为前景
- 与任意GT相比,IOU<0.3为背景
- 其余的非负非正,则没有用
那么对于proposal_clip_box,怎么比较其IoU呢?
step 1,用scores表示rpn_cls_prob([1, P, Q, 2*9]),取第四维度的后九位数,这九位数表示真实物体的概率。见下图
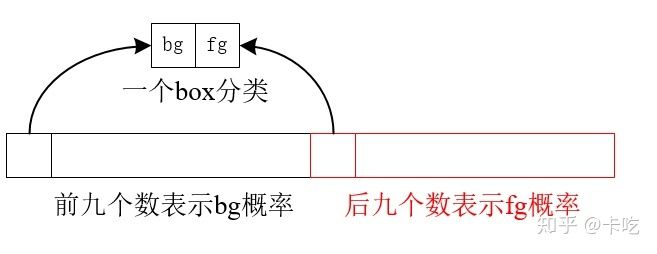
将其reshape成向量,使scores=[1, P*Q*9]。我们再按大小排序后取出对应的索引值。取scores比较大的前topN个(12000),进行NMS(非极大值抑制)。
step 2,NMS(非极大值抑制)。什么是NMS?
所谓非极大值抑制:先假设有6个输出的矩形框(即proposal_clip_box),根据分类器类别分类概率做排序,从小到大分别属于车辆的概率(scores)分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
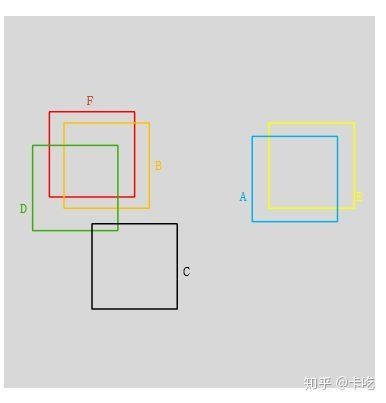
如上图F与BD重合度较大,可以去除BD。AE重合度较大,我们删除A,保留scores较大的E。C和其他重叠都小保留C。最终留下了C、E、F三个。
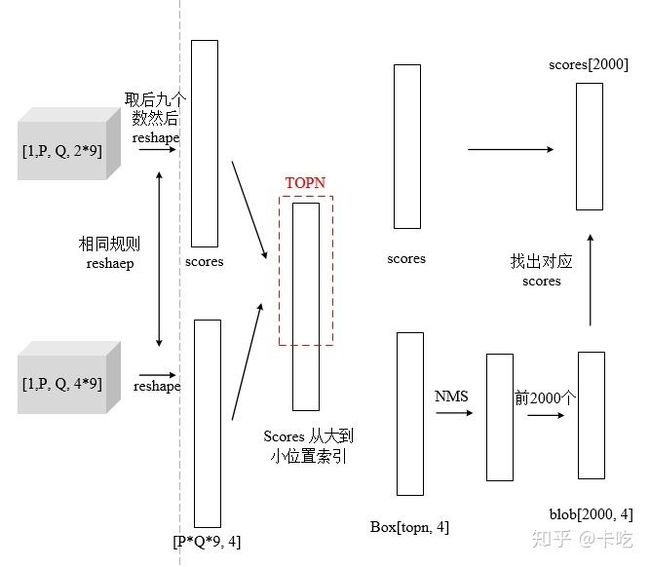
比较IoU并进行筛选的整体过程
该过程后,得到大约2000个box(称为blob)。
真正的proposal过程:将这些blob反向投影到前面的feature map上得到对应的2000个rois。Blob表示的是原图上的box大小,rois表示的是投影到[1, P, Q, 512]的feature map上时对应的box大小。经过这个反向投影就得到了2000个roils了(图里维度是[2000,5]而不是[2000,4]是因为加了一维全0的项用于表示一个图片,要是多张图片就要改了)。
六、predict
前面得到了所有的rois后就可以进行最后的预测模型了。假设我们的一个rois取出来大小是[10, 10, 512]即从原图像投影到feature map上大小变成[10, 10]。我们后面分类的时候要复用同一个卷积网络,所以对不同大小的rois要池化成同一个大小的输入:这里统一池化成[7, 7, 512]。
Rois pooling过程:将输入特征先进行 的均匀划分,然后对分的每一块进行max pooling即可。 太大,我们以 输出为例子:

max pooling
经过前面rois pooling后我们对每个roils得到了固定尺寸的特征矩阵。然后可以进行分类卷积操作。分类时一样进行两路。两路输入都是[256, 7, 7, 512],256代表有多少个roils。将这个值进行两次全连接输出[256, 4096]。然后再分开两个全连接,一个输出大小[256, classes numbers], classes numbers是我们的目标物体分类数,假设是10分类的任务,那么就是10。输出经过softmax后是One hot形式。另一路输出[256, classes numbers*4],表示对256个box的第二次修正偏差值 。因为上面虽然修正一次了但是可能还不太正确,这里再修正一次。修正方法和上面一样。修正后就可以得到我们最后真正的输出了。同样还可以得到每个box的分类概率。通过分类概率大小我们设置一个阈值,当分类概率达到一定阈值之后才输出。这样就可以将所有可能的目标的box和分类类别画出来了。
七、损失函数
采用分类损失+回归损失两种相结合的方式。
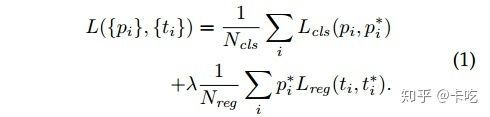
其中, 是mini-batch中的anchor的索引, 表示anchor 是前景的预测概率, 表示anchor 是真实类别的概率:如果anchor 是前景,则为1,否则为0。 是网络输出的四个参数组成的向量,代表一个是前景的anchor变为GT的四个参数组成的向量,可以看到 前乘以了 ,说明只有当这个某个anchor的确是前景时才有回归损失。另外,是mini-batch的大小(256),是anchor位置的数量(~2000), 为10,意思是两种损失基本上同样重要。
注意:由于在RPN阶段有一个分类和回归,最后的预测阶段也有一个预测和回归,因此损失的计算是这两部分的之和。
八、训练
RPN的训练方法:
(1)采用反向传播和SGD(stochastic gradient descent)进行end to end的训练;
(2)训练初始化的时候,其新层的权重服从标准偏差为0.01、均值为0的高斯分布,其他层的权重通过使用ImageNet分类预训练的模型获得。
九、共享卷积特征提取网络
如何共享,本文提供了三种方法
(1)轮流训练:
记W0为使用ImageNet的分类库得到初始参数,那么
a. 从W0开始,训练RPN。用RPN提取训练集上的候选区域,并对区域推荐任务进行end to end的微调。
b. 从W0开始,使用a步骤中RPN生成的区域推荐,fast rcnn训练检测网络,获得W1。
c.从W1开始,训练训练RPN。
d.保持共享网络的参数值,对属于fast rcnn独有的层进行微调。
这也是本文中采取的方式。
(2)近似联合训练
(3)联合训练
----------------------------------------------------------------------
下面内容来自于Faster R-CNN学习总结,这里贴出来,自己学习。
怎么从同一个256维的向量中区分出9个框并挨个评分呢?论文中写道:并没有显式地提取任何候选窗口,完全使用网络自身完成判断和修正。结合损失函数是不是能看出来什么。
对于一个网络,我们已经提供了所有的信息(感受野包含了9个anchor boxes),我们想朝着什么方向来训练(这里就是为9个anchor boxes打分和回归)则由损失函数来决定,即损失函数决定了网络拥有什么样的能力:我们想网络能识别手写数字,就让网络输出与对应的手写数字信息相差最小;我们想让网络识别人脸,就让网络输出与对应的人脸信息相差最小。ok,这里我们想让网络能够为9个anchors打分并回归,那么我们就让网络的输出与anchor boxes真实的情况(是否为前景以及与GT的位置偏差)相差最小。而损失函数中 以及 不就是不同anchor boxes的真实情况吗。所以我们给网络提供了完整的信息,确定了它的训练目的,那么它最终就能做到想要的任务(这里说的有点绝对,只是为了方便理解)
再结合之前说的"最后那18个卷积核和36个卷积核都有自己的任务:针对同一位置不同Anchor或者同一Anchor的不同的指标(是否是前景,以及回归意见等)",可以把网络看成学习了9个前景/背景打分器,9个线性回归器。每个打分器对一个点的某种anchor判断是前景还是背景,每个线性回归器对一个点的某种anchor进行位置修正。
说了这么多只是希望大家能理解为什么从同一个256维的向量中能学到这么多东西(这里确实很难理解,可能我也理解的有误,但是这是目前我唯一能想到的,并说服自己的一个想法了。如果不对,希望大佬们能指一条明路)
有了打好分的anchor boxes以及初步修正意见,再结合原图的一些信息就能经由图2中的Proposal层来得到输入图像的Region Proposals(这里面又涉及到NMS,以及剔除超出图像边界的ROI,细节感兴趣的可以自行了解,因为对全文的理解不会有太大影响,我也没有深入了,主要是时间不够,后面可能会再来更新这一部分)。这样RPN就代替SS算法产生了输入图像的Region Proposals(也就是ROI),剩下的事情例如在feature map中找到Region Proposals对应的部分等就和Fast R-CNN一模一样了。