Faster R-CNN论文详解
Faster R-CNN
1、Faster R-CNN 贡献
这篇文章最重要的创新在于提出了Region Proposal Network(RPN)和anchor box,使得可以用神经网络来提取proposal-region,同时使得整个过程具有以下的优点:
- 几乎是cost-free的,因为RPN和提取特征的CNN网络共享参数
- RPN可以同时预测bound box和objectness score
- 提出了anchor box,可以用多种宽高比和尺度来预测proposal
- 可以使得整个目标检测的网络进行端对端的训练
2、 模型结构
Faster R-CNN是对Fast R-CNN进行的改进,所以模型上有很多相似之处。简单来说,Faster R-CNN其实是在Fast R-CNN模块的基础上加了一个Region Proposal Network模块。
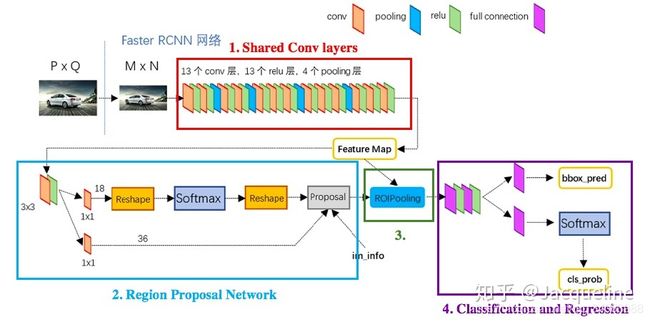
上图为Faster R-CNN框架图,从图中我们可以看出Faster R-CNN主要包括4个部分:Conv layers、Region Proposal Network、RoI pooling、Classifier。其中RoI pooling、Classifier是属于Fast R-CNN,而Conv layers是Region Proposal Network和Fast R-CNN共享的部分。总而言之,Faster R-CNN包括两个模块:Fast R-CNN模块和Region Proposal Network模块。而这两个模块又可以细分为4个部分。
上图是一个整体的框架图,告诉我们各个部分是怎么配合工作的,但是没有详细的描述各个部分的内部结构是什么,是如何实现的。所以我们需要配合着下图来看。下图给出的是使用VGG16模型的Faster R-CNN网络结构图,即Faster R-CNN中的conv layers使用的是VGG16的conv layers。

同样,在上图中我们也将整个网络分为了4部分,包括:
- Shared Conv Layers:使用13个卷积和4个pooling层来提取图片的feature map,这部分是Fast R-CNN模块和Region Proposal Network模块共享的。
- Region Proposal Network:用神经网络取代传统的方法来产生region proposal。
- RoI pooling:根据region proposal和feature map来提取每个region对应的feature,这和Fast R-CNN中的 RoI Pooling Layer相同。
- Classification and Regression:和Fast R-CNN类似,这部分主要完成两个工作:(1)一个是经过FC layer + softmax进行分类,主要是对object proposal进行分类的,一共包括(K+1)类,即K类物体加上1个背景类。(2)另一个是经过FC layer + bbox regressor输出的,这个就是为K个类各输出4个值(K*4),而这4个值代表着精修的bounding box position。
接下来,本文将从以上述4个内容作为切入点介绍Faster R-CNN网络。
3、 卷积层(Shared Conv Layers)
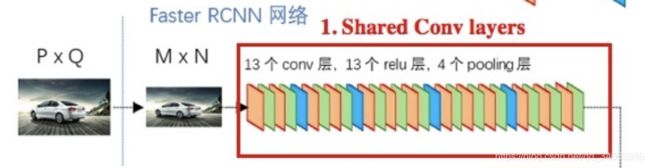
从图中我们可以看到,使用VGG16的Faster R-CNN的conv layers中共有13个conv层,13个relu层和4个pooling层。VGG16是一个非常招人喜欢的网络,因为网络结构非常有规律,非常整齐!VGG16中所有的conv层都是kernel_size=3, padding=1, stride=1,而所有的pooling层kernel_size=2, padding=0, stride=2。这样设计也是暗藏玄机呀,假设我们输入的图片的大小为(m, n),我们可以根据神经网络中层与层之间的公式计算一下输出的大小:
- Conv layer: m i + 1 = m i − k + 2 p 1 + 1 m_{i+1} = \frac{m_i-k+2p}{1}+1 mi+1=1mi−k+2p+1 ,代入数值可得 m i + 1 = m i − 3 + 2 1 + 1 m_{i+1} = \frac{m_i-3+2}{1}+1 mi+1=1mi−3+2+1 ,所以当图片经过卷积层时大小不变。
- Pooling layer: m i + 1 = m i − k s + 1 m_{i+1}=\frac{m_i-k}{s}+1 mi+1=smi−k+1 ,代入数值可得 m i + 1 = m i − 2 2 + 1 = m i 2 m_{i+1}=\frac{m_i-2}{2}+1=\frac{m_i}{2} mi+1=2mi−2+1=2mi ,所以当图片经过pooling层时大小减半。
根据公式,我们就可以计算出每层输出的大小。从表中,我们可以看出最后一层卷积输出的大小是输入图片的1/16倍。

那这样到底有什么好处呢?这样我们就找到了原图和feature map的映射关系,就直接可以把两者对应起来了,这在目标检测中特别重要。这使得我们在feature map上找到的region proposal可以很轻松的就能对应到原图上。
4、RPN (Region Proposal Network)
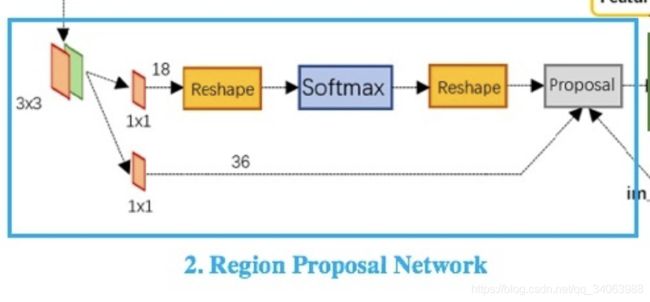
从图中可以看出RPN的主要流程包括:生成anchors、softmax分类器、bbox reg回归器 、Proposal Layer生成proposals。接下来,我们针对这几部分详细介绍。
4.1 、生成anchors(Generate Anchors)
我们先来讲如何生成anchor:首先使用一个(3, 3)的sliding window在feature map上滑动(就是做卷积,卷积的本质就是卷积核滑动求和),然后取(3, 3)滑窗的中心点,将这个点对应到原图上,然后取三种不同的尺寸(128, 256, 512)和三种比例(1:1, 2:1, 1:2)在原图上产生9个anchor,所以feature map上的每个点都会在原图上对应点的位置生成9个anchor,而我们从上边的分析已经得知feature map的大小为输入图片的1/16倍,所以最终一共有 m 16 ∗ n 16 ∗ 9 \frac{m}{16}*\frac{n}{16}*9 16m∗16n∗9 个anchor。这是从原文中解读出来的,你看懂了吗,反正我还是云里雾里的,所以还是得看代码啊。
-
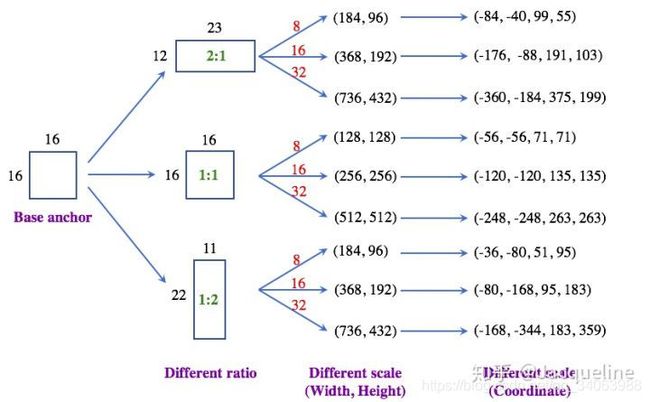
首先呢先生成一个base anchor,这个anchor的大小是 16 ∗ 16 16*16 16∗16的,然后在原图中的位置是(0, 0, 15, 15),其中(0, 0)anchor在原图中左上点的坐标,(15, 15)是右下点的坐标,所以我们可以知道中心点是(7.5, 7.5)。至于为什么选 16 ∗ 16 16*16 16∗16的大小作为base anchor呢,可能是因为经过卷积层后feature map的大小是原图的1/16,所以feature map上的一个点对应着原图中16*16的区域(纯属个人理解)。
-
然后根据这个base anchor,生成三个面积相近(接近16*16=256),但宽高比(ratio)不同的三个base anchors,于是就生成了中心点为(7.5, 7.5),宽高分别为(23, 12)、(16,16)、(11, 22)的三个base anchors。
-
然后呢,对于每种宽高比的base anchors,我们又把base anchors按照三种不同的scale(8, 16, 32)放大。以(23, 12, 7.5, 7.5)这个base anchor为例,按照三种scale放大,分别变成(184, 96, 7.5, 7.5)、(368, 192, 7.5, 7.5)、(736, 432, 7.5, 7.5)三个anchor,然后其他两个不同ratio的base anchors也按照三种比例放大,最终我们就得到9个anchor,然后我们把(184, 96, 7.5, 7.5)这种用中心点和宽高表示的方法换成(-84, -40, 99, 55)这种用左上点和右下点坐标表示的形式,至此我们就生成了在9个anchor。
-
最后,我们根据feature map上各点的坐标,乘以16得到在原图上对应个点的坐标,然后呢将这9个anchor依次移动到各个位置,就得到了整个原图上所有的anchor啦(如下图所示)。

至此我们已经生成了所有的anchor啦。最后,再唠叨几句,其实生成anchors和那个 3 ∗ 3 3*3 3∗3的卷积并没有太大关系,anchors的生成完全是由另一个函数生成的。所以那个 3 ∗ 3 3*3 3∗3的卷积就只是在之前输出的feature map上再做一次卷积。
4.2、 Softmax分类器(Softmax Classifier)
这个softmax分类器起的作用只是一个初步的分类,并不是最终的,它的作用主要是来判断每个anchor对应的是foreground还是background,所以只是一个简单的二分类器。
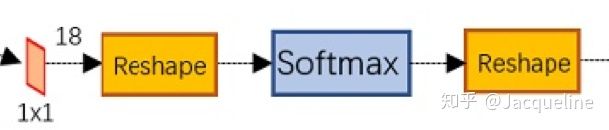
具体就是将 3 ∗ 3 3* 3 3∗3 的卷积输出的feature map (在VGG16中,大小为 m 16 ∗ n 16 ∗ 512 \frac{m}{16}*\frac{n}{16} *512 16m∗16n∗512 ) 输入到一个 1 ∗ 1 1 * 1 1∗1 的卷积层中,然后得到输出的大小为 m 16 ∗ n 16 ∗ 18 \frac{m}{16}*\frac{n}{16} *18 16m∗16n∗18 。为什么是18呢,因为feature中每个点都有9个anchor,每个anchor又对应着foreground和background两种可能,所以是18。然后把 1 ∗ 1 1*1 1∗1 的卷积的输出输入到softmax分类器中得到分类结果。此外,图中的两个reshape主要是用caffe实现时,数据结构的特性决定的,可以不要太在意。
4.3、 Bbox回归器(Bounding Box Regressor)

这个bounding box回归器也只是一个初步的回归,主要是来修正anchor的,同样也是将 3 ∗ 3 3*3 3∗3 的卷积输出的feature map(在VGG16中,大小为 m 16 ∗ n 16 ∗ 512 \frac{m}{16}*\frac{n}{16} *512 16m∗16n∗512 )输入到一个 1 ∗ 1 1*1 1∗1 的卷积层中,然后得到输出的大小为 m 16 ∗ n 16 ∗ 36 \frac{m}{16}*\frac{n}{16} *36 16m∗16n∗36 。为什么是36呢,因为feature中每个点都有9个anchor,每个anchor又对应着4个位置的变换量,所以是36。
4.4、 Proposal层(Proposal Layer)
Proposal层主要是从那么多anchor中选出proposal,因为对于 1000 ∗ 600 1000*600 1000∗600 的图,最终有 40 ∗ 60 ∗ 9 = 21600 40*60*9=21600 40∗60∗9=21600 个anchor,那肯定不能用这么多anchor呀,所以需要从中选取一些proposal出来。从图中我们可以看出Proposal Layer主要有三个输入:softmax的分类结果,bbox regressor的回归结果和im_info =[m, n, scale factor],其中scale factor就是原始图片和最终的feature map的比例,即16。
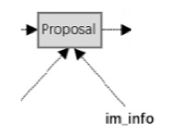
Proposal Layer接受这些输入,然后按照以下流程选出最后的proposal:
- 首先根据bbox regressor的回归结果调整每个anchor的位置。
- 对于一些cross-boundary的anchor,就是anchor的部分已经超过图的边界,那这些anchor就可以去掉啦,经过这一步会剩下大约6000个anchor。
- 然后对于剩下的框,我们按照softmax的分类结果中的foreground score来对anchors进行排序,并取出前n个anchors。
- 对于这n个anchors,使用非极大值抑制的方法来再剔除掉一批。就是计算anchor之间的IoU,然后去除那些和比较大的foreground score的anchor重叠度较高的anchors。
- 然后对于剩下的框,我们再按照foreground score来进行排序,并取出前m个anchors。
然后这最终的m个anchor就是挑选出来的proposal,每个proposal的坐标都是指在原图上的坐标。到这步,RPN网络就完成它的任务啦。接下来就是和Fast R-CNN相同的过程了。
5、RoI Pooling
这个RoI pooling layer和Fast R-CNN中的相同,主要就是根据feature map和region proposals来提取proposal对应的feature map,并将大小不同的proposal的feature map输出成固定大小的。如下图:对于不同size的RoI(object proposal),我们都把它划分成 ( 7 ∗ 7 ) (7*7) (7∗7) 的网格,然后对每个网格(bin)内的全部像素点求一个max pooling,即选取一个最大值作为输出,所有最后对不同size的RoI,我们都得到 7 ∗ 7 7*7 7∗7的feature map。

5.6 分类和回归(Classification and Regression)
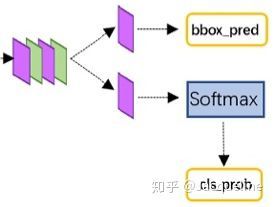
将上述过程获得的proposal feature map输入两个全连接层中进行计算,然后计算结果再分两路,分别经过各自的全连接层完成分类和回归:
- 一个是经过FC layer(k+1个node)+softmax输出的,主要是对object proposal进行分类的,一共包括k+1类,即k类物体加上1个背景类。
- 另一个是经过FC layer(k*4个node)+bbox regressor输出的,这个就是为k个类各输出4个值,而这4个值代表着精修的bounding box position,再次对proposal进行回归得到更精确的位置。
7、 Faster R-CNN训练过程
和之前的目标检测网络训练类似,都是在一个预训练网络的基础上进行训练的。在本文中主要使用4-step交替训练法来训练Faster R-CNN,主要步骤如下:
- 首先使用在ImageNet预训练的网络来训练RPN网络。
- 同样使用ImageNet预训练的网络来训练一个单独Fast R-CNN检测网络,网络中的proposal是第一步训练RPN网络中得到的porposal。
- 使用上一步训练的detection网络的参数来初始化练RPN网络,并且在训练过程中固定shared conv layers这部分,只更新RPN网络专有的那些层。
- 接着固定shared conv layers这部分,只更新Fast R-CNN专有的那些层,其中proposal也是上一步训练RPN网络中得到的proposal。
接下来我们详细讲讲 RPN和 Fast R-CNN是如何训练。
5.7.1 训练RPN
RPN网络主要有两个输出,一个是对anchor的分类结果(foreground or background),另一个是对anchor的位置回归。所以,RPN的损失函数为:
![]()
上述公式中 i i i 表示 anchors index, p i p_i pi 表示第 i i i 个anchor为foreground的概率, p i ∗ p^*_i pi∗ 代表对应的第 i i i 个anchor与ground truth之间的IoU>0.7,认为是该anchor是foreground的,为1;反之IoU<0.3时,认为是该anchor是background,为0;而那些0.3
5.7.2 训练Faster R-CNN
从RPN训练的结果中获取proposal,然后训练Fast R-CNN,这个的训练过程和Fast R-CNN是一样的.其中关于每个proposal的ground truth的定义:如果这个proposal和某个ground truth box有最大的IoU值,那么这个ground truth box的类别就是这个proposal对应的ground truth class,然后这个proposal变到该ground truth box的位置变换,即为该proposal的regression ground truth。