目标检测---YOLOV4
写在前面
首次认真写一篇文章,之所以开始动笔,因为自己在很多文章中受益匪浅,所以想自己也能写一些东西,一是巩固自己所学,再者也希望能够帮到别人。
就目标检测方向来说,很多算法大概的流程大家都懂,然而大概的流程却写不出实际的代码,本文希望能够更多关注一些细节,让大家了解yolov4的一些细节知识,本文算是在看了其它一些文章后自己简要复现了下整个yolov4框架写的一个总结。希望通过本文的解读,大家都能初步写出自己的YOLOv4代码。提前声明,本文仅基于自己的理解,难免疏漏、出错,如有不足希望大家指正,一起学习,一起进步。再者本文也没有实现Yolov4的所有细节,只能算是一个简明版。最后,如果说需要一些必要知识背景的话,至少你应该明白CNN的工作原理。
本文代码运行环境:
操作系统:windows10
编程软件:PyCharm Community Edition 2020.3.1
深度学习框架:pytorch1.2
编程语言:python3.7.6
必备库:torch, torchvision,PIL
原文连接:https://arxiv.org/abs/2004.10934
本文的结构,主要由两部分组成:
1)Yolov4网络结构及识别原理
2)网络训练过程。
主要涉及内容如下:
1)主干特征提取网络:CSPDarkNet53。
2)特征金字塔:SPP、PANet。
3)训练技巧:Label Smoothing平滑、CIOU损失、学习率余弦退火衰减。
4)激活函数:Mish激活函数。
初识Yolov4(you only look once),简而概之:
Yolov4是一个深度学习算法,当输入一张自然环境中拍摄的图片后将其送入我们的网络,将会得到一个预测结果显示在图片上,算法会找出图片中存在的物体并对其进行识别。当训练好网络后,检测简单流程为:输入图像---CSPDarknet53结构---SPP结构---PANet结构---Yolov3head结构---解码网络输出值---非极大值抑制---获取最终结果显示在原图上。
一、Yolov4网络结构及识别原理
先放上Yolov4的整个框架。

图1 来自原论文展示的Yolov4三个部分
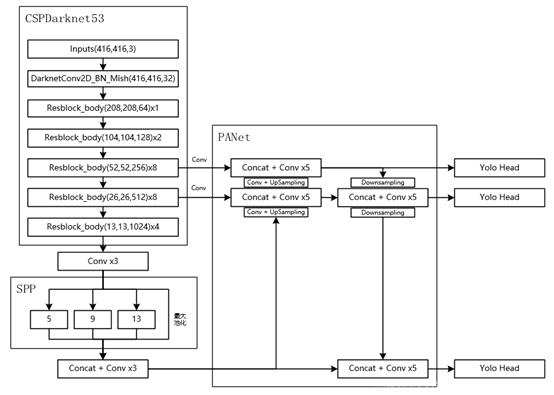
图2 Yolov4网络结构详细构成(图来自网络)
从上面的图可以看出,Yolov4网络主要由三个部分组成,一共161层(可在作者源码中的cfg文件中证实https://github.com/AlexeyAB/darknetgithub.com
首先是CSPDarknet53主干网络,这也算是整个网络的入口,输入图像首先会经过该网络。然后会通过SPP层和PANet层,最后经由Yolov3Head输出结果,这里的结果包括初始的预测框的位置信息和检测目标的得分信息等,经过后处理才能得到最终的结果。根据上图2,先来对整个网络结构解析。
1.CSPDarknet53
CSPDarknet53是在Yolov3的Darknet53结构每个大残差块上加上CSP(Cross Stage Partial),其可以增强CNN的学习能力,能够在轻量化的同时保持准确性、降低计算瓶颈、降低内存成本。这里以416*416的输入为例。其它输入尺寸也行,需要保证为32的倍数(如608*608等),原因后面的SPP和PAN结构会说明。首先输入图片为3*416*416,即为3通道的416*416。然后经过第一个卷积层。
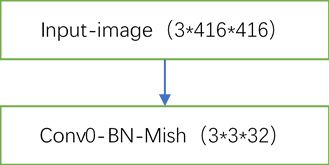
第一层卷积代码为(所有本文代码你都可以换种方式来写,这只是一个示例):
nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1, bias=False),
nn.BatchNorm2d(32),
Mish())解析:图中Conv1-BN-Mish(3*3*32)表示使用3*3的卷积核32个(意味输出通道为32),使用BatchNorm2d规范化和Mish激活函数。BatchNorm2d(32)中的32表示输出通道数,也就是卷积后输出通道为多少,该数字就是多少。代码完全按照框中所示来写,其中步长为1,填充为1,这样可保证输出图像尺寸不变。原因如下:
经过卷积后输出图像尺寸为:
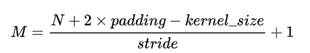
如果想保证输出图像尺寸不变则填充宽度为:
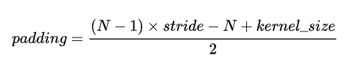
通过以上公式可以设置我们想要的步长和卷积核大小等。需要注意的是关于是否使用bias:卷积之后,如果要接BN操作,最好是不设置偏置,因为不起作用,而且占用显卡内存,所以这里设置为bias=False。最后说下mish激活函数,函数原型如下:
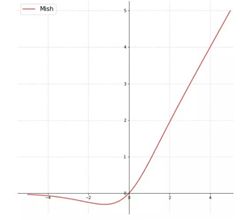
公式如下:
![]()
其中Mish激活函数自定义代码如下:
#mish激活函数
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))下面正式开始CSPDarknet53结构。从图3我们可以发现,输入图像经过第一个卷积层后开始进入第一个分块(一共5个分块)。第一个分块结构如下, 这里以416*416的输入为例。其它输入尺寸也行,需要保证为32的倍数(如608*608等),原因后面的SPP和PAN结构会说明:
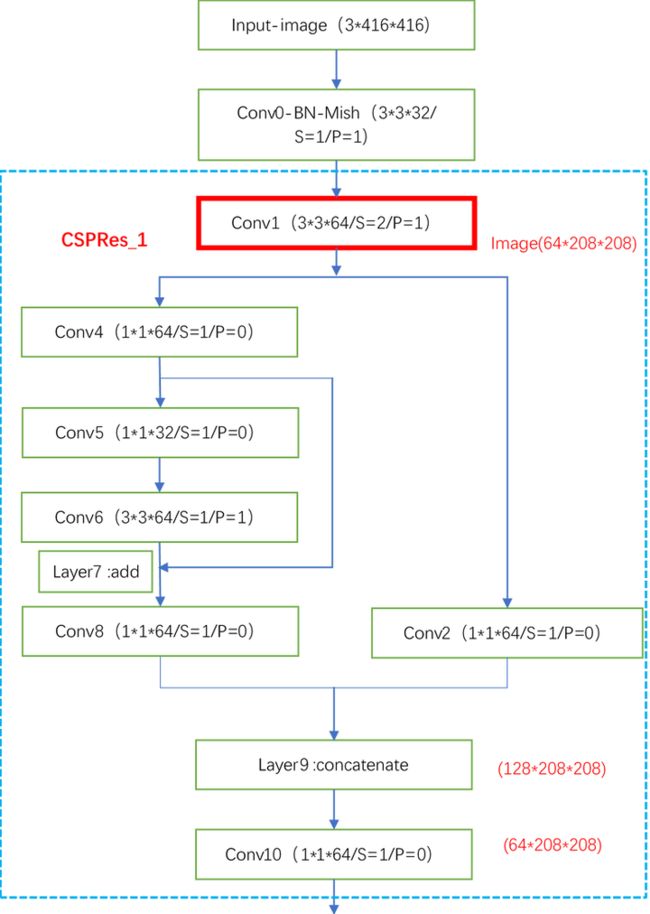
解析:上面每个小框中的S代表stride(步长),P代表padding(填充),S=1表示步长为1,红色框表示这里会完成一次下采样,图像长和宽都将缩小为原来的一半。其中Conv5和Conv6是残差块,Layer7表示Conv6输出结果和Conv4输出结果相加。Layer9的融合代码为:torch.cat([left, right], dim=1),输出结果会使得通道数加倍,即为128*208*208。Conv后面接的数字表示第几层卷积而已,实际编程他们都是Conv2d。

解析:第二个分块中间x2的意思为一共有两个重复的残差块。这里的输入为64*208*208,输出为128*104*104。可以看到网络越往后走,图像通道数越多,尺寸越小。需要注意的是,这里的残差块每次卷积输出通道数一致(后面都是如此),这样有利于后面编程实现。然而在CSPRes_1中不一样,需要注意。也就是说第一个CSP结构和后面的有略微差别。
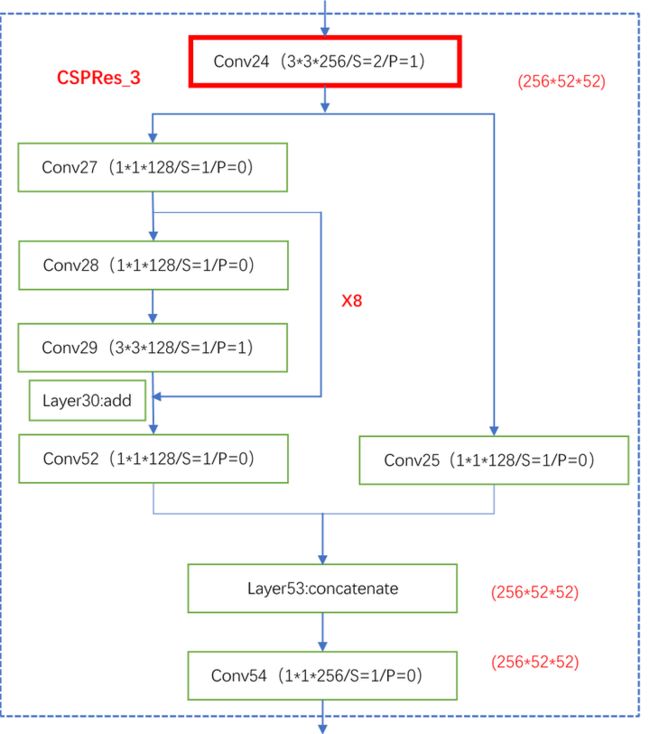
解析:x8表示有八个小的残差块,这里从Conv54得到的输出结果将会在后面再次用到。应该注意下。后面剩下的两个大块也会用到。
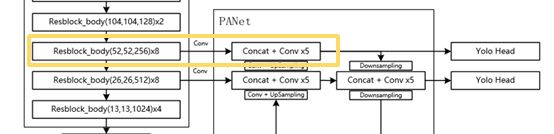
如上图黄色框区域所示。

解析:x8表示有八个小的残差块,这里从Conv85得到的输出结果也将会在后面再次用到。
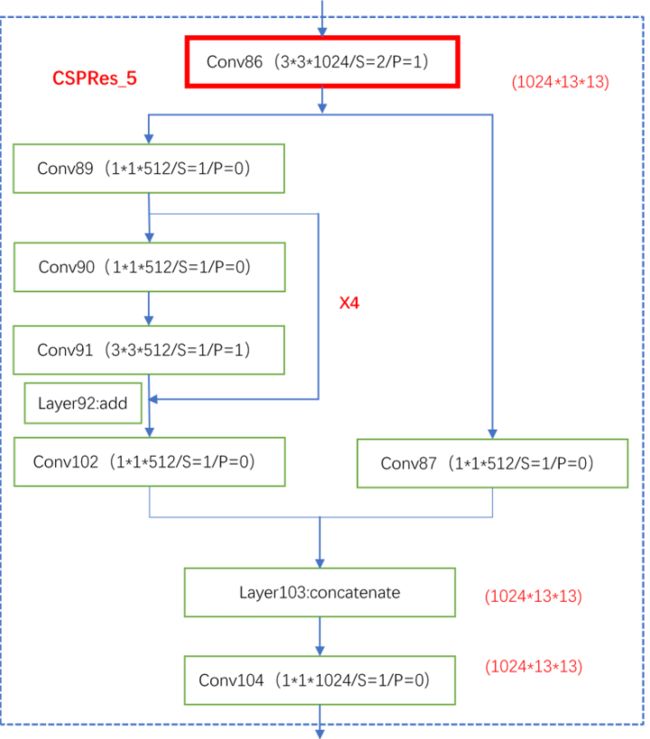
解析:x4表示四个小的残差块,这里从Conv104得到的输出结果将经过几个卷积层后直接往下接SPP层。到这里CSPDarknet53部分就算结束了,根据后面的需求我们应该明白,输入图像从CSPDarknet53出来应该是三个结果,分别为256*52*52、512*26*26、1024*13*13。因为这三个结果将用于后面的融合及上采样与下采样。
CSPDarknet53整体代码:
import torch as t
from torch import nn
from torch.nn import init
from torch.nn import functional as F
'''
写在开头:
卷积之后,如果要接BN操作,最好是不设置偏置,因为不起作用,而且占显卡内存。
'''
#Mish激活函数,自定义
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * (t.tanh(F.softplus(x)))
class FirstResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel):
super(FirstResidualBlock, self).__init__()
self.left = nn.Sequential(nn.Conv2d(inchannel, outchannel//2, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel//2),
Mish(),
nn.Conv2d(outchannel//2, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
def forward(self, x):
return x + self.left(x)
#the first Block is different from the rest of blocks
class FirstCSPNetBlock(nn.Module):
def __init__(self, inchannel, outchannel):
super(FirstCSPNetBlock, self).__init__()
self.front = nn.Sequential(nn.Conv2d(inchannel, outchannel, 3, 2, 1, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
self.right = nn.Sequential(nn.Conv2d(outchannel, outchannel, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
self.left = nn.Sequential(nn.Conv2d(outchannel, outchannel, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel),
Mish(),
FirstResidualBlock(outchannel, outchannel),
nn.Conv2d(outchannel, outchannel, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
self.cat = nn.Sequential(nn.Conv2d(outchannel * 2, outchannel, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
def forward(self, x):
x = self.front(x)
left = self.left(x)
right = self.right(x)
out = t.cat([left, right], dim=1)
out = self.cat(out)
return out
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(nn.Conv2d(inchannel, outchannel, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel),
Mish(),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
def forward(self, x):
return x + self.left(x)
class CSPNetBlock(nn.Module):
def __init__(self, inchannel, outchannel, nums_block):
super(CSPNetBlock, self).__init__()
self.front = nn.Sequential(nn.Conv2d(inchannel, outchannel, 3, 2, 1, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
self.right = nn.Sequential(nn.Conv2d(outchannel, outchannel // 2, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel // 2),
Mish())
layers = []
for i in range(nums_block):
layers.append(ResidualBlock(outchannel // 2, outchannel // 2))
self.left = nn.Sequential(nn.Conv2d(outchannel, outchannel // 2, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel // 2),
Mish(),
nn.Sequential(*layers),
nn.Conv2d(outchannel // 2, outchannel // 2, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel // 2),
Mish())
self.cat = nn.Sequential(nn.Conv2d(outchannel, outchannel, 1, 1, 0, bias=False),
nn.BatchNorm2d(outchannel),
Mish())
def forward(self, x):
x = self.front(x)
left = self.left(x)
right = self.right(x)
out = t.cat([left, right], dim=1)
out = self.cat(out)
return out
class CSPDarkNet53(nn.Module):
def __init__(self):
super(CSPDarkNet53, self).__init__()
self.prelayer = nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1, bias=False),
nn.BatchNorm2d(32),
Mish())
self.layer1 = FirstCSPNetBlock(32, 64)
self.layer2 = CSPNetBlock(64, 128, 2)
self.layer3 = CSPNetBlock(128, 256, 8)
self.layer4 = CSPNetBlock(256, 512, 8)
self.layer5 = CSPNetBlock(512, 1024, 4)
#参数初始化
import math
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.prelayer(x)
x = self.layer1(x)
x = self.layer2(x)
x3 = self.layer3(x)
x4 = self.layer4(x3)
x5 = self.layer5(x4)
return x3, x4, x5
2.SPP实现
SPP全称为Spatial Pyramid Pooling,即空间金字塔池化,网络结构如下图所示:

解析:先放代码:
#SPP
class SPPNet(nn.Module):
def __init__(self):
super(SPPNet,self).__init__()
def forward(self,x):
x1=F.max_pool2d(x,5,1,2)
x2=F.max_pool2d(x,9,1,4)
x3=F.max_pool2d(x,13,1,6)
x=t.cat([x1,x2,x3,x],dim=1)
return xSPP网络用在YOLOv4中的目的是增加网络的感受野,这里前面三个卷积层其实在后面还有类似的结构,所以在写代码时可以写成一个小模块。这三层的处理不会再改变输入图像得尺寸,最大池化为:5*5,9*9,13*13,每个最大池化结果都是512个通道,最后融合还要加上输入的x,一共有2048个通道,但是尺寸仍然不变。
3.PANet

从上图可以看出经过SPP后,通过融合和三个卷积层后开始进入PANet部分。执行顺序如箭头方向所示。首先将SPP在融合和三个卷积后的结果做一次卷积上采样后和倒数第二个CSPDarknet53模块即CSPRes_4的输出结果(也需要先做一次卷积)融合在一起,然后经过五个卷积层继续向上和向右balabala…,这里说的有点绕,看图还是比较容易明白。
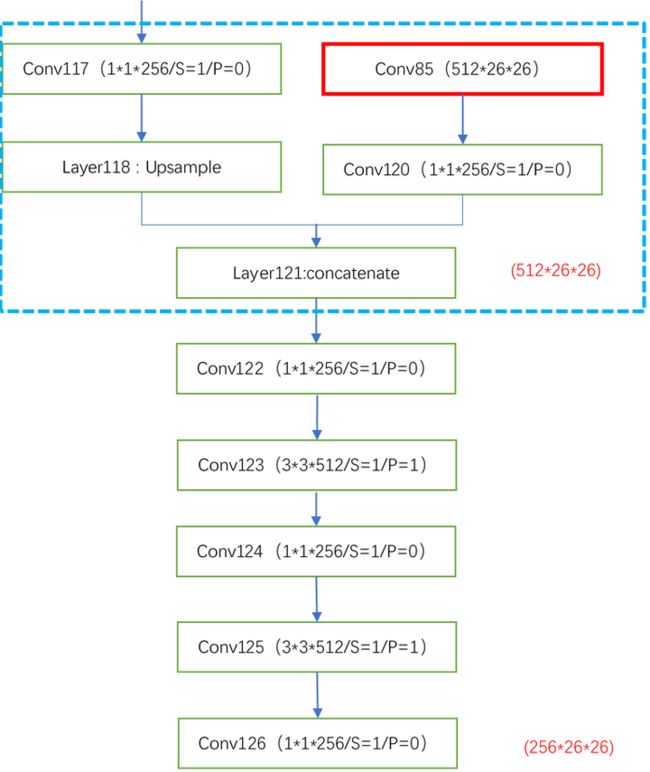
解析:前面我们说过第85层得结果将会在此用到,这里可以看出具体细节。同时前面说过输入图片尺寸应该是32的倍数,原因是当输入尺寸不正确时,这里会发生错误,出现尺寸不一样的情况,比如当上层输入为19*19,经过下采样变为10*10,若对此层进行上采用则为20*20,当将上层结果与此层结果融合时将发生错误 ,因此建议图像原始输入为608*608或416*416(32倍数都可)。之所以是32的倍数,因为我们一共下采样了五次(2的五次方)。这里的后面五个卷积层在实际编程也可以写成一个模块,因为后面还有类似的结构。
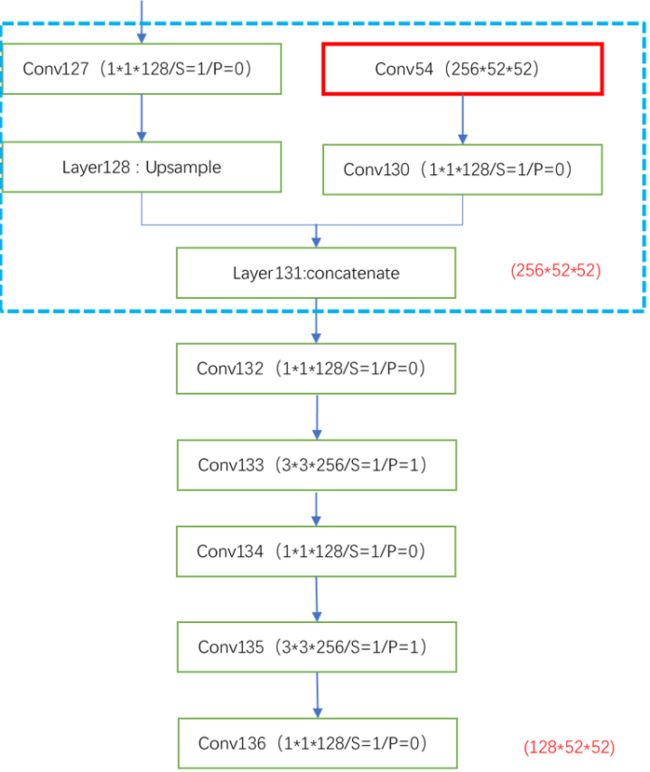
解析:再次完成上采样。经过两个卷积后这里会得到第一个输出结果,然后经过下采样后得到剩余两个结果。这里可以提前说明下,yolov4的输出为三个结果,用于预测针对不同大小的物体。
4.Yolov3Head
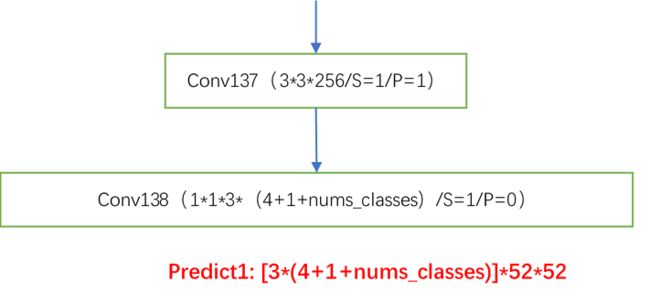
解析:这里得到第一个输出结果,为8倍下采样的结果,这个结果预测原图中的小物体。当nums_classes=80时,输出为[3*(4+1+80)]*52*52,和Yolov3的结果相似。下面这张图非常清晰。
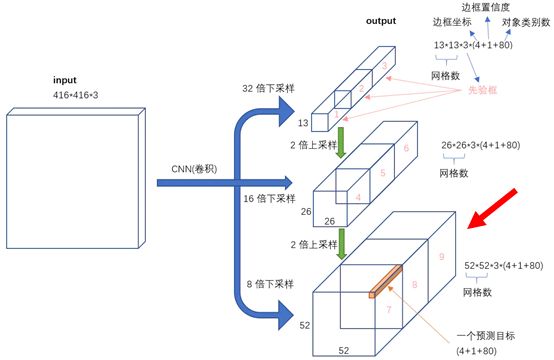
补充:说到这里,再次对网络输入与输出做一个详细的解释。当我们预测的时候,我们需要输入一个3维的彩色图像,然而我们实际输入的却是4维,为什么呢?
首先对于任意一张输入图像,我们还是需要将其缩放到我们指定的大小(这个大小可以变,32的倍数即可)。然后将图像转化为Tensor(因为我用的Pytorch框架)类型(tensor类型会将图像归一化),对于这个tensor矩阵将是我们真实输入网络的东西,但其是3维的,我们需要将其扩展到4维才能够输入网络。
这段代码说明问题:
image=Image.open(root)
image_shape=image.size
crop_img=Resize_image(image,(self.SIZE,self.SIZE))#指定大小
transform=T.Compose([T.ToTensor(),
T.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
])
img=transform(crop_img)
img=img.unsqueeze(0)#扩维之所以是4维,因为我们不管是预测还是训练阶段,我们都可以一次将多张图片输入网络,一张图片是3维,多张放一起自然就是4维,所以这里的4维代表你可以同时输入多张图片,也可以一次只有一张,但维度始终保持不变(4维)。
预测结果也是如此,三个结果,每个结果都是4维。比如一次输入两张图片,那么第一个结果表示为[2,255,52,52],第二个结果[2,255,26,26],第三个结果[2,255,13,13].当输入一张图片时第一个结果表示为[1,255,52,52]…,255=3*(4+1+80)。
再者对于一个3*416*416的输入图像,每个输出尺度的特征图的每个网格有3个预测框,总共有 13*13*3 + 26*26*3 + 52*52*3 = 10647 个预测。每一个预测是一个(4+1+80)=85维向量,这个85维向量包含预测框坐标(4个数值),边框置信度(1个数值),对象类别的概率(就COCO数据集来说,有80个对象)。
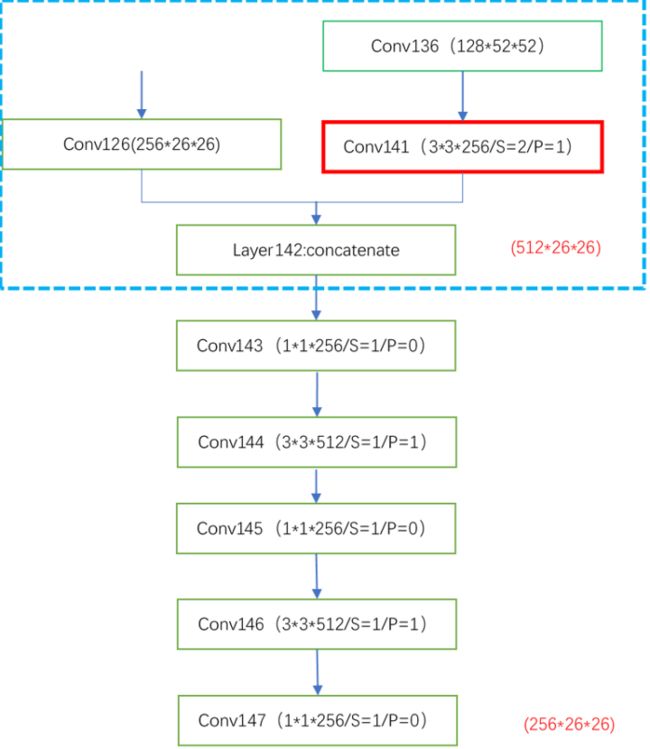
解析:上图红色框表示下采样,将采样结果卷积后和126层卷积结果融合后经过五层卷积得到的结果用于第二个预测结果。
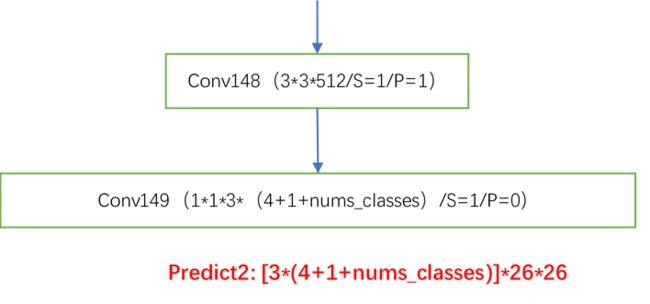
解析:这里得到第二个预测结果,这个结果主要负责预测原图中的中等大小的物体
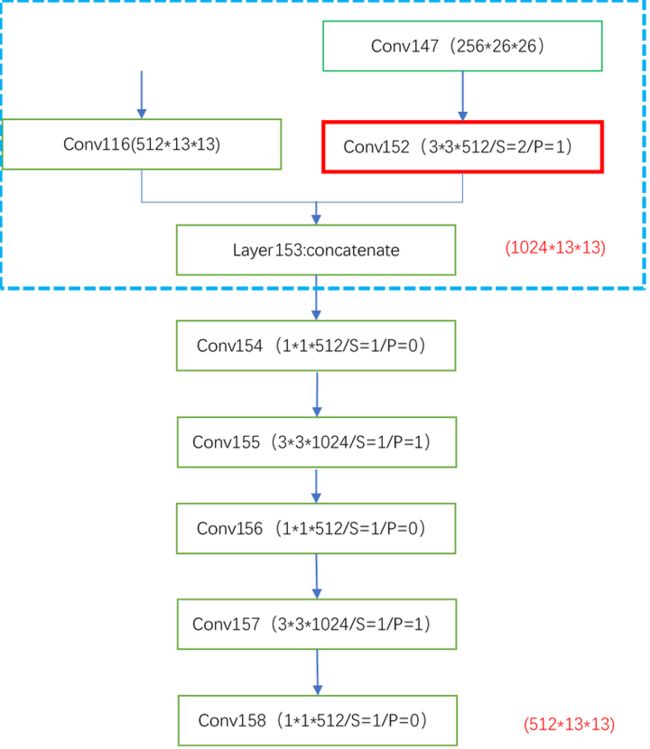
解析:红色框表示下采样。
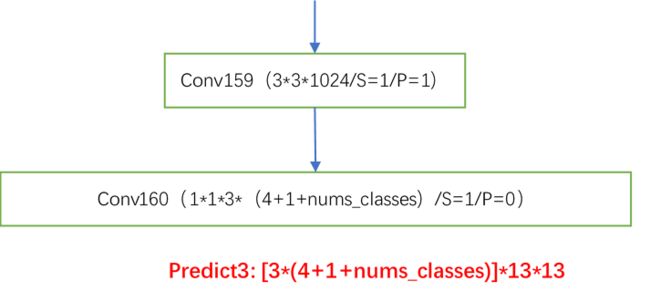
解析:这是第三个预测输出,负责预测原图中的大目标,因为下采样倍数越大,代表网络感受野越大,更合适预测在原图中出现的大目标。到此整个网络结构就算完了。
补充:以上就是Yolov4的网络结构,当我们得到三个预测结果后还需要进行后处理才能最终将结果显示在原图上。
Yolov4后部分整体代码:
import torch as t
from torch import nn
from config import config
from torch.nn import functional as F
#这里的CSPdarknet和上面有区别,不一样
from model.CSPdarknet import CSPDarkNet
from model.CSPdarknet import Mish
#SPP
class SPPNet(nn.Module):
def __init__(self):
super(SPPNet,self).__init__()
def forward(self,x):
x1=F.max_pool2d(x,5,1,2)
x2=F.max_pool2d(x,9,1,4)
x3=F.max_pool2d(x,13,1,6)
x=t.cat([x1,x2,x3,x],dim=1)
return x
#PANet
class PANet(nn.Module):
def __init__(self, inchannel, outchannel):
super(PANet, self).__init__()
self.pre=nn.Sequential(nn.Conv2d(inchannel,outchannel//2,1,1,0,bias=False),
nn.BatchNorm2d(outchannel//2),
Mish())
self.right=nn.Sequential(nn.Conv2d(inchannel,outchannel//2,1,1,0,bias=False),
nn.BatchNorm2d(outchannel//2),
Mish())
self.upsample=nn.Upsample(scale_factor=2, mode='nearest') #mode='bilinear'
def forward(self,left,right):
left=self.pre(left)
left=self.upsample(left)
right=self.right(right)
#------------------------------------------------------------------#
# 当输入尺寸不正确时,这里会发生错误,出现尺寸不一样的情况,
# 比如当上层输入为19*19,此层经过下采样变为10*10,若对此
# 层进行上采用则为20*20,当将上层结果与此层结果融合时将
# 发生错误 ,因此建议图像原始输入为608*608或416*416(32倍数都可)
#------------------------------------------------------------------#
out=t.cat([left,right],dim=1)
return out
class make_three_conv(nn.Module):
def __init__(self, inchannel,outchannel):
super(make_three_conv,self).__init__()
self.three_conv=nn.Sequential(nn.Conv2d(inchannel,outchannel,1,1,0,bias=False),
nn.BatchNorm2d(outchannel),
Mish(),
nn.Conv2d(outchannel,outchannel*2,3,1,1,bias=False),
nn.BatchNorm2d(outchannel*2),
Mish(),
nn.Conv2d(outchannel*2,outchannel,1,1,0,bias=False),
nn.BatchNorm2d(outchannel),
Mish())
def forward(self,x):
x=self.three_conv(x)
return x
class make_five_conv(nn.Module):
def __init__(self,inchannel,outchannel):
super(make_five_conv,self).__init__()
self.five_conv=nn.Sequential(make_three_conv(inchannel,outchannel),
nn.Conv2d(outchannel,outchannel*2,3,1,1,bias=False),
nn.BatchNorm2d(outchannel*2),
Mish(),
nn.Conv2d(outchannel*2,outchannel,1,1,0,bias=False),
nn.BatchNorm2d(outchannel),
Mish())
def forward(self,x):
x=self.five_conv(x)
return x
#-----------------------------------------------------------------------------------------#
# 当输入大小为608*608时如下,其它尺寸依此计算即可
# 这里得到所有输出结果,类似yolov3,其中具体表示如下:
# x3=out3; 76*76*(4+1+nums_classes)*3
# x2=x3+out2+conv*5; 38*38*(4+1+nums_classes)*3
# x1=x2+out1+conv*5; 19*19*(4+1+nums_classes)*3
# note:4代表框的坐标,1为置信度,nums_classes为类别数,3代表框的数量
# 输入从这里开始,执行model=Yolov4(),output=model(input)即可得到结果output
# 当数据输入后,执行顺序为:input-->CSPdarknet-->Yolov4(SPP-->PANet-->Yolohead)-->output
#-----------------------------------------------------------------------------------------#
class Yolov4(nn.Module):
def __init__(self,nums_classes=config.nums_classes):
super(Yolov4,self).__init__()
self.backbone=CSPDarkNet([1, 2, 8, 8, 4])
self.three_conv1=make_three_conv(1024,512)
self.neck=SPPNet()
self.three_conv2=make_three_conv(2048,512)
self.PANet1=PANet(512,512)
self.five_conv1=make_five_conv(512,256)
self.PANet2=PANet(256, 256)
self.five_conv2=make_five_conv(256, 128)
self.head3=nn.Sequential(nn.Conv2d(128,256,3,1,1,bias=False),
nn.BatchNorm2d(256),
Mish(),
nn.Conv2d(256,(4+1+nums_classes)*3,1,1,0,bias=False))
self.downsample1=nn.Sequential(nn.Conv2d(128,256,3,2,1,bias=False),
nn.BatchNorm2d(256),
Mish())
self.five_conv3=make_five_conv(512,256)
self.head2=nn.Sequential(nn.Conv2d(256,512,3,1,1,bias=False),
nn.BatchNorm2d(512),
Mish(),
nn.Conv2d(512,(4+1+nums_classes)*3,1,1,0,bias=False))
self.downsample2 = nn.Sequential(nn.Conv2d(256, 512, 3, 2, 1, bias=False),
nn.BatchNorm2d(512),
Mish())
self.five_conv4 = make_five_conv(1024, 512)
self.head1=nn.Sequential(nn.Conv2d(512,1024,3,1,1,bias=False),
nn.BatchNorm2d(1024),
Mish(),
nn.Conv2d(1024,(4+1+nums_classes)*3,1,1,0,bias=False))
#参数初始化
import math
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, input):
x3,x4,x5=self.backbone(input)
x=self.three_conv1(x5)
x=self.neck(x)
out1=self.three_conv2(x)
x=self.PANet1(out1,x4)
out2=self.five_conv1(x)
x=self.PANet2(out2,x3)
out3=self.five_conv2(x)
y3=self.head3(out3)
out3down=self.downsample1(out3)
newout2=t.cat([out2,out3down],dim=1)
newout2=self.five_conv3(newout2)
y2=self.head2(newout2)
out2down=self.downsample2(out2)
newout1=t.cat([out1, out2down], dim=1)
newout1=self.five_conv4(newout1)
y1=self.head1(newout1)
return y1, y2, y3(未完待续......)
参考:
[1] YOLOv4: Optimal Speed and Accuracy of Object Detection
https://www.jianshu.com/p/d13ae1055302
https://blog.csdn.net/weixin_41560402/article/details/106119774