【1】k近邻分类
k近邻分类算法最简单的就是考虑一个最近邻,也就是考虑离我们预测的点最近的那一个训练点。预测结果就是这个训练点的分类标签。
这里演示使用了mglearn库,该库集成了sklearn和数据的许多操作方法,很便于获取对应数据。
import numpy as np
import pandas as pd
import mglearn
import matplotlib.pyplot as plt
mglearn.plots.plot_knn_classification(n_neighbors=1)
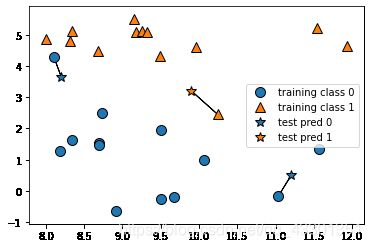
图中3个五角星为3个预测点,每个预测点用线段连到离它最近的训练点上,即为预测的类别。
当然,也可以考虑k个邻居,那当这k个邻居的标签不一样时,该如何确定这个测试点属于哪一类呢?使用投票法,即哪个邻居的占比大,就将该测试点标记为那个邻居的类别。
下面使用3个近邻演示,
mglearn.plots.plot_knn_classification(n_neighbors=3)
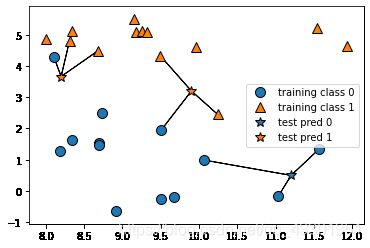
该图演示的是二分类问题,但该方法同样适用于多分类问题,以每个类别的占比大小来进行预测就好。
下面使用scikit-learn来应用k近邻算法。
from sklearn.model_selection import train_test_split
X,y = mglearn.datasets.make_forge()
#将数据集划分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=0)
#导入k近邻分类器
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
#对分类器clf实施训练
clf.fit(X_train,y_train)
#使用predict函数对测试集进行预测
print('测试集预测结果为:{}'.format(clf.predict(X_test)))
输出
测试集预测结果为:[1 0 1 0 1 0 0]
使用score方法来评价模型的好坏
print('测试集准确度:{:.2f}'.format(clf.score(X_test,y_test)))
输出
测试集准确度:0.86
对于二维数据集,可以画出分类边界,下面针对邻居个数为1、3、9三种情况进行决策边界可视化
fig,axes=plt.subplots(1,3,figsize=(10,3))
for n_neighbors,ax in zip([1,3,9],axes):
#fit方法是对对象本身的操作,所以可以将实例化和训练放在同一行代码中
clf=KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y)
#画分类边界
mglearn.plots.plot_2d_separator(clf,X,fill=True,eps=0.5,ax=ax,alpha=.4)
#画训练样本点散点图
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
ax.set_title('{}neighbor(s)'.format(n_neighbors))
ax.set_xlabel('feature 0')
ax.set_ylabel('feature 1')
axes[0].legend(loc=3)
输出

由图可以看出,邻居越多,决策边界越平滑,训练出的模型愈简单。模型愈简单,意味着泛化能力越强。下面使用乳腺癌数据集来研究模型复杂度与泛化能力的关系。
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(
cancer.data,cancer.target,stratify=cancer.target,random_state=66)
training_accuracy=[]
test_accuracy=[]
# n_neighbors取值从1到10
neighbors_settings=range(1,11)
for n_neighbors in neighbors_settings:
#构建模型
clf=KNeighborsClassifier(n_neighbors=n_neighbors).fit(X_train,y_train)
#记录训练集精度
training_accuracy.append(clf.score(X_train,y_train))
#记录泛化精度
test_accuracy.append(clf.score(X_test,y_test))
plt.plot(neighbors_settings,training_accuracy,label='training accuracy')
plt.plot(neighbors_settings,test_accuracy,label='test accuracy')
plt.ylabel('Accuracy')
plt.xlabel('n_neighbors')
plt.legend()
train_test_split函数中的stratify是为了保持split前类的分布。比如有100个数据,80个属于A类,20个属于B类。如果train_test_split(… test_size=0.25, stratify = y_all), 那么split之后数据如下:
training: 75个数据,其中60个属于A类,15个属于B类。
testing: 25个数据,其中20个属于A类,5个属于B类。
用了stratify参数,training集和testing集的类的比例是 A:B= 4:1,等同于split前的比例(80:20)。
通常在这种类分布不平衡的情况下会用到stratify。
输出如下:
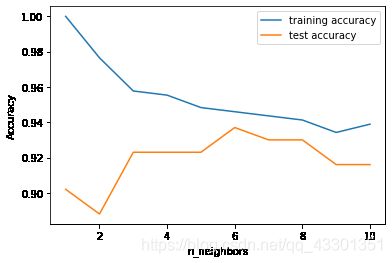
从这张图里可以看出训练精度与测试精度之间的大致关系。