python爬取图片_python爬取萌萌柴犬图片
前面刚学过正则表达式,那我们趁热打铁实战一下。今天,数据媛为大家带来python利用request库和re库爬取柴犬表情包的爬虫实战。 目录如下:

 图片和视频的爬取和文本的有些不一样,我们想要下载图片或视频,就需要首先知道图片或视频的链接,然后通过图片的链接获取图片二进制代码,然后将二进制代码下载到本地,这样一般的图片和视频就到了本地了。
图片和视频的爬取和文本的有些不一样,我们想要下载图片或视频,就需要首先知道图片或视频的链接,然后通过图片的链接获取图片二进制代码,然后将二进制代码下载到本地,这样一般的图片和视频就到了本地了。
 害,还是有反爬机制的 所以,慢慢找反爬方式,首先需要获取浏览器的请求头。
害,还是有反爬机制的 所以,慢慢找反爬方式,首先需要获取浏览器的请求头。



什么是爬虫
爬虫是什么
网络爬虫,又叫网页蜘蛛和网络机器人。就是模拟浏览器去访问和获取互联网上信息的一个程序。 实质上也是一种检索信息的方式。爬虫的应用
有一种说法说,网络流量中, 50%的流量都是爬虫创造的 。所以,爬虫的应用,远比我们想象中更广泛更多。 爬虫可以帮助我们快速、规模化地获得网络上的数据,而且,实际上一些开源信息的网页并不反对爬虫来获取信息。 但是,既然叫做 虫 ,那说明互联网世界也并不欢迎它,我们制作爬虫除了遵守robots.txt 的君子协定,我们还需要尽量少用爬虫,不商用爬虫等行业潜规则,慎用技术。
爬虫的分类
通用网络爬虫
百度、谷歌、雅虎等搜索引擎 特点:关键字获取既定的目标,覆盖率很大聚焦网络爬虫
爬取有更新到的内容 特点:到互联网上有选择去抓取特定的目标和相关的主题内容增量式网络爬虫
特点:只采取增量式个更新或者是只爬取新产生的或者是已经发生变化的网页深层网络爬虫
表层:一般看到的内容 深层:大部分内容是不可以通过静态链接获取的,隐藏在搜索表单之后ode一些数据,可能需要用户提交一些关键词可以获得的web页面。爬取表情包
分析目标数据
网页地址
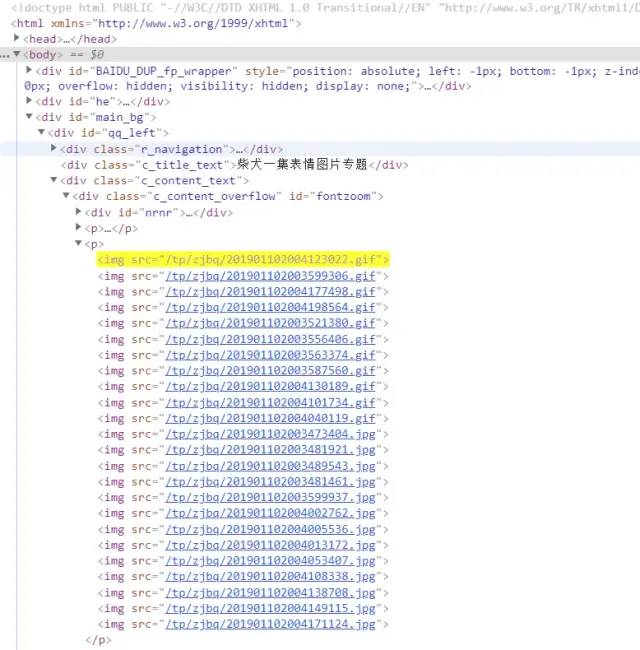
打开网址 https://qq.yh31.com/zjbq/1094990.html ,这是柴犬的表情包专题,我们将计划用Python一键爬取这些柴犬表情包,丰富我们的推文。
图片链接地址
快速查到图片的代码位置
复制其中一个图片的地址,在源代码中ctrl+f 定位到图片的位置
图片和视频的爬取和文本的有些不一样,我们想要下载图片或视频,就需要首先知道图片或视频的链接,然后通过图片的链接获取图片二进制代码,然后将二进制代码下载到本地,这样一般的图片和视频就到了本地了。
确定爬虫思路
request库get()网页源代码re库的findall()获取图片链接通过图片链接
get()二进制代码
编写代码
获取网页源代码
这个表情包网站看起来比较一般,应该容易爬到,不会反爬吧。而且我的数据量这么小。所以我就直接使用request 库
get ,没有伪造
headers 。
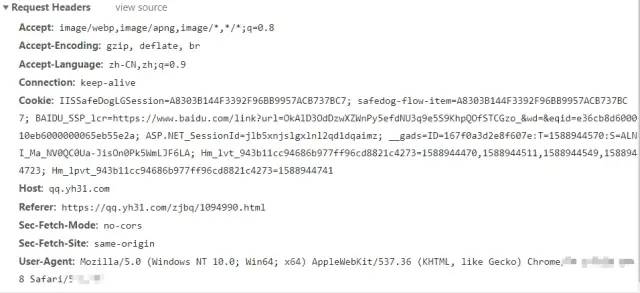
response = requests.get('https://qq.yh31.com/zjbq/1094990.html')F12 +点击
Network 刷新页面,抓包其中一个图片的链接,然后得到浏览器请求头。将其添加到
get() 中。
def get_url(header): response = requests.get('https://qq.yh31.com/zjbq/1094990.html',headers=header)解析图片地址
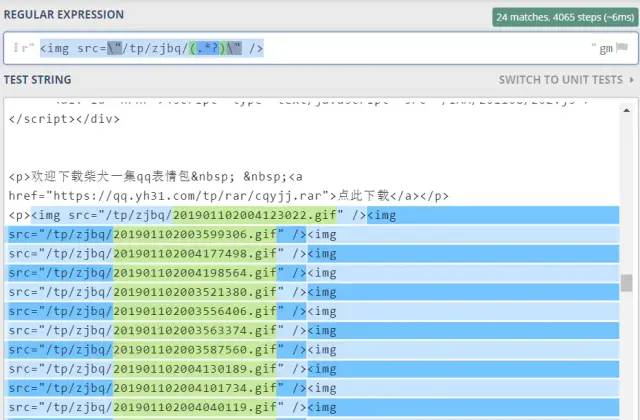
今天使用的是正则表达式来获取链接地址,当然也可以使用xpath 、
beautifulsoup 都可以解析。
pattern = r''# .*?意思是提取尽可能少的许多内容 pic_re_url = re.findall(pattern, response.text)re 库。
获取二进制图片代码
将上面所获得的图片链接,一个一个爬取。 注意这里二者的区别response.text 意为获取网页源代码
response.content 意为获取二进制代码
def get_pic(header,one_url,name): response = requests.get(one_url,headers=header) response.content写入文件夹中
这里使用with 语句来读写文件,要给每个图片命名,所以使用了前面数据媛讲过的%的妙用。
with open(r'D:\0code\HSS_data\20200508-emoji_spider\emoji\%d.gif'%name,'wb') as f: f.write(response.content)编写函数
然后,就是将以上步骤封装为函数,以便清晰地调用啦! 最后得到一个个萌萌的柴犬!
小结:
request库get()网页源代码re库的findall()获取图片链接通过图片链接
get()二进制代码for循环遍历url列表进行逐个爬取with语句和%d生成文件名