Python爬虫获取“房天下“房价数据(上)
上期博客我们通过Python爬虫获取了京东商城的手机价格及其详细配置数据, 这期我们试着通过爬虫在房天下(房天下乌鲁木齐网址)上获取乌鲁木齐的二手房信息, 同时利用之前已经测试过的坐标查询代码来获得每一个二手房的详细位置.
分析URL
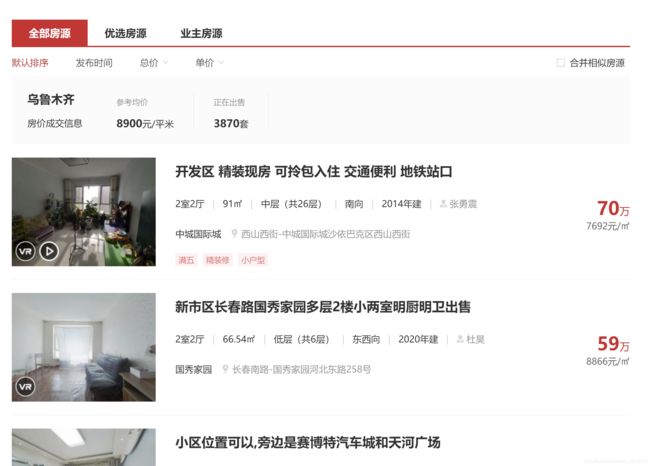
进入二手房的销售列表URL, 其中包括房屋的售卖标题、户型、面积、楼层情况、朝向、建成年份、售价、位置等信息. 那么本期就先从房屋的基本属性开始爬取, 关于其详细信息的爬取会在(下)中给出.
- 进入开发者工具
不难看出, 存放这些信息的标签很容易就可以找到, 那么就很容易了, 先给出结果:
import numpy as np
import matplotlib.pyplot as plt
import os
import pandas as pd
from bs4 import BeautifulSoup
import requests
import time
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
#https://xj.esf.fang.com/house/i31/ http example
#url = 'https://xj.esf.fang.com'
meanUrl = "https://xj.esf.fang.com/house/i31"
meanPage = requests.get(meanUrl, headers=headers)
print("页面状态码:{0}".format(meanPage.status_code))
soup = BeautifulSoup(meanPage.text, "html.parser")
tag = soup.find_all("script")[3]
a = str(tag).find("rfss")
var_t4 = meanUrl
var_t3 = str(text)[a:a + 28]
newUrl = var_t4 + "?" + var_t3
print("当前访问为 {0}:".format(newUrl))
newPage = requests.get(newUrl, headers=headers)
newSoup = BeautifulSoup(newPage.text, "html.parser")
#print(newSoup)
fangData = []
attrs = ["户型", "面积", "楼层", "朝向", "建成时间", "经纪人", "地址", "单价"]
df = pd.DataFrame(columns=attrs)
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join(
["\033[31m%s\033[0m" % ' '] * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(
percent * 100) + end_str
print(bar, end='', flush=True)
n = 10
for i in range(n):
try:
p = newSoup.find_all("dl", {
"class": "clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p", {
"class": "add_shop"})[i] #地址信息
info = p.text.replace("\t", "").replace("\n",
"").split("|") #信息汇总(list)
price = newSoup.find_all("dd", {
"class": "price_right"})[i] #单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df.loc[i] = info
except:
pass
end_str = '100%'
process_bar(i/(n-1), start_str='', end_str=end_str, total_length=15)
newDf = df.reset_index(drop=True)
print(newDf)
运行结果

代码中坐标查询部分可以查看我的这期博客: 通过Python实现目标点经纬度的自动查询.
- tips
需要注意的是我只爬取了第一页上的房价信息, 而在代码中给出URL则是https://xj.esf.fang.com/house/i31而不是开始提到的https://xj.esf.fang.com/
这是因为在测试代码的过程中, 我发现上述两个URL都指向第一页的内容, 但两者给出的商品房信息则是不尽相同的, 下图是https://xj.esf.fang.com/house/i31给出的内容(从第二条信息开始就不相同了)
另外一点. 当我们通过request.get方法来访问https://xj.esf.fang.com/house/i31时是无法获得上述图片中的信息的, response对象被指向了其他的URL, 内容为
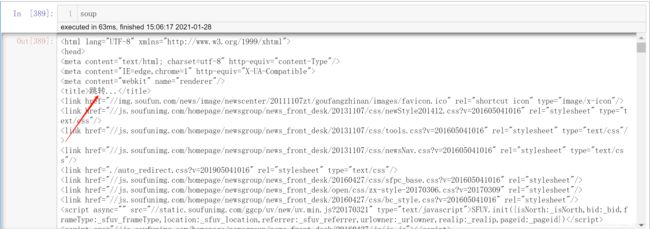
显然URL发生了跳转, 那么跳转后的地址是什么呢?其实通过浏览器来访问https://xj.esf.fang.com/house/i31就会得到跳转后的URL为https://xj.esf.fang.com/house/i31?rfss=1-44a29fbb0a420c8e8b-38, 显然这是一个反爬虫策略, 我们是否在每次访问列表的时候都要手动获取跳转后的URL呢?当然不是, 不然爬虫就失去了意义. 让我们来分析这个错误的URL
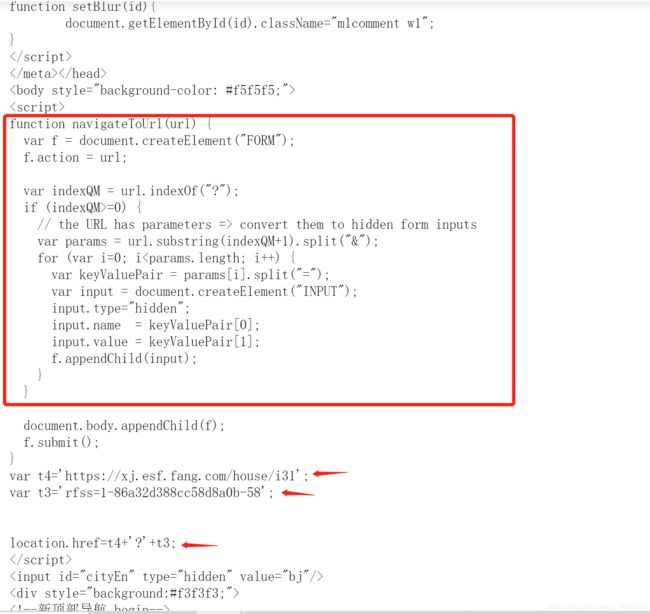
显然这段JS代码中的**function navigateToUrl(url)**就是为访问地址提供加密服务. 下面的var t4、var t3正是加密后的结果, 所以跳转后的URL为t4 + ? + t3. 那么直接上代码把它抓下来
tag = soup.find_all("script")[3]
a = str(tag).find("rfss")
var_t4 = meanUrl
var_t3 = str(text)[a:a + 28]
newUrl = var_t4 + "?" + var_t3
这样就能保证正确的访问我们需要的URL了
在爬取的过程中还存在着另外一个问题, 即有些标签内并不含有我们需要的信息, 导致find_all()无法返回结果就会报错, 所以我们采用try except的代码形式来跳过错误或不完整信息
try:
p = newSoup.find_all("dl", {
"class": "clearfix"})[i].dd.p #首页信息
span = newSoup.find_all("p", {
"class": "add_shop"})[i] #地址信息
info = p.text.replace("\t", "").replace("\n",
"").split("|") #信息汇总(list)
price = newSoup.find_all("dd", {
"class": "price_right"})[i] #单价
info.append(span.span.text)
info.append(price.span.next_sibling.next_sibling.text)
time.sleep(0.5)
df.loc[i] = info
except:
pass
这虽然能保证代码的正常运行, 但跳过一些标签也导致了最后返回DataFrame时数据的索引并不是无间断排序的, 所以还需要加一段
newDf = df.reset_index(drop=True)
来使索引重新排序. 这样一页内容的爬取就完成了, 其他页内的内容只需要在此基础上加上一个循环, 将https://xj.esf.fang.com/house/i31按i32 i33 i34的顺序循环即可.
- 一点说明
def process_bar(percent, start_str='', end_str='', total_length=0):
bar = ''.join(
["\033[31m%s\033[0m" % ' '] * int(percent * total_length)) + ''
bar = '\r' + start_str + bar.ljust(total_length) + ' {:0>4.1f}%|'.format(
percent * 100) + end_str
print(bar, end='', flush=True)
这段代码是加入了爬取的进度条, 并不是出于美观, 而是大规模爬虫时进度条能很快的反映程序有没有出错, 错误在哪一次循环, 好让我们快速的debug.