这是Jerry 2021年的第 12 篇文章,也是汪子熙公众号总共第 283 篇原创文章。
今天是2021年1月20日,看看历史上的今天都发生了什么。
2004年1月20日,第一个公开版本的Scala发布。

Scala是一种采用静态类型系统的编译型语言,具有很强的可扩展性(Scalability),这也是其名称的由来。
Scala设计初衷是集成面向对象编程和函数式编程的各种特性,运行于JVM平台上,并兼容已有的Java程序。

Jerry没有在SAP标准产品开发中使用过Scala,只是完成2015年公司一个内部培训布置的课程作业中,使用Scala在Spark上开发了一个最简单的demo:统计海量英文图书里,计算出使用频率最高的十大单词。

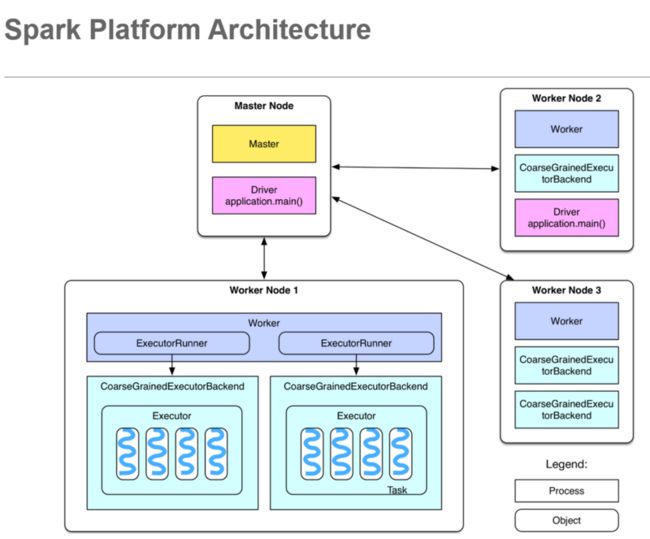
Spark是一个使用Scala编程语言实现的专为大规模数据处理而设计的快速通用的计算引擎。本文不会讨论Spark,而是从Scala语言里,下图第11行的注解@tailrec谈起:尾递归(Tail Recursion).
每个程序员对递归的概念都耳熟能详,那什么是尾递归呢?
顾名思义,如果一个函数中递归形式的调用,出现在函数的末尾,且除了该递归调用外,不包含其他的运算操作,则我们称该递归函数是尾递归函数。
本文用阶乘算法来介绍尾递归的概念。
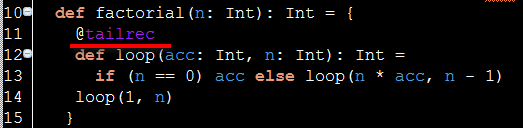
下图红色区域内是阶乘算法的常规递归实现,蓝色区域是阶乘算法的尾递归实现版本。在常规递归算法的末尾,第8行语句(绿色),除了递归调用factorial函数外,还包含一个同n的乘法操作,所以整个函数factorial不能算作尾递归函数。
而尾递归版本中,第14行函数末尾(黄色),仅仅包含函数本身的递归调用,所以整个函数tailFactorial是一个尾递归函数。
尾递归函数存在的意义是什么呢?要回答这个问题,我们可以先在单步调试模式下,观察常规递归函数的执行过程。
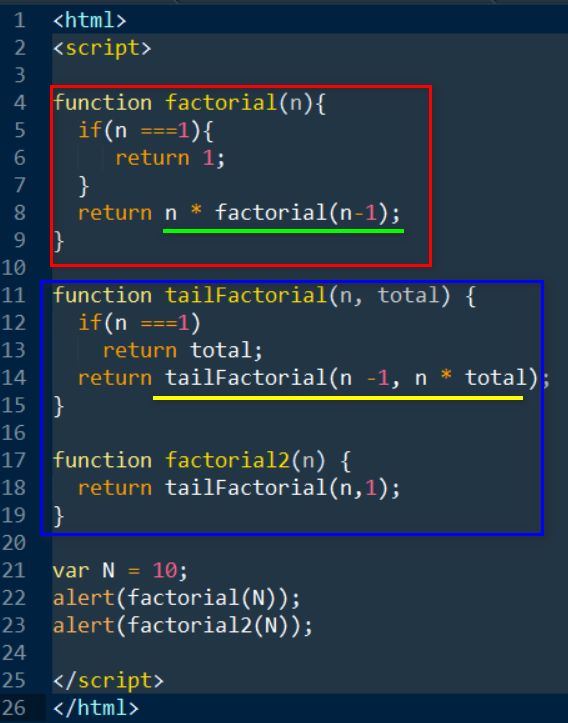
我们首先使用常规递归函数,计算5的阶乘。
输入参数n为5,执行到第7行,5的阶乘等于5乘以4的阶乘。单步调试进去,输入参数n = 5, 进入第7行,准备执行 5 * factorial(4) .

注意观察下图的Call Stack列表,此时我们已经有两个factorial函数的调用栈帧了。
什么是栈帧?复习一下大学计算机原理学到的知识:在函数执行过程中,每一个函数调用都会把当前函数的调用信息和内部变量保存在栈里面,称为一个栈帧(Stack Frame).
其中下图序号为1的栈帧,保存了n = 5的计算上下文;序号为2的栈帧即当前最顶层的栈帧,保存了n = 4的计算上下文。
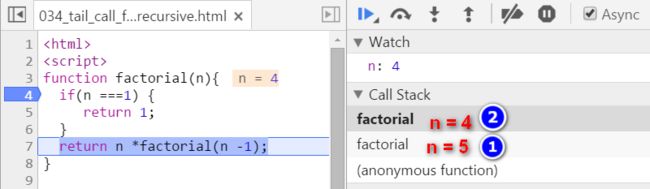
因为只有当n = 1时递归才会结束,而当前n = 4,所以继续单步调试第7行:又生成了一个n = 3的栈帧:
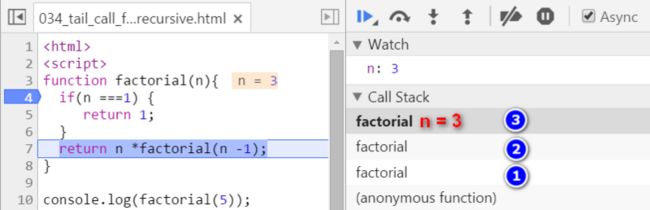
n = 2:
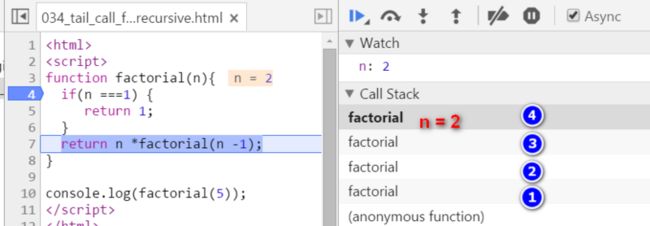
终于我们来到了n = 1的上下文。看下图Call Stack里的栈帧列表,最顶层的栈帧代表当前n = 1的计算上下文。此时我们已经知道n = 1的阶乘结果如何计算了,即为1本身。
第5行代码返回1的阶乘计算结果1,这行语句返回之后,当前序号为5的栈帧就会被销毁,即将回到下一层序号为4的栈帧去。
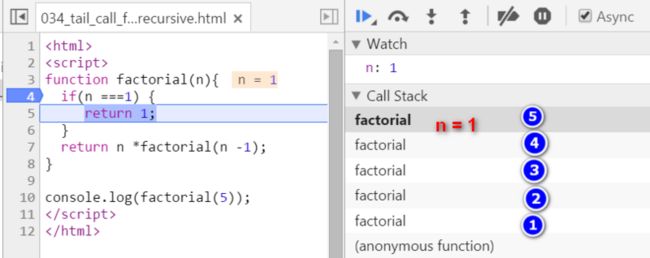
此时只剩4个栈帧了,最顶层代表n = 2的栈帧。因为现在1的阶乘结果已经出来了,所以2的阶乘结果也能计算了,为2乘以1.
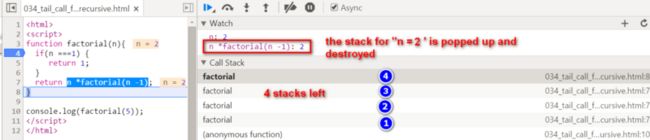
2的阶乘返回后,现在只剩3个栈帧,最顶层为n = 3的计算上下文。3的阶乘也能计算了,为3乘以前一个栈帧返回的计算结果,即2的阶乘结果,所以最后为3 × 2 = 6. 如下图所示:

4的阶乘计算,此时只剩两个栈帧:
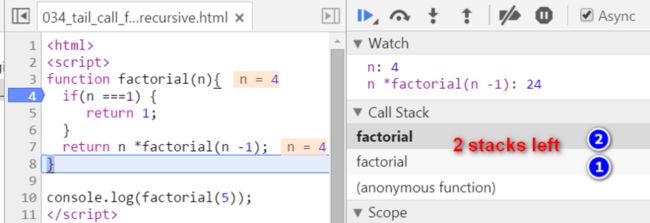
5的计算结果,回到最初最先被压到堆栈底部的n = 5的栈帧。计算完毕,5的阶乘为120.
是不是体现出了《数据结构》教科书上关于栈“先进后出”的工作原理?
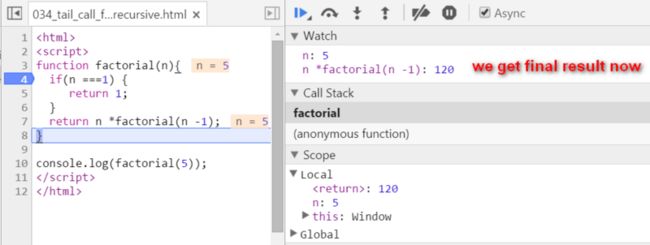
下面再来看看用尾递归实现的阶乘。
下图第20行语句是以尾递归方式计算5的阶乘入口,调用尾递归函数tailFactorial,注意函数的第二个输入参数total,这个参数用于存储当前阶乘的计算结果。

这个尾递归函数的结束条件是,当第一个输入参数n为1时,就把第二个输入参数的值,作为阶乘运算的最终结果返回。第二个参数实际上存放的,是当前递归调用的阶乘计算结果。
当n大于1时,递归尚未满足退出条件,此时首先将n和当前的阶乘计算结果(变量total)相乘,将乘积作为第二个输入参数,传递到下一层递归调用的栈帧中去。
下图是tailFactorial函数内部,即将进入第一轮递归调用的栈帧:

第一轮递归调用的栈帧内部,序号为2.
注意,此时序号为1的栈帧已经完全不再需要了,因为我们继续进行递归调用的所需信息,都已经包含在第16行tailFactorial调用的两个输入参数里了,此时n为上一层递归调用传入的5 - 1 = 4,total为上一轮传入的5 × 1 = 5. 进行下一轮递归调用,两个输入参数的值分别是4 - 1 = 3和4 * 5 = 20.
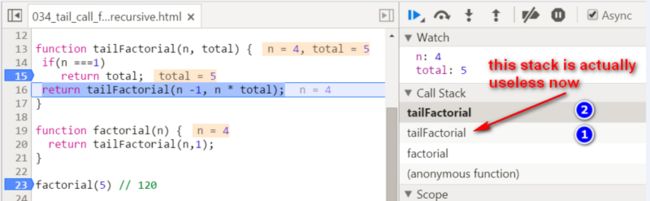
进入第三层递归调用,此时输入参数 n = 3,total = 20,均为上一层调用传入。
注意,下图标号为1和2的两个栈帧,实际上不再需要了,因为要继续进行递归调用的所有输入信息,都已经存储在标号为3的栈帧里了:

n = 2, total = 60,同理,标号为1,2,3的栈帧都不再需要了。
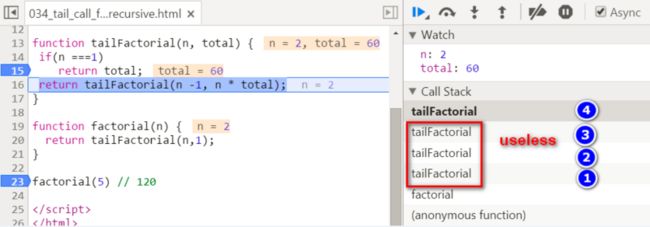
n = 1,total = 120,终于计算结束了!这就是5的阶乘,如何通过尾递归的方式计算出来的全过程。
我们在标号为5的栈帧里得到了最终的结果,而此时虽然栈帧1~4还存在,但实际上已经毫无用处了。
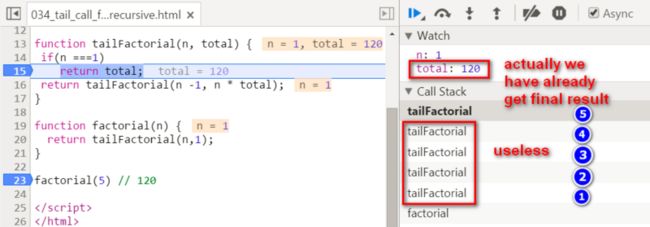
因为按照尾递归版本的阶乘实现,每一轮阶乘的递归计算结果,已经通过第二个参数total保存了下来,因此没有必要再用一个完整的栈帧,去保存当前这轮递归计算的函数调用上下文了。这就引出了所谓“尾递归优化”的概念:
When a compiler detects a call that is tail recursive, it overwrites the current activation record instead of pushing a new one onto the stack. The compiler can do this because the recursive call is the last statement to be executed in the current activation; thus, there is nothing left to do in the activation when the call returns. Consequently, there is no reason to keep the current activation around. By replacing the current activation record instead of stacking another one on top of it, stack usage is greatly reduced, which leads to better performance in practice. Thus, we should make recursive functions tail recursive whenever we can.
https://www.oreilly.com/libra...
上述文字大意如下:
当(C语言)编译器检测到尾递归调用时,并不会创建新的栈帧并压入栈中,而是用新的栈帧覆盖掉当前处于激活状态的栈帧。编译器之所以能够这样做,是因为尾递归函数里,递归调用是当前栈帧里最后一个需要执行的函数调用。被覆盖掉的栈帧本身毫无用处,不需要再保留。采用栈帧覆盖,而不是新建栈帧的方式,极大程度上减少了栈帧的个数,提高了递归函数的执行性能。因此,应该尽可能地去尝试使用尾递归方式实现递归函数。
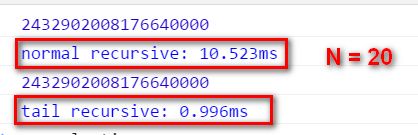
一个实际的性能比较例子:计算20的阶乘,二者的性能有巨大差异:普通递归实现需要10毫秒,而尾递归实现仅仅需要不到1毫秒的时间。
注意:一个递归函数能否用尾递归方式实现,和它能否享受运行时的尾递归优化,二者不是一回事,后者需要编译器的支持。
应用开发人员通过Scala提供的@tailrec注解,告诉编译器,对注解修饰的方法进行尾递归优化:

如果优化失败,或者被修饰的方法根本就不是一个尾递归函数,则编译器报错:
could not optimize @tailrec annotated method fibonacci: it contains a recursive call not in tail position
用ABAP实现尾递归版本的阶乘运算:
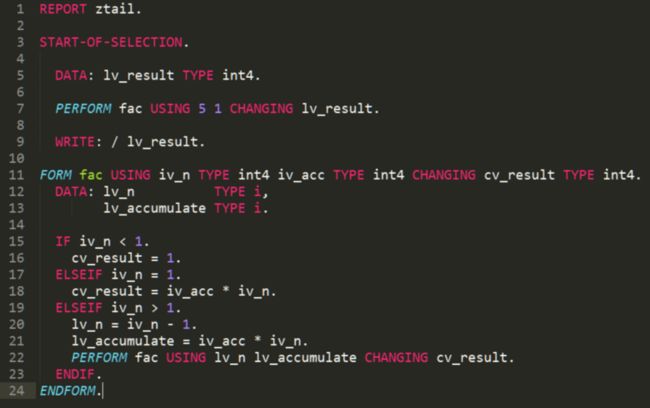
至于ABAP编译器能否支持尾递归优化?我没有研究过,我只是觉得,尾递归优化并不能算是ABAP编译器必须实现的需求之一。
希望本文能帮助大家对尾递归优化这个概念有一个最基本的认识,感谢阅读。
ABAP专题
- Jerry的ABAP, Java和JavaScript乱炖
- ABAP开发人员未来应该学些什么
- Jerry 2017年的五一小长假:8种经典排序算法的ABAP实现
- Jerry的ABAP原创技术文章合集
- 300行ABAP代码实现一个最简单的区块链原型
- 使用Java+SAP云平台+SAP Cloud Connector调用ABAP On-Premise系统里的函数
- 在SAP云平台的CloudFoundry环境下消费ABAP On-Premise OData服务
- ABAP vs Java, 蛙泳 vs 自由泳
- 聊聊C语言和ABAP
- 动手使用ABAP Channel开发一些小工具,提升日常工作效率
- 我用ABAP做过的那些无聊的事情
- 不喜欢SAP GUI?那试试用Eclipse进行ABAP开发吧
- 使用Visual Studio Code编写和激活ABAP代码
- 你的ABAP程序给佛祖开过光么?来试试Jerry这个小技巧
- 在SAP云平台ABAP编程环境上编写第一段ABAP程序
- SAP官方发布的ABAP编程规范
- ABAP Code Inspector那些隐藏的功能,您都知道吗?
- 还在用ABAP进行SAP产品的二次开发?来了解下这种全新的二次开发理念吧
- ABAP Netweaver体内的那些寄生式编程语言
- 从SAP社区上的一篇博客开始,聊聊SAP产品命名背后的那份情怀
- 云端的ABAP Restful服务开发
- 如何在SAP云平台ABAP编程环境里把CDS view暴露成OData服务
- 使用abapGit在ABAP On-Premises系统和SAP云平台ABAP环境之间进行代码传输
- 30分钟用Restful ABAP Programming模型开发一个支持增删改查的Fiori应用
- Jerry带您了解Restful ABAP Programming模型系列之二:Action和Validation的实现
- Jerry带您了解Restful ABAP Programming模型系列之三:云端ABAP应用调试
- SAP云平台上的ABAP编程环境里如何消费第三方服务
- ABAP开发者上云的时候到了 - 现在大家可以免费使用SAP云平台ABAP环境的试用版了
- 学而不思则罔 - SAP云平台ABAP编程环境的由来和适用场景
- SAP云平台里的三叉戟应用
- 如何基于Restful ABAP Programming模型开发并部署一个支持增删改查的Fiori应用
- SAP 2019 TechEd Key Note解读:云时代下SAP从业人员如何做二次开发?
- 有哪些ABAP关键字和语法,到了ABAP云环境上就没办法用了?
- ABAP开发环境终于支持以驼峰命名法自动格式化ABAP变量名了
- 利用ABAP 740的新关键字REDUCE完成一个实际工作任务
- 一段让人瑟瑟发抖的ABAP代码
- 昨日万圣节ABAP怪兽级代码谜团,公布答案啦
- 介绍一种在ABAP内核态进行内表高效拷贝的方法
- 使用SAP Cloud Application Programming模型开发OData的一个实际例子
- 当ABAP遇见普罗米修斯
- 使用ABAP绘制可伸缩矢量图
- ABAP开发环境语法高亮的那些事儿
- SAP错误消息调试之七种武器:让所有的错误消息都能被定位
- 使用ABAP操作Excel的几种方法
- SAP GUI里的收藏夹事务码管理工具
- SAP GUI和Windows注册表
- 有了Debug权限就能干坏事?小心了,你的一举一动尽在系统监控中
- ABAP CCDEF, CCIMP, CCMAC, CCAU, CMXXX这些东东是什么鬼
- 实现ABAP条件断点的三种方式
- 使用SAT跟踪监控从浏览器打开的SAP应用的性能和调用栈
- 一个13年ABAP老兵的建议:了解这些基础知识,对ABAP开发有百利而无一害
- SAP ABAP Netweaver容器化, 不可能完成的任务吗?
- SAP产品增强技术回顾
- SAP API开发方法大全
- 浅谈Java和SAP ABAP的静态代理和动态代理,以及ABAP面向切面编程的尝试
- SAP ABAP应用服务器的HTTP响应状态码(Status Code)
- SAP ABAP里存在Java List这种集合工具类么?CL_OBJECT_COLLECTION了解一下
- ABAP面试题系列:写一组会出现死锁(Deadlock)的ABAP程序
- SAP ABAP Netweaver服务器的标准登录方式讲解
- SAP ABAP关键字语法图和ABAP代码自动生成工具Code Composer
- SAP ABAP SM50的另类用途 - ABAP工作进程对数据库表读取操作的检测
- 关于SAP ABAP字符变量和字符串变量字符个数的一个知识点,和一个血案
- SAP ABAP一组关键字 IS BOUND, IS NOT INITIAL和IS ASSIGNED的用法辨析
- SAP ABAP和Java里的弱引用(WeakReference)和软引用(SoftReference)
- SAP AMDP介绍 - ABAP托管的HANA数据库过程
- 给你的ABAP对象打上标签(Tag)
- 历史上的今天:编程语言中null引用的十亿美元错误
更多Jerry的原创文章,尽在:"汪子熙":