论文阅读-Going Deeper with Convolutions
作者: Christian Szegedy(贾扬清大神是三作哦)
日期: 2015
类型: conference article
来源: CVPR
评价:
论文链接:
1 Purpose
The efficiency fo the algorightms matters, especially on mobile and embedded devices. The author’s aim is to improve the utilization of the computing resources inside the network.
3 The proposed method
The author propose a deep convolutional neural network architecure codenamed Inception.
3.1 Advantages:
- State of the art: Their GoogleNet submission to ILSVRC2014 actually use 12 times fewer parameters than the winning architecture of Krizhevsky(AlexNet) in 2012, while being significantly more accuracy(Top-5 error rate: 6.67%)
- reasonable cost: the model keep a computational budget of 1.5billion multiply-adds at inference time, so that it do not end up to acacemic curiosity, but could be put to real world use, even on large datasets.(The author claimed)
- One an utilize the Inception architecture to create slightly inferor, but computationally cheaper versions of original model.
- The inference can be run on individual devices including even those with limited computational resources.
3.2 Related Work
- recent trend:
- M. Lin et al. Network in network. CoRR, 2013.
- M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. ECCV, 2014
- P. Sermanet et al. Overfeat: Integrated recognition, localization and detection using convolutional networks. CoRR, 2013.
- Inspiration:
- Handle multiple scales: T. Serre et al. Robust object recognition with cortex-like mechanisms. PAMI 2007.
- Network-in-Network(1x1 convolutional layers): M. Lin et al. Network in network. CoRR, 2013.
- Detection baseline: R. B. Girshick et al. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014. (RCNN)
- Detection tricks: D. Erhan et al. Scalable object detection using deep neural networks. CVPR, 2014.
3.3 Motivation and High level Considerations
- two drawbacks of the simple solution - increase the depth and width of the network.
- overfiitting: big size means a large number of parameters, and the labeled examples are limited because the labeled datasets are laborious and expensive to obtain;
- computation expensive:increase use of computational resources.
- solution to solve the two issues:
- Inception module: Introduce sparsity and replace the fully connected layers by the sparse ones, even inside the convolutions.
3.4 The architecture
3.4.1 Inception module
- main idea: To consider how an optimal local sparse structure of a convolutional vision network can be approximated and covered by readily available dense components.
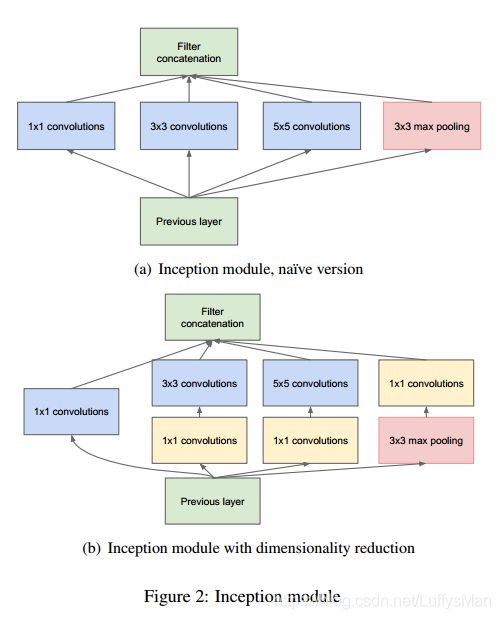
- challenge and solution:
- challenge: even a modest number of 5x5 convolutions can be prohibitively expensive on top of a convolutional layer with a large number of filters.
- solution: inception architecture – judiciousl reducing dimensoion wherever the computational requirements would increase too much. (based on the success of embeddings: even low dimensional dmbeddings might contain a lot of information about a relatively large image patch.
- emperical practice: it seemed beneficial to start using Inception modules only at higher layers while keep the lower layers in traditional convolutional fasions.
3.4.2 GoogleNet

- It contains 9 Inception modules;
- Use average pooling before the classifier, followed by a linear layer which enables it can be easily adapted to other label sets.( average pooling improved the top-1 accuracy slightly)
- To combat the vanishing gradient problem: The add auxiliary classifiers connected to intermediate layers, to utilize the features produced by the middle layers.
3.5 Training Methodology
- using the DistBelief distributed machine learning system using modest amount of model and data-parallelism. (Suprisingly they didn’t use GPUs!)
- sampling tricks:
- sampling various sized pathces of the image whose size is distributed evenly between 8% and 100% of the image area with aspect ratio constrained to the interval [ 3 4 , 4 3 ] [\frac34, \frac43] [43,34]
- photometric distortion.(光度变形, 可有效抵抗过拟合)
3.4 Experiments
- ILSVRC 2014 Classification Challenge
- testing tricks: ensemble: they trained 7 versions of the GoogleNet model(only change sampling methodologies).
- testing trcks: an agressive cropping approach: 4x3x6x2 = 144 crops per image.
- testing trcks: the softmax probabilities are averaged over multiple crops and over all the individual classifiers to obtain the final prediction.
- ILSVRC 2014 Detection Challenges Setup and Results
- Based on R-CNN, augment it with Inception model as the region classifier.
- Combining the selective search approach with multi-box(D.Erhan et al.) for higher bbox recall.
- In order to reduce the number of false positives, the super-pixel size was increased by 2x, this strategy brings about 1% improvement of the MAP metrics.(??What is super-pixel, maybe a terminology in multi-box(D.Erhan et al.))
- pre-training: using ILSVRC12 classification data for pre-training a model that is later refined ton the detection data.
3.5 Data sets
- Dataset of ILSVRC2014 Classification Challenge.
- Dataset of ILSVRC2014 Detection Challenge.
- Dataset of ILSVRC2012 Classification Challenge(for pre-training the detection model).
Question: Are the dataset sufficient?
Yes
3.6 Weakness
- The architecture seemed to be complicated.
- Using heavily with image croping in testing, which significantly increase the computation cost.
- Single model performance is inferior than VGG which is the temporal work but more simple.
4 Future works
- Towards creating sparser and more refined structures in automated ways on the basis of S.Arora et al. Provable bounds for learning some deep representations. CoRR 2013
- Applying the insights of the Inception architecture to ohter domains.
Question: Do you agree with the author about the future work?
Yes, it is important for the size of a model to deploy it to a mobile or embedded device.
5 What do other researchers say about his work?
-
Kaiming He et al. Deep Residual Learning for Image Recognition. CVPR, 2015.(ResNet) (GoogleNet was refered as 44)
- Recent evidence [41, 44] reveals that network depth is of crucial importance,
and the leading results [41, 44, 13, 16] on the challenging ImageNet dataset [36] all exploit “very deep” [41] models, with a depth of sixteen [41] to thirty [16]. - In [44, 24], a few intermediate layers are directly connected to auxiliary classifiers
for addressing vanishing/exploding gradients. - In [44], an “inception” layer is composed of a shortcut branch and a few deeper branches.
- Recent evidence [41, 44] reveals that network depth is of crucial importance,
-
Kaiming He et al. Deep Residual Learning for Image Recognition. CVPR, 2015.(ResNet) (GoogleNet was refered as 44)
- GoogLeNet (Szegedy et al., 2014), a top-performing entry of the ILSVRC-2014 classification task, was developed independently of our work, but is similar in that it is based on very deep ConvNets (22 weight layers) and small convolution filters (apart from 3 × 3, they also use 1 × 1 and 5 × 5 convolutions).
- Their network topology is, however, more complex than ours, and the spatial resolution of the feature maps is reduced more aggressively in the first layers to decrease the amount of computation.
- As will be shown in Sect. 4.5, our model is outperforming that of Szegedy et al.
(2014) in terms of the single-network classification accuracy. - At the same time, using a large set of crops, as done by Szegedy et al. (2014), can lead to improved accuracy, as it results in a finer sampling of the input image compared to the fully-convolutional net.
- While we believe that in practice the increased computation time of multiple crops does not justify the potential gains in accuracy, for reference we also evaluate our networks using 50 crops per scale (5 × 5 regular grid with 2 flips), for a total of 150 crops over 3 scales, which is comparable to 144 crops over 4 scales used by Szegedy et al. (2014).