论文学习:(TSN)Temporal segment networks: Towards good practices for deep action recognition
论文:《Temporal Segment Networks:Towards Good Practices for Deep Action Recognition》
目录
0、导论
1、TSN
Network Architecture
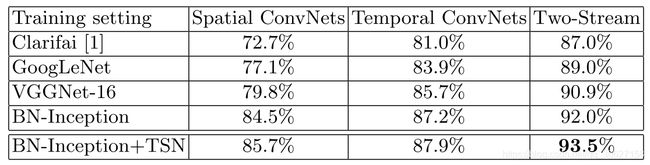
Backbone 的选择实验
Weight Initialization in Spatial & Temporal network
Segmental Consensus 的选择实验
2、Good Practices
Cross-modality Pre-training
Regularization Techniques
Enhanced Data Augmentation
3、Network’s Training & Testing
Training
Testing
0、导论
这篇文章的主要贡献就是:
1、提出了 TSN 这种新的框架
2、研究了一些让网络性能更好的 good practices
1、TSN
Network Architecture
TSN 主要是基于 Two-Stream 网络改进的。
之前的工作都是基于短视频的,而本论文作者认为需要有些动作需要用长视频来综合多个动作得出结论,比如踢足球包括跑、踢球等动作。而考虑到计算力的限制,所以他们提出了一种 sparse temporal sampling 的策略:
将一个长视频(video)分成等长的 K (论文中 K = 3)个部分(segment),对每个 segment 随机 sample 25 帧组成一个 snippet 送入 Two-Stream 网络(注意,论文中认为原来的 Two-Stream 网络里的 CNN 太 shallow 了,选择了 BN-Inception 作为双流网络的 backbone。)得到每个类别的 score。最后将 K 个 snippet 都送入网络,得到 K 个 score ,求平均,再 softmax 得到最后的分类结果。
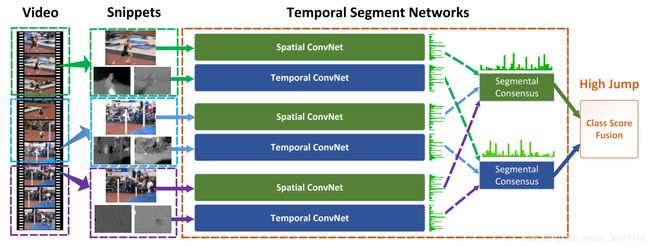
其中,F(Ti;W)是每个 snippet 送入网络后得到的 score;G 是 segmental consensus 函数(论文中就是 Average);H 是 softmax 函数
![]()
Backbone 的选择实验
Weight Initialization in Spatial & Temporal network
- spatial network 的输入就是 video frame,是很简单的 RGB 图,用在 ImageNet 上 pre-trained 好的权值,再用动作识别的数据集去 fine-tune 就好;
- temporal network 的输入的 optical flow,是与普通 RGB 图不一样的分布,所以不能用在 ImageNet 上 pre-trained 好的权值。论文中的做法是:首先,将 optical flow 图里的像素值线性映射到【0-255】的范围内;再将 spatial network 训练好后,用训练好的 spatial network 的权值作为 temporal network 的初始权值,此外,将 temporal network 的第一层卷积层的权值全部初始化为“训练好的 spatial network”的第一层卷积层的权值的平均值(因为 temporal network 的输入不是 RGB,而是 optical flow,不止 3 个 channels,不能直接用。同时,这也是为什么两个 branch network 要分开训练。)
Segmental Consensus 的选择实验

2、Good Practices
- cross-modality pre-training
- regularization techniques
- enhanced data augmentation
Cross-modality Pre-training
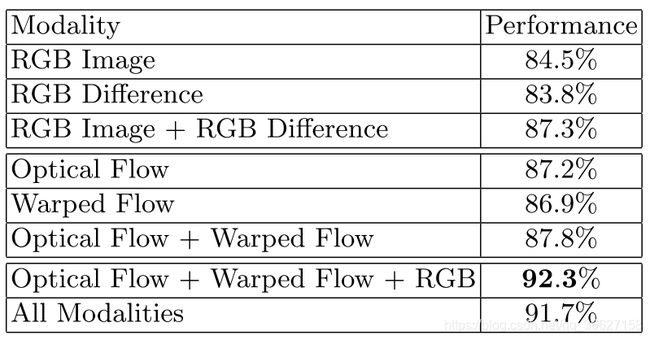
除了使用 RGB、stacked optical flow 作为输入,论文比 Two-Stream 多提出了两种模态的输入:RGB Difference 和 warped optical flow。
RGB Difference 就是相邻两帧 RGB 图做对应通道相减(但后来被用实验证明效果不如 optical flow 的好,所以只能是作为计算力有限时 optical flow 的一种 alternative)。
warped optical flow 就是用 Dense Trajectory 消除了 camera motion 的光流图。效果如下(第一行第三张是水平分量的 optical flow 图;第四张图是水平分量的 warped optical flow 图。很明显看出第三张图因为 camera motion,背景也被 highlighted 的,但第四张图的背景是被抑制的):

Regularization Techniques
- Batch Normalization。其中,temporal network 里各 Batch Normalization 层的 mean 和 variance 参数也是使用 pre-trained 好的 spatial network 里的 BN 层参数,但第一层除外,第一层是 freeze 掉其他 BN 层的参数,再训的。
- 加了一层 dropout 层。
Enhanced Data Augmentation
- 把原来的 random cropping 改为了 corner cropping(左上、左下、右上、右下、中间);
- 再加了一个 scale jittering(参考 VGG)
3、Network’s Training & Testing
Training
1、先将每个训练集视频分成 3 个 segments,每个 segment 再随机 sample 出 25 张 frames 组成一个 snippet。
2、用每个 snippet 分别产生 RGB、optical flow、warped optical flow 数据。
3、用 RGB 数据训练好 spatial network;用 optical flow、warped optical flow 数据训练好 temporal network。
Testing
1、先将每个训练集视频分成 3 个 segments,每个 segment 再随机 sample 出 25 张 frames 组成一个 snippet。
2、用每个 snippet 分别产生 RGB、optical flow、warped optical flow 数据。
3、将 RGB 数据丢入 spatial network 中得到 RGB_score;将 optical flow 数据丢入 temporal network 中得到 optical_flow_score;将 warped optical flow 数据丢入 temporal network 中得到 warped_optical_flow_score。
4、每个 snippet 的 final_score = 1 * RGB_score + 1 * optical_flow_score + 0.5 * warped_optical_flow_score
5、average 3 个 snippet 的 final_score,再 softmax ,取最大值得到最终分类类别。

