吃透MySQL(三):MyISAM和InnoDB存储引擎详细介绍
一,MySQL基本架构
MySQL基础架构可以分为两大类:Server层和存储引擎层。
- Server层: Server层涵盖了MySQL大部分核心业务功能,并且所有存储引擎的功能都在这一层实现。
- 存储引擎层:存储引擎有很多,各自有着各自的特点,可以根据场景来选择不同的存储引擎来操作数据

- 连接器:负责跟客户端建立连接,获取权限,维持和管理连接。包括用户名和密码的验证,查询权限信息,分配对应的权限,可以使用
show processlist查看现在的连接,如果太长时间没有动静,就会自动断开,通过wait_timeout控制,默认8小时。 - 分析器:词法分析:MySQL需要把输入的字符串进行时别,每个部分代表什么意思,比如,把字符串 T 识别成表名 T,把字符串 ID 识别成列 ID。语法分析:根据语法规则判断这个sql语句是否满足MySQL的语法,如果不符合就会报错“You have an error in your SQL synta”。
- 优化器:在具体执行SQL语句之前,要先经过优化器的处理。当表中有多个索引的时候,决定用哪个索引,当sql语句需要做多表关联的时候,决定表的连接顺序等等。
- 执行器:通过分析器知道了做什么,通过优化器知道了怎么做,这就遇到了一个问题,谁来做?可想而知就是执行器开始执行SQL语句。开始执行的时候,要先判断一下你对表是否有执行查询的权限,如果没有就会报出错误的提示信息。如果有权限,就打开表继续执行。执行器会根据表的引擎来调用提供的引擎接口,开始执行。
二,存储引擎
1,什么是存储引擎
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
例如,如果你在研究大量的临时数据,你也许需要使用内存MySQL存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。
这些不同的技术以及配套的相关功能在 MySQL中被称作存储引擎(也称作表类型)。 MySQL默认配置了许多不同的存储引擎,可以预先设置或者在MySQL服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
2,查看MySQL的存储引擎
我们可以用SHOW ENGINES; 来查询数据库的存储引擎:
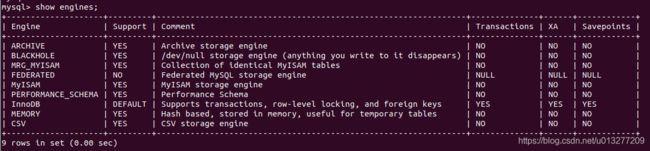
Support列的值表示某种引擎是否能使用:YES表示可以使用、NO表示不能使用、DEFAULT表示该引擎为当前默认的存储引擎。
3,MyISAM
每个MyISAM在磁盘上存储成3个文件,其中文件名和表名都相同,但是扩展名分别为:
- .frm文件存储的是表结构
- .MYD存储数据
- .MYI存储索引
MyISAM引擎的索引结构为B+Tree,其中B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。如下图所示:
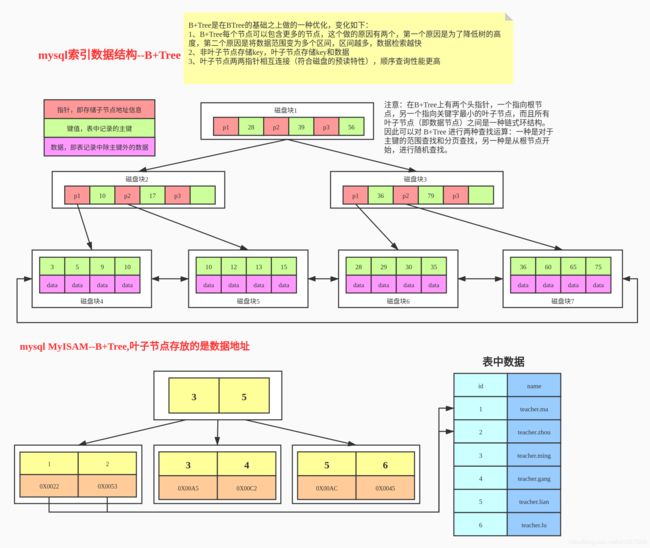
这里设表一共有两列,假设我们以id为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
辅助索引可以通过辅助键直接找到数据地址,不用再访问主键。
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
在设计之时就考虑到数据库被查询的次数要远大于更新的次数。因此,ISAM执行读取操作的速度很快,而且不占用大量的内存和存储资源。由于数据索引和存储数据分离,MyISAM引擎的索引结构是B+Tree,其中B+Tree的数据域存储的内容为实际数据的地址,也就是所他的索引和实际数据是分开的。不过索引指向实际的数据,这种索引也就是非聚合索引。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
但是它没有提供对数据库事务的支持,也不支持表级锁,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
4,InnoDB
每个InnoDB在磁盘上存储成2个文件
- .frm文件存储的是表结构
- .idb存储的是数据和索引文件
InnoDB存储引擎的索引也是使用B+Tree结构来存储的,但是InnoDB的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际数据,这种索引就是聚簇索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。
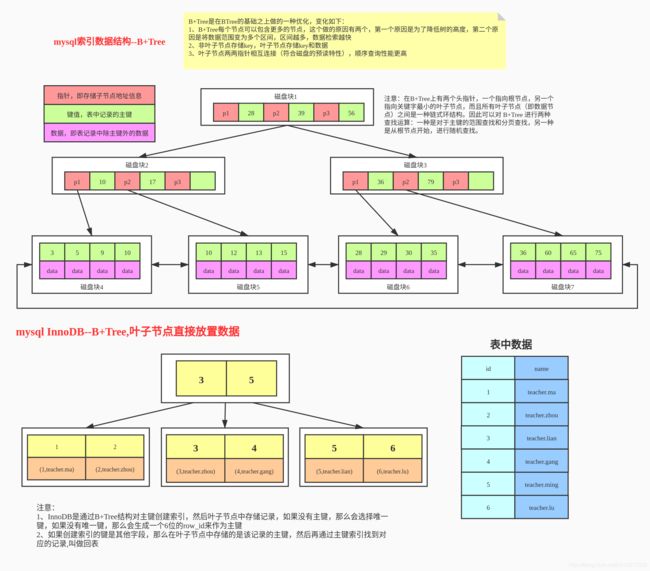
并且和MyISAM不同,InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
注意:
-
InnoDB是通过B+Tree结构对主键创建索引,然后叶子节点中存储记录,如果没有主键,那么会选择唯一键,如果没有唯一键,那么会生成一个6位的row_id来作为主键
-
如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,叫做回表
Innodb的优点
- 针对事务的支持,事务(ACID),行级锁,外键,Java中使用事务处理,首先要求数据库支持事务。如使用MySQL的事务功能,就要求MySQL的表类型为Innodb才支持事务
- 使用MVCC多版本控制器来控制事务。
5,MyISAM和InnoDB区别
-
InnoDB 支持事务,MyISAM 不支持,对于 InnoDB 每一条 SQL 语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条 SQL 语言放在 begin 和 commit 之间,组成一个事务;
-
InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM会失败;
-
InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
-
InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
-
Innodb 不支持全文索引,而 MyISAM 支持全文索引,查询效率上 MyISAM 要高;(在MySQL5.7 版本中已经支持全文索引)
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调(可能是指“非递增”的意思)的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调(可能是指“非递增”的意思)的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
6,如何选择
-
是否要支持事务,如果要请选择 innodb,如果不需要可以考虑 MyISAM
-
如果表中绝大多数都只是读查询,可以考虑 MyISAM,如果既有读写也挺频繁,请使用 InnoDB。
-
系统奔溃后,MyISAM 恢复起来更困难,能否接受;
-
MySQL5.5 版本开始 Innodb 已经成为 Mysql 的默认引擎(之前是 MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用 InnoDB,至少不会差。