一. 版本环境
以前工作的过程中,陆陆续续看过一些Hadoop1.0 MapReduce的源码,但没有形成体系。现在再次来看,顺便记录。此次学习版本的是Hadoop2.2.0 MapReduce。环境为直接在Win7下Local模式调试。MapReduce。
二. Job提交流程
从Job waitForCompletion开始
1 Job submit
1.1 JobSubmitter submitJobInternal
1.1.1 JobSubmissionFiles.getStagingDir 初始化Job系统工作目录jobStagingArea。如D:\tmp\hadoop-root\mapred\staging\rootXXXXXXXXXX\.staging。
1.1.2 获得JobID。如job_localXXXXXXXXXX_0001。
1.1.3 copyAndConfigureFiles copy Job Jar到submitJobDir = new Path(jobStagingArea, jobId.toString())。
1.1.4 writeSplits,将input划分为split,并将split数据和split元数据写入系统工作目录,最后返回split的数目。input如下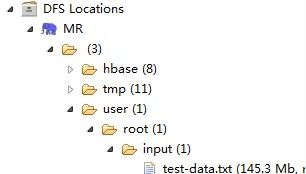
1.1.4.1 调用TextInputFormat getSplits方法获得split,集群环境BlockSize为128M,所以145M的test-data.txt被划分为两个split。相关算法自己去看,提供两个数据BlockLocation[0,134217728,201slave,203slave,202slave, 134217728,18093772,201slave,203slave,202slave],InputSplit[hdfs://192.168.1.200:9000/user/root/input/test-data.txt:0+134217728, hdfs://192.168.1.200:9000/user/root/input/test-data.txt:134217728+18093772]
1.1.4.2 JobSplitWriter.createSplitFiles将split数据和split元数据写入系统工作目录。
1.1.5 writeConf,将配置文件写到系统工作目录。此时系统工作目录如下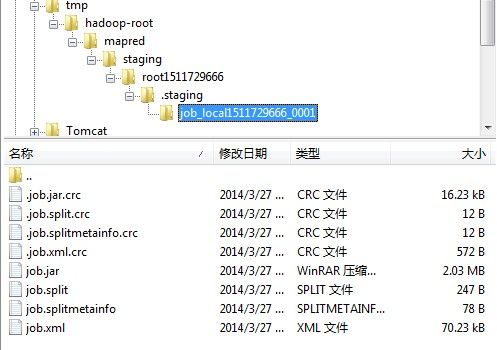
1.1.6 LocalJobRunner submitJob
1.1.6.1 new Job
1.1.6.1.1 Job初始化
1.6.1.1.1.1 systemJobDir就是上面的submitJobDir,systemJobFile = submitJobDir\job.xml
1.1.6.1.1.2 将配置文件写入本地工作目录localJobDir\localJobFile。如D:\tmp\hadoop-root\mapred\local\localRunner\root\job_localXXXXXXXXXX_0001\job_localXXXXXXXXXX_0001.xml。此时,本地工作目录如下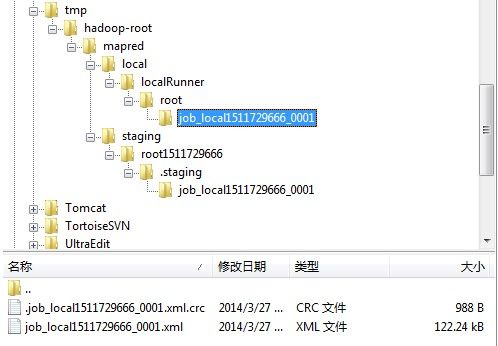
1.1.6.1.2 Job run
三. Job run流程
Job run方法很大,是整个Job执行的核心框架,自定义的Mapper和Reduce都会在这里被调起。我把这个方法单独拿出来说。
1 创建OutputCommitter
2 从系统工作目录split数据和元数据文件里获得split信息TaskSplitMetaInfo[]
3 根据TaskSplitMetaInfo[]创建List
4 ExecutorService运行每个MapTaskRunnable
4.1创建MapTask并执行run
4.2 runNewMapper
4.2.1 反射创建自定义的Mapper mapper
4.2.2 反射创建InputFormat
4.2.3 从系统工作目录文件里获得此MapTask的split
4.2.4 反射创建RecordReader
4.2.5 反射创建RecordWriter output
4.2.6 创建MapContextImpl
4.2.7 mapper.run(mapperContext),可能涉及到数据的spill。
4.2.8 output.close(mapperContext),涉及到数据的sort spill combin merge。
5 等待每个MapTaskRunnable运行完。但两个MapTaskRunnable都运行完,如下图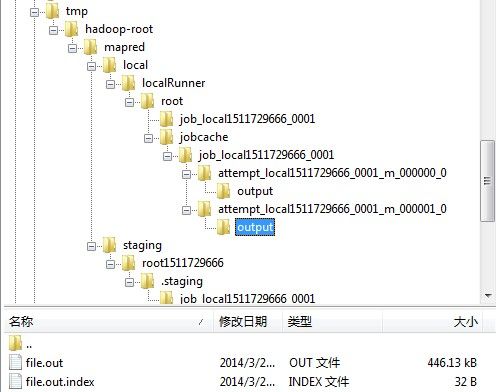
6 将Mapper的结果mv & rename到Reduce的本地工作目录,此时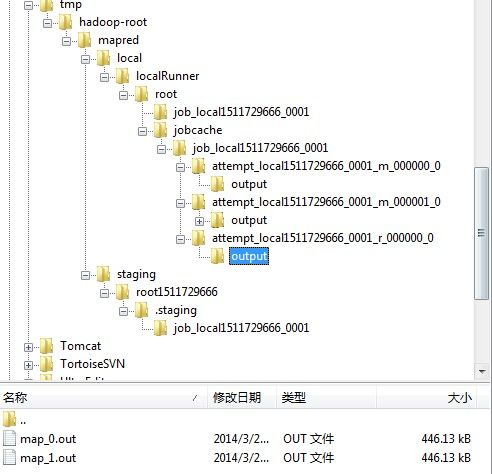
7 创建ReduceTask并执行run
7.1 merge & sort
7.2 runNewReducer
7.2.1 反射创建Reducer
7.2.2 反射创建RecordWriter,准备好临时目录流。参考类FileOutputFormat
/**
* Get the default path and filename for the output format.
* @param context the task context
* @param extension an extension to add to the filename
* @return a full path $output/_temporary/$taskid/part-[mr]-$id
* @throws IOException
*/
public Path getDefaultWorkFile(TaskAttemptContext context,
String extension) throws IOException{
FileOutputCommitter committer =
(FileOutputCommitter) getOutputCommitter(context);
return new Path(committer.getWorkPath(), getUniqueFile(context,
getOutputName(context), extension));
}
7.2.3 调用自己的Reduce,将结果输出到临时目录下
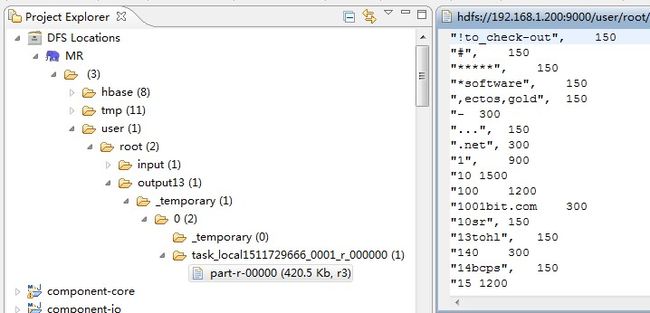
8 OutputCommitter将Reduce的结果mv到output下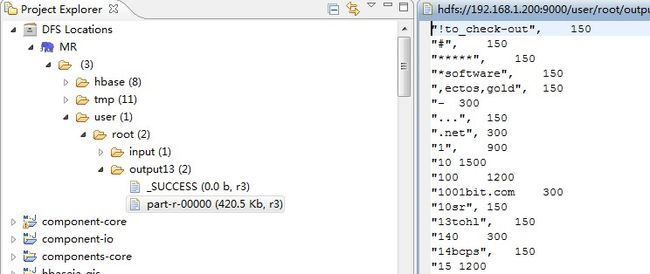
9 清理以下目录
9.1 系统工作目录systemJobFile.getParent()
9.2 本地工作目录localJobFile
四. 大流程
最后用一张图总结本文
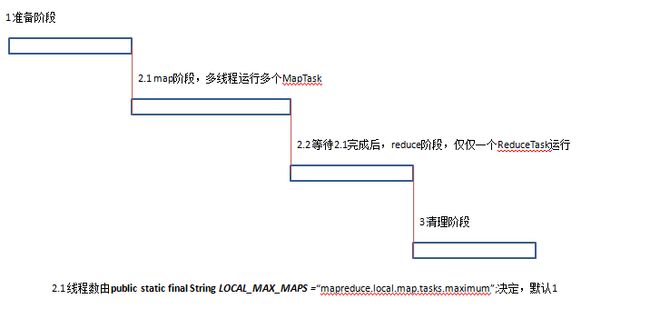
再补充一下:本地MapReduce执行时 ,有几个线程来运行MapTask
int maxMapThreads = job.getInt(LOCAL_MAX_MAPS, 1);
maxMapThreads = Math.min(maxMapThreads, this.numMapTasks);
maxMapThreads = Math.max(maxMapThreads, 1); // In case of no tasks.
ExecutorService executor = Executors.newFixedThreadPool(maxMapThreads, tf);