目标检测:对R-CNN, fast R-CNN,faster R-CNN和mask R-CNN的理解
最近准备做AI放疗相关的工作,其中包括tumor detection,所以先把这三篇文章啃了下来,过程很艰辛,每篇论文都看了好几遍,把自己的一些心得和理解记录下来。
目标检测(objection detection),就是要在图片中对目标进行定位,并且标注出物体的类别,所以相比分类任务,检测多了一步定位(location),如下面两幅图所示,红色的框框称为bounding box。(图像摘自R-CNN原文)


1. R-CNN
R-CNN在目标检测中主要解决的就是两个问题,一是对目标的定位,二是在有标记的数据不足的时候训练一个大的卷积神经网络。
利用R-CNN做目标检测主要包括三个方面:
(1)对输入图像提取大约2000个region proposals,文中提取proposal的方法是selective search,可以参考文献《Selective Search for Object Recognition》。
(2)利用一个大的卷积神经网络,对每个region都提取一个固定长度的特征矩阵
这里使用的网络是ImageNet,但是在计算每个region的特征之前,需要将每个region转换成符合CNN输入的尺寸,本文中要求的输入尺寸为227x227。
(3)对第二步提取出来的每一个类别下的特征矩阵,都会用相应类别的SVM对其进行打分,然后对于一个图像中所有打过分的region,都会利用greedy non-maximum suppression,主要是去除冗余的region,保留最好的那一个。可以参考https://blog.csdn.net/danieljianfeng/article/details/43084875
还要提的一点就是bounding box regression,作者发现加入bounding box regression可以提高定位的准确性。它的输入是![]() ,其中
,其中![]() ,分别表示region proposal
,分别表示region proposal ![]() 的中心点坐标和bounding box的宽度与高度,
的中心点坐标和bounding box的宽度与高度,![]() 就是ground-truth bounding box。目标是学习一个变换,可以将P映射到G,具体可以参考原文《Object Detection with Discriminatively Trained Part Based Models》。
就是ground-truth bounding box。目标是学习一个变换,可以将P映射到G,具体可以参考原文《Object Detection with Discriminatively Trained Part Based Models》。
缺点:
首先,R-CNN需要训练一个CNN,然后训练SVMs,最后要做一个regression,是一个multi-stage pipeline。其次,对于每个region proposal,都要传到CNN中做卷积运算得到相应的特征矩阵,这就导致了训练过程中时间和空间都消耗很大。
2. fast R-CNN
针对R-CNN训练速度慢,以及训练分为多步的缺点,fast R-CNN做出了改进,主要包括:采用了一个多任务误差,一步就能训练完整个网络,并且在R-CNN的基础上极大的极高了训练速度,同时还有实验证明利用多任务误差相比多个误差分开训练,提高了检测的正确率。
R-CNN对每个region proposal都会传入CNN来生成特征图像,考虑到这么多region proposal有很多重叠的部分,也就意味着对每个region proposal提取特征的时候,会有很多重复计算,导致了速度特别慢。fast R-CNN的输入为一幅图像以及一组region proposals,先把一幅图像传入CNN,得到feature map,然后将每个region proposal映射到feature map的位置,得到它们的feature map,再传到后面的全连接层,最后得到两个输出:一是softmax的输出,用于预测region proposal的类别(总共K个类别加一个背景),还有一个输出为四个实数(x,y,w,h),用于确定region proposal的bounding box,分别为box的中心坐标和宽度高度。
RoI pooling layer
这里需要提到的是,将每个region proposal的特征图输入全连接层之前,需要经过RoI pooling layer转换成一个固定长度的特征矩阵,之前R-CNN中用的是‘wrap’,可能会使得图像变得失真。RoI pooling layer的做法是将每个region都分成H*W块(H和W是这个层的超参数,与region无关),然后对每个块都做最大池化,最终会得到H*W的特征图。
multi-task loss
fast R-CNN的多任务误差为:,其中![]() 为对数损失,u为真实类别,p为预测类别,对于每个背景,u都定义为0。对于函数
为对数损失,u为真实类别,p为预测类别,对于每个背景,u都定义为0。对于函数![]() ,u≥1时为1,其余为0。
,u≥1时为1,其余为0。![]() 为bounding box回归误差函数,其中,
为bounding box回归误差函数,其中,![]() ,是一个鲁棒的l1范数误差,相比l2范数误差,对异常值的敏感度更低。
,是一个鲁棒的l1范数误差,相比l2范数误差,对异常值的敏感度更低。
Truncated SVD for faster detection
在最终的检测过程,需要处理的region数量非常庞大,导致了检测速度较慢,fast R-CNN采用了截断的奇异值分解方法,主要就是将全连接层u*v权重矩阵W进行奇异值分解,![]() ,其中U的大小为u*t,由W的前t个左奇异向量组成,
,其中U的大小为u*t,由W的前t个左奇异向量组成,![]() 为大小t*t的对角矩阵,由
为大小t*t的对角矩阵,由 最上面的t个奇异值组成,
最上面的t个奇异值组成, 的大小为t*v,由W的前t个右奇异向量组成。如果t比min(u,v)小很多的话,Truncated SVD就能大大减少参数的数量,从而提高检测的速度。利用奇异值分解结果就能压缩网络,与相关的全连接层就能分为两个全连接层,第一个全连接层可以使用
的大小为t*v,由W的前t个右奇异向量组成。如果t比min(u,v)小很多的话,Truncated SVD就能大大减少参数的数量,从而提高检测的速度。利用奇异值分解结果就能压缩网络,与相关的全连接层就能分为两个全连接层,第一个全连接层可以使用![]() 不加偏置作为权重矩阵,第二个全连接层使用
不加偏置作为权重矩阵,第二个全连接层使用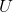 加上之前的偏置作为权重。
加上之前的偏置作为权重。
3. faster R-CNN
忽略花在region proposals上的时间的话,fast R-CNN用很深的网络几乎达到了实时的性能。所以,对于现在的一些state-of-art的检测系统来说,测试阶段生成proposal比较好时就成了一个弊端。faster R-CNN就是利用一个深度卷积神经网络来计算proposals,称为Region Proposal Networks(RPN)在这种情况下,相比于检测网络的计算时间,计算proposal的时间几乎就能忽略了。

简单概括来说,faster R-CNN就是由RPN+fast R-CNN组成的。其中RPN用来生成proposals,然后传到fast R-CNN中用于检测。上图(摘自原文)就是faster R-CNN的整个系统结构,从图上可以看到,RPN和fast R-CNN还能共享一部分卷积层。
RPN
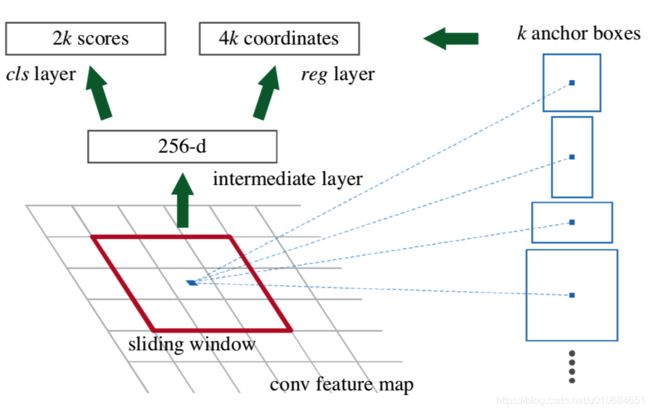
RPN的输入为一幅任意尺寸的图像,然后输出一系列矩形的目标proposals,每个proposals还带一个目标分数。
为了生成proposals,使用一个小的网络在特征图上滑动,这个特征图来自最后一层共享卷积层。这个小网络的输入为nxn的空间窗口在特征图上对应的区域,然后输出的特征会映射成一个低维的向量,然后分别传到两个全连接层中,一个用于box回归,一个用于box分类,本文中n使用的值为3。
这里不得不提到anchor机制,在每个滑动窗的位置,会同时预测多个region proposals,每个位置可能的proposals最大个数表示为k,这样回归层就会输出4k个参数,用于编码box的坐标,分类层就会输出2k的分数,用于估计每个proposal属于或者不属于目标的几率。anchor以滑动窗的中心为中心,然后根据不同的尺度和横纵比产生多个anchor。本论文默认使用三种尺度和三种横纵比,在每个滑动窗的位置产生k=9个anchors,(假设三种尺度分别为128x128,256x256,512x512,三个横纵比分别为1:1,1:2, 2:1,那么就能产生128x128,128x256,256x128,256x256,256x512,512x256,512x512,512x1024,1024x512这九个anchor)对于一个大小为WxH的特征图,就能产生WHk个anchor。
4. mask R-CNN
在faster R-CNN的基础上,mask R-CNN实现了实例分割(instance segmentation)的功能,就是输出多了一个mask prediction的分支。多任务的误差也加入了L , 最终的误差函数为
, 最终的误差函数为![]() , 其中分类误差
, 其中分类误差 和box回归误差
和box回归误差 跟faste R-CNN中的完全一样。mask分支的输出为
跟faste R-CNN中的完全一样。mask分支的输出为![]() 维,表示K个m
维,表示K个m m的二值矩阵,每个矩阵对应K个类别中的一个。对每个像素应用sigmoid激活,就定义为一个平均二值交叉熵误差。对于一个标签类别为k的RoI,只跟第k个mask有关,这就使得本网络对于每个类别生成的mask在各个类别之间不会有冲突。
m的二值矩阵,每个矩阵对应K个类别中的一个。对每个像素应用sigmoid激活,就定义为一个平均二值交叉熵误差。对于一个标签类别为k的RoI,只跟第k个mask有关,这就使得本网络对于每个类别生成的mask在各个类别之间不会有冲突。
RoIAlign
之前的RoIPool操作是将一个输入转换成固定长度的矩阵,会将一个浮点数的RoI转换成固定个的小块,然后对每个块进行最大池化,这样会使得提取的特征图和RoI不对齐,比如RoIPool计算的时候是取整[x/16],这种quantization(不知道该怎么翻译)就会产生一些误差,虽然这不会影响分类结果,但是会影响mask预测的准确性。于是,mask R-CNN中提出了RoIAlign,如图所示

虚线框代表特征图,实线表示RoI,这里是2x2块,每块中有四个采样点,每个采样点的值通过特征图中附近网格点来双线性插值得到,这里就没有因quantization操作而产生误差。