对比Excel-Python数据分析——数据选择、操作、运算(3)
1. 数据选择
普通索引:传入具体索引的名称,常用loc函数。
位置索引:传入具体索引的行数或列数,常用iloc函数。
loc函数主要通过行标签索引行数据,划重点,标签!标签!标签!
iloc 主要是通过行号获取行数据,划重点,序号!序号!序号!
1.1 列选择
- 选择某一列或某几列
当传入列名list选择,df[list]
当传入列的具体位置,传入第0,3列时,df.iloc[:,[0,2]] - 选择连续的某几列
当传入列名是连续的,df[list]
当传入连续的位置时,df.iloc[:,[0:2]]
1.2 行选择
- 选择某一行或某几行
当传入行索引list选择,df.loc[list]
当传入行的具体位置,传入第0,3行时,df.loc[[0,2]] - 选择连续的某几行
当传入行索引是连续的,df.loc[list]
当传入连续的位置时,df.iloc[0:2]
1.3 选择满足条件的行
比如我们想在表中筛选年龄大于20的女生的信息:df[(df.年龄>20)&(df.性别='女')]
1.4 行列同时选择
- 普通索引选择指定的行、列:
df.loc[['行索引名称'],[列索名称]] - 位置索引选择指定的行、列:
df.iloc[[0,2],0,2]] - 布尔索引(选择行)+普通索引选择列:
df[df.年龄>20].loc[列索名称] - 切片索引选择指定的行、列:
df.iloc[0:2,1:2] - 布尔索引(选择行)+普通索引选择列:
df[df.年龄>20].loc[列索名称] - (不推荐)切片索引(选择行)+普通索引选择列:
df.ix[0:2,'列索名称']
2. 数值操作
2.1 数值替换
数值替换就是将A 换成B,可以用在异常值替换处理、缺失值替换处理中,主要有一对一替换,多对一替换,多对多替换。
- 一对一替换:
df.replace(np.NAN,0) - 多对一替换:
df.replace([230,130,200],100) - 多对多替换:
df.replace({传入字典})
2.2 数值排序
- 按照一列数值进行降序吗,默认是True升序:
df.sort_values(by=['列名1'],ascending=False) - 按照有缺失值的列进行排序,可以通过设置na_position参数对缺失值的显示位置进行设置,默认参数值为last
缺失值放在前面:df.sort_values(by=['列名1'],na_position='first') - 按照多列数值进行排序,先对列名1进行升序,当列名1遇到重复时,再按照列名2进行降序排列。
df.sort_values(by=['列名1','列名2'],ascending=[True,False])
2.3 数值排名
数值排名和数值排序是相对应的,排名会新增一列,这一列用来存放数据的排名情况,排名是从1开始的。
-rank(ascending,method),ascending说明升降序,method指明待排序值有重复值的处理情况
- average:相同名次的取它们的平均
- first:出现相同的名次会累加,并顺延到下一个排序(常用)
- min/max:出现相同排序时取最小(大)的那个,排名不会连续

2.4 数值删除
- 删除列:
按列名 df.drop(列名列表)按位置df.drop(df.columns[[4,5]],axis=1) - 删除行:
按列名 df.drop(行名列表)按位置df.drop(df.index[[4,5]],axis=0) - 删除特定行一般指删除满足某个条件的行,但是在python中我们不满足条件的行筛选出来作为新的数据源。
删除年龄大于40的行:df[df.年龄<=40]
2.5 数值计数
数值计数就是计算某个值在一系列数值中出现的次数。
# 计算不同值出现的次数
# ID=[1,2,1,2,3]
df['ID'].value_counts()
#2 2
#1 2
#3 1
# 计算不同值出现的占比,并按ID的计数值降序
df['ID'].value_counts(normalize=True,sort=False)
#2 0.4
#1 0.4
#3 0.2
2.6 唯一值获取
唯一值获取就是把某一系列值删除重复项以后的结果。
思路1:单独取出这一列,并用删除重复项的办法。
思路2:使用unique(),对ID 获取唯一值,df['ID'].unique()
2.7 数值查找
数值查找就是查看数据表中的数据是否包含某个/些值。
- 查看某一列是否包含值:
df['ID'].isin([23,12]) - 查看整个表是否包含:
df.isin([23,12])
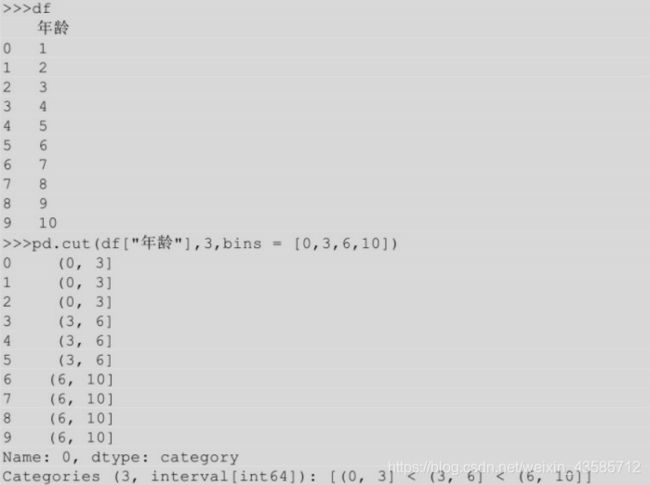
2.8 区间切分
区间切分就是将一系列的数值分成若干份,比如现在你有10个人,你要根据这10个人的年龄将他们分成3组,这个过程就是区间切分。python中实现用下面两种方法,当数据分布较均匀,两种方法得到的区间基本一致,当数据分布不均匀时,即方差比较大时,两者得到的区间的偏差就会比较大。
- cut(bins),bins用来指明切分区间。
- qcut() 不需要事先指明切分区间,只需指明切分个数,即你要把数据切成几份,原则就是尽可能的使每个组里面的数据尽可能相等。

2.9 插入新的行或列
- 插入行
python 没有专门实现插入行的办法,可以把待插入的行当作一个新的表,然后将两个表在纵轴方向上进行拼接,pd.concat()。 - 插入列
在特定的位置插入行/列,主要是考虑在哪插入,插入什么,用的insert(位置,插入后新列的列名,插入的数据)
往表中的第2列插入新的一列,并命名为商品:df.insert(2,'商品',['A','B','C'])
或者df['商品']=['A','B','C']
5.5 添加列
添加一列: df[‘列名1’]=0/或者其他默认值
添加多列分为两种情况:
- 一次性添加多列并有数据
- 依次添加列并有数据
# 一次性添加多列并有数据
"依次添加列并有数据"
# 实现将me
result=medata[['ID_1','项目']]
result=result.drop_duplicates( keep='first')
cols1=['ID_1','项目']+["{}".format(i) for i in range(7, 9]
# 添加多个列名
result=result.reindex(columns=cols1, fill_value=np.nan)
# 添加数据
# 将月份一列转换多列
for i in range(1,dt.today().month+1):
medata1=medata.loc[medata['月'] == i]
medata1=medata1.rename(columns={
'成本':("{}月").format(i)})
medata1=medata1.drop('月',axis=1)
result=pd.merge(result,medata1,how='left')
类似结果:
2.10 行列互换
df.T即可。
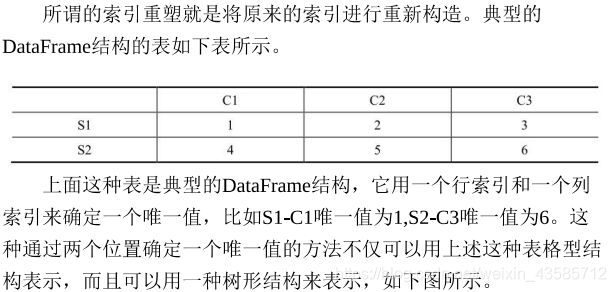
2.11 索引重塑(常用+难点)

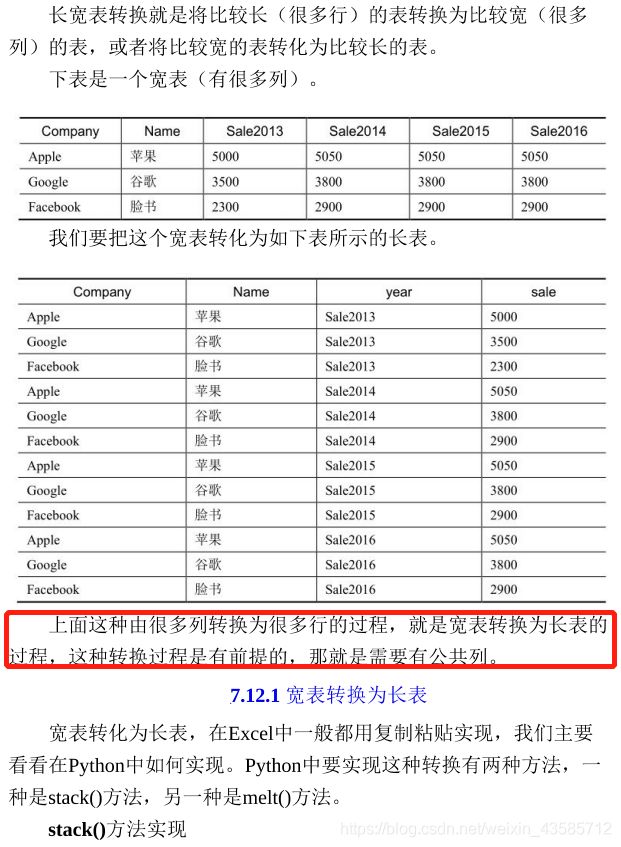
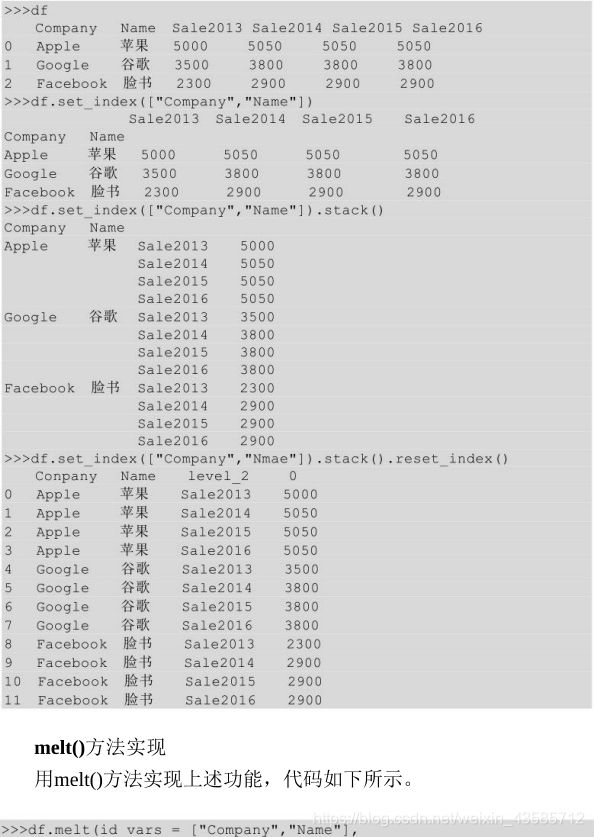
2.12 长宽表转换
- 宽表换长表:1.stack() 2.melt()
- 长表换宽表:透视表


2.13 apply()与applymap()函数
python中的map()函数是对一个序列中的所有元素执行相同的函数操作。
在DtaFrame中与map()函数类似的有两个:apply(),applymap(),但是两者都需要与匿名函数lambda()结合使用。
- apply()函数主要用于DtaFrame中的某一列/行中的元素执行相同的函数操作。
- applymap()函数用于DtaFrame中的每一个元素执行相同的函数操作。
# 表中的ID列加1
df['ID'].apply(lambda x:x+1)
# 表中的每一个元素加1
df.applymap(lambda x:x+1)
3. 数值运算
3.1 算数运算
- 两列四则运算:
df.[]+/-/*/df.[] - 一列与一个值a:
df.[]+/-/*/a
3.2 汇总运算
3.21 count非空值计数
非空值计算就是计算某一个区域非空(单元格)数值的个数。
# 求每列非空值得个数
df.count()
# 求每行非空值得个数
df.count(axis=1)
# 或者把某一行/列得索引写出来,看行/列得非空值个数
df.['ID'].count()
3.22 sum求和
# 计算整个表每一列
df.sum()
# 计算整个表每一行
df.sum(axis=1)
# 或者把某一行/列得索引写出来,看行/列得和
df.['ID'].sum()
3.23 mean均值
# 计算整个表每一列
df.mean()
# 计算整个表每一行
df.mean(axis=1)
# 或者把某一行/列得索引写出来,看行/列的均值
df.['ID'].mean()
3.24 max/min/median(中位数)/mode(众数)/var(方差)/std(标准差)
使用方式与上面三种类似。
3.25 quantile求分位数
# 计算整个表的四分之一分位数
df.quantile(0.25)
# 计算整个表每一行的二分之一分位数
df.quantile(0.5,axis=1)
# 或者把某一行/列得索引写出来,计算某一列/行的分位数
df.['ID'].quantile(0.25)
3.3 相关性运算
相关性用来衡量两个事物之间的相关程度。
求列名1与列名2的相关性系数(一个值)
df.['列名1'].corr(df.['列名2'])
# 求整个表各字段两两之间的相关性,返回的大小与原表大小一致。
df.corr()