爬虫(12,13)selenium练习 12306案例
文章目录
- 0. 前言
- 1. 登录的实现
- 2. 车次及余票查询
-
- 2.1 车站信息读取
- 2.2 车站信息添加方法
- 2.3 车站信息导入输入框
- 2.4 出发日期与查询按钮
- 2.5 执行结果错误分析
- 2.6 成功登录并查询的最后代码
- 3. 解析车次列表
- 4.预定车次
-
- 4.1 座位类别判断
- 4.2 代码优化
- 4.3 解决报错问题
-
- 4.3.1 第一次报错纠正
- 4.3.2 第二次报错纠正
- 4.4 最后正确代码
- 5. 确认乘客和车次信息
-
- 5.1 等待
- 5.2 曾加乘客姓名参数
- 5.3 勾选购票乘客姓名
- 5.4 确认需要购买席位信息
- 6. 提交订单
- 7. 最后正确的代码
- 8. 改进后的代码
0. 前言
这个案例旨在练习selenium方法,以及面向对象编程的代码敲打。本案例的功能是(按顺序罗列):
- 打开12306登录界面
- 窗口最大化 (登录需要自己扫码,后续可以尝试获得cookie)
- 跳转个人中心界面
- 填写出发地
- 填写目的地
- 填写出发日期
- 跳转到车次及余票查询页面
- 点击通告窗口确定按钮
- 点击查询按钮
- 查询我们想要的车次一等座二等座是否有票
- 点击预定按钮
- 跳转购票确认页面
- 勾选购票人
- 选择座位类别
- 点击提交按钮
- 跳转到核对信息窗口
- 点击确认购买按钮
- 系统生成订单
- 自行操作支付购买
- 购票成功
这里许多点击动作selenium的操作不响应,有的需要设置显示等待。老师的最后提交按钮是用循环不断点击,我是用execut_script()方法代替,亲测该方法屡试不爽。就是没有不成功的。
后面可以丰富该案例的功能,使它更实用。比如可以在程序执行后跳出交互界面,输入想要查询的车次信息,输入出发地,目的地,出发日期就可以打印出对应的车次信息,自己可以查看打印出的车次信息然后决定购买哪一趟,交互界面点击输入车次信息,输入回车后,程序继续运行后面的代码,然后交互让你填写购票人姓名,然后就是自动帮你生成订单。你只需要手机扫码支付就可以了。有时间可以整整。
1. 登录的实现
我们这一步先研究登录网站。我们用面向对象编程,这一步我们实现的目标是,定义项目框架,执行程序后,登录网站,并且提示已经登录成功。注意看代码中的注释:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
def __init__(self, from_station, to_station, train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver,300).until( # 这一行传入的第一个是驱动,第二个是等待时间
EC.url_contains(self.personal_url) # 这一行传入的是包含跟人界面的url条件,条件满足就不再继续等待
)
print('已经登录成功')
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 登录
self.login()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30') # 实例化类
spider.run()
if __name__ == '__main__': # 主入口,调用主函数开始执行
main()
程序执行后,先跳出第一个页面,登录界面。用app扫码登录后,跳出个人界面。然后程序执行结束,打印出登录成功提醒。
执行结果:

注意:
- 不要把驱动写入类里面,因为类调用后就会销毁,而驱动也会随着类销毁而失去,导致浏览器打开后又迅速消失。我们要放在全局变量里面。
- 登录时,我们设置了显示等待,条件是个人中心的界面url。
2. 车次及余票查询
第二步就到了一个重点了,是车次和余票的查询。我们登录后,就到了一个“单程”的界面了,这个界面对应得地址是:
https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc
下面我要做一个逻辑了,是车次与余票查询的逻辑。我们定义一个方法,叫“leftTicket”,在登录的方法下面。并且在run方法里面调用一下这个方法:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
def __init__(self, from_station, to_station, train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver,300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
pass
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30')
spider.run()
if __name__ == '__main__':
main()
里面的逻辑怎么写呢?我们需要打开车次以及余票的页面,所以要把这个页面的url放在上面。
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
余票查询后,我们需要跳转到买票的界面。跳转之前,我们需要填写“出发地”,“目的地”,“出发日期”等信息。上次课我们是手动填写的,这一次我们用代码来解决。
我们右键检查一下网页源码:

我们发现有两个input标签,第一个input标签的type是hidden隐藏的意思。说明出发地和目的地的获取并不是通过文本,而是通过value值,就是城市的代号得到的。如果你通过Send_keys(‘长沙’)是没有用的。所以,你需要获取全国车站对应的代号,通过这个代号来传递车站信息。我已经准备好了一个csv文件,专门存储车站信息的,如图:
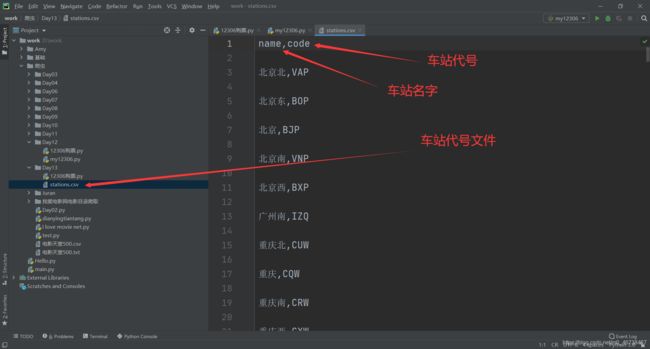
2.1 车站信息读取
接下来我们要做的事是把这些车站的信息读取出来,然后用于后面的车次查询操作。我们回顾一下读取文件的步骤:
import csv
with open('stations.csv','r',encoding='utf-8') as f:
reader = csv.DictReader(f)
info_dict = {}
info_lst = []
for line in reader:
name = line['name']
code = line['code']
print('name:{},code:{}'.format(name,code))
打印结果
name:太原,code:TYV
name:武汉,code:WHN
name:王家营西,code:KNM
name:乌鲁木齐,code:WAR
name:西安北,code:EAY
name:西安,code:XAY
name:西安南,code:CAY
name:西宁,code:XNO
name:银川,code:YIJ
name:郑州,code:ZZF
name:阿尔山,code:ART
... ...
太占篇幅,后面的省略了。
2.2 车站信息添加方法
我们可以定义一个方法,读取文件,把读取到的信息新键一个字典,把车站名作为键,车站代号作为值,这样我们调用的时候就方便多了。我们把这个逻辑写入代码,注意看注释:
import csv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
def __init__(self, from_station, to_station, train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver,300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
pass
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30')
spider.run()
if __name__ == '__main__':
main()
这段代码需要说明的是:
- 车站信息读取方法我们在初始化方法里面直接调用了,这样当这个类初始化时,车站信息就被读取好了,方便使用。
- 车站信息读取方法的最后一步是把读取的内容添加到一个空字典里,这个空字典我们放在了初始化方法里面,这样的其他的方法也可以调用。而同样的,车站信息读取方法要用也需要
"self.station_codes_dict[name] = code"这样调用。
2.3 车站信息导入输入框
我们怎样把这个车站信息填入网站上的出发站和到达站输入框呢,因为这里的input标签是隐藏的类型。所以我们并不能直接用selenium的send_keys方法去操作。这里需要selenium提供的一个叫着"execute_script()"方法,这个方法的主要作用是它可以调用一些JavaScript()方法的操作,例如拖动网页窗口的滚动条这样的操作,在selenium里面并没有提供这样的方法,但是提供了execute_script(),可以调用JavaScript()里的相关操作方法来实现。
execute_script()方法可以调用JavaScript()方法
下面看代码,注意看注释:
import csv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
def __init__(self, from_station, to_station, train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
info_dict = {}
info_lst = []
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver,300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
driver.get(self.left_ticket_url)
# 出发地
from_station_input = driver.find_element_by_id('fromStation') # 找到出发地输入框元素
from_station_code = self.station_codes_dict[self.from_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"'%from_station_code,from_station_input) # 把实例出发地传入输入框
# 上面这行代码的解释:"arguments[0].value"这是Java里的占位符,"%s"这是python里的占位符
# %from_station_code,from_station_input这句意思是用后面的from_station_input被前面的from_station_code代替
# 目的地
to_station_input = driver.find_element_by_id('toStation') # 找到目的地输入框元素
to_station_code = self.station_codes_dict[self.to_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % to_station_code, to_station_input) # 把实例目的地传入输入框
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30')
spider.run()
if __name__ == '__main__':
main()
注意,这里执行后,虽然输入框里面并没有显示我们输入的城市名西安,但是实际上我们的代号“XAY”已经成功传入,可以右键查看。在查看前千万不要用鼠标点击输入框,因为点击有清除输入框内容的功能,点击后,你再右键查看,会发现value值是空的。但尽管如此,我们的车站代号还是成功传入了的。
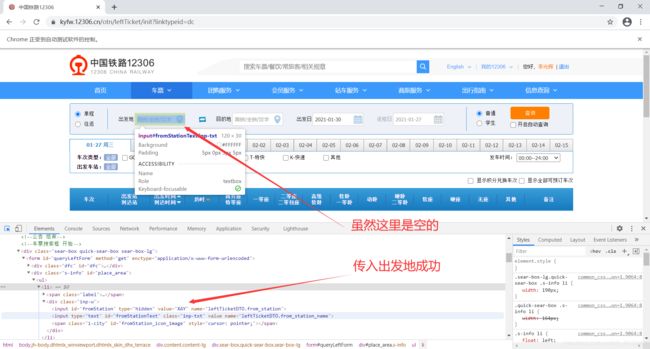
2.4 出发日期与查询按钮
下面我们定义日期和点击查询按钮的代码:
import csv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
def __init__(self, from_station, to_station, train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
info_dict = {}
info_lst = []
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver,300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
driver.get(self.left_ticket_url)
# 出发地
from_station_input = driver.find_element_by_id('fromStation') # 找到出发地输入框元素
from_station_code = self.station_codes_dict[self.from_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"'%from_station_code,from_station_input) # 把实例出发地传入输入框
# 上面这行代码的解释:"arguments[0].value"这是Java里的占位符,"%s"这是python里的占位符
# %from_station_code,from_station_input这句意思是用后面的from_station_input被前面的from_station_code代替
# 目的地
to_station_input = driver.find_element_by_id('toStation') # 找到目的地输入框元素
to_station_code = self.station_codes_dict[self.to_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % to_station_code, to_station_input) # 把实例目的地传入输入框
# 出发日期
train_date_input = driver.find_element_by_id('train_date')
driver.execute_script('arguments[0].value="%s"' % self.train_data, train_date_input)
# 查询按钮
search_btn = driver.find_element_by_id('query_ticket')
search_btn.click() # 点击查询按钮
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30')
spider.run()
if __name__ == '__main__':
main()
2.5 执行结果错误分析
现在可以点击执行尝试一下了。
执行后还是出现了问题的。总结如下:
- 第一次出现的问题是TrainSpider这个类无station_codes_dict这个参数,原因是我把
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
这两句的位置顺序放反了,第一句先执行,却找不到字典,因为字典在后面还未执行的代码里。
- 第二个坑是,点击的时候显示按钮位置被覆盖的错误,错误语句如下
selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted: Element ... is not clickable at point (973, 153). Other element would receive the click:
(Session info: chrome=88.0.4324.104)
原因是点击位置被覆盖
画面惨不忍睹,来个截屏
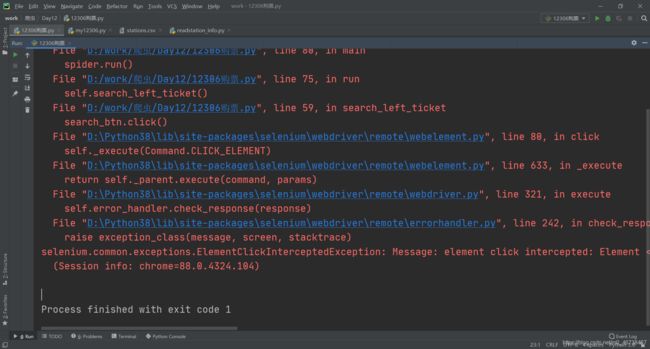
百度搜索,解决办法有三:
# 解决方法一:js注入
element1 = driver.find_element_by_css_selector('.ush button')
driver.execute_script("arguments[0].click();", element1)
# 解决方法二:ActionChains,需要先导入
webdriver.ActionChains(driver).move_to_element(element ).click(element ).perform()
# 解决方法三:使用回车代替点击
driver.find_element(By.CSS_SELECTOR,"#submit").send_keys(Keys.ENTER)
亲测第一中方法有效,后两种方法不行,可以登录,但没有查询动作,也没有报错。目前不知道原因,有空再仔细研究。如果你知道原因,欢迎留言。
2.6 成功登录并查询的最后代码
下面是登录成功的完整代码,并成功查询的页面。注意看注释:
# @Time : 2021/1/25 22:31
# @Author : Guanghui Li
# @File : my12306.py
# @Software: PyCharm
import csv
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
def __init__(self, from_station, to_station, train_data):
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
'''
'TrainSpider' object has no attribute 'station_codes_dict'
'''
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver,300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
driver.get(self.left_ticket_url)
# 出发地
from_station_input = driver.find_element_by_id('fromStation') # 找到出发地输入框元素
from_station_code = self.station_codes_dict[self.from_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"'%from_station_code,from_station_input) # 把实例出发地传入输入框
# 上面这行代码的解释:"arguments[0].value"这是Java里的占位符,"%s"这是python里的占位符
# %from_station_code,from_station_input这句意思是用后面的from_station_input被前面的from_station_code代替
# 目的地
to_station_input = driver.find_element_by_id('toStation') # 找到目的地输入框元素
to_station_code = self.station_codes_dict[self.to_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % to_station_code, to_station_input) # 把实例目的地传入输入框
# 出发日期
train_date_input = driver.find_element_by_id('train_date')
driver.execute_script('arguments[0].value="%s"' % self.train_data, train_date_input)
# 查询按钮
search_btn = driver.find_element_by_id('query_ticket')
# search_btn.click() # 点击查询按钮
ag_btn = driver.find_element_by_id('qd_closeDefaultWarningWindowDialog_id') # 通告弹出框的确定按钮
ag_btn.click() # 点击通告确定按钮
driver.execute_script('arguments[0].click();',search_btn) # 点击查询按钮
'''
点击位置被覆盖从而点击错误的问题
# 解决方法一:js注入
element1 = driver.find_element_by_css_selector('.ush button')
driver.execute_script("arguments[0].click();", element1)
# 解决方法二:ActionChains,需要先导入
webdriver.ActionChains(driver).move_to_element(element ).click(element ).perform()
# 解决方法三:使用回车代替点击
driver.find_element(By.CSS_SELECTOR,"#submit").send_keys(Keys.ENTER)
'''
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30')
spider.run()
if __name__ == '__main__':
main()
执行结果:
已经登录成功
登录后的界面。
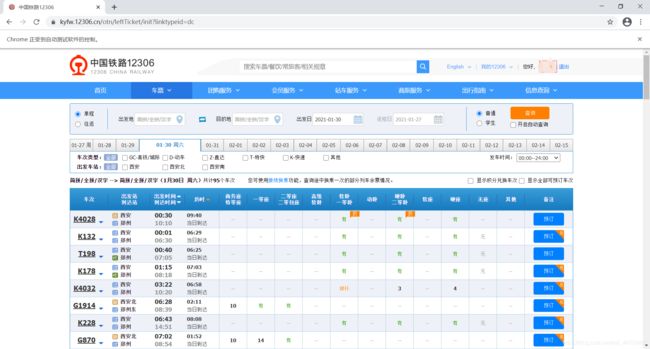
3. 解析车次列表
下面我们要提取车次列表信息。我们右键检查网页源码,发现车次信息都在一个tr标签里,这个tr标签里面有id,而body标签里tr标签成对出现,每对的第二个tr标签里面并没有车次信息,它的特征是有 datatran ,需要过滤掉:

需要注意的是,所有的车次信息是在点击动作之后加载的,需要一些等待时间。所以,我们要添加一个显示等待。
WebDriverWait(driver,300).until(
EC.presence_of_all_elements_located((By.XPATH,'//tbody[@id="queryLeftTable"]/tr'))
)
下面我们需要提取所有的tr标签并过滤掉没有用的tr标签:
# 获取tr标签
train_trs = driver.find_element_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
# 后面的[not(@datatran)]语句是过滤掉含有datatran的tr标签
我们打印一下看看结果:
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs:
print(train_tr.text)
结果:
已经登录成功
K4028
西安
郑州
00:30
10:10
09:40
当日到达
-- -- -- --
有
折
--
有
折
-- 有 -- -- 预订
K132
西安
郑州
00:01
06:30
06:29
当日到达
-- -- -- -- 18 -- 有 -- 有 无 -- 预订
我们看到提取结果并不在同一行,这样的结果不利于调用。我们可以将它弄到同一行,并以列表的形式返回。方便我们后面用索引提取相关信息。
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs:
train_tr_lst = train_tr.text.split('\n')
print(train_tr_lst)
打印结果
已经登录成功
['K4028', '西安', '郑州', '00:30', '10:10', '09:40', '当日到达', '-- -- -- --', '有', '折', '--', '有', '折', '-- 有 -- -- 预订']
['K132', '西安', '郑州', '00:01', '06:30', '06:29', '当日到达', '-- -- -- -- 18 -- 有 -- 有 无 -- 预订']
['T198', '西安', '郑州', '00:40', '07:05', '06:25', '当日到达', '-- -- -- -- 有 -- 有 -- 有 无 -- 预订']
['K178', '西安', '郑州', '01:15', '08:18', '07:03', '当日到达', '-- -- -- -- 有 -- 有 -- 有 无 -- 预订']
这就是我们要的结果了,后面我们直接通过索引提取我们需要的元素。
4.预定车次
下面我们先把车次列表里面的车次提取出来:
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs:
train_tr_lst = train_tr.text.split('\n')
train_nums = train_tr_lst[0] # 车次
并且把乘客想要的车次信息作为一个参数定义到初始化方法里面去:
def __init__(self, from_station, to_station, train_data, train_wanted):
"""
:param from_station: 出发站
:param to_station: 目的站
:param train_data: 出发日期
:param train_wanted: 想要的车次
"""
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.train_wanted = train_wanted
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
将乘客想要的车次加入实例化类的传参中:
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30',{'G430':['O','M']})
spider.run()
# {'G430':['O','M'] 中括号里的信息代表的是席位种类
下面我们判断是否有我们要的车次,如果有判断有没有二等座,如果有,将二等座的信息提取出来:
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs: # 遍历所有的车次
train_tr_lst = train_tr.text.split('\n')
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
如果条件都成立,我们可以点击预定按钮来预定了,那么我们需要查找预定按钮并作点击动作:
# 获取tr标签
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs: # 遍历所有的车次
train_tr_lst = train_tr.text.split('\n')
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
4.1 座位类别判断
下面我们继续作判断,如果没有二等座,是不是有一等座,如果有,点击预定:
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs: # 遍历所有的车次
train_tr_lst = train_tr.text.split('\n')
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
order_btn.click()
elif seat_type == 'M': # 如果有一等座
count = train_num[8] # 提取出一等座的信息,一等座的索引值是8
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
order_btn.click()
4.2 代码优化
也可以把点击的代码优化一下:
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
elif seat_type == 'M': # 如果有一等座
count = train_num[8] # 提取出一等座的信息,一等座的索引值是8
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
if is_searched: # is_searched的值为真,条件被激发
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
order_btn.click() # 点击
break # 退出
4.3 解决报错问题
下面我们点击执行一下,结果报错的。
已经登录成功
Traceback (most recent call last):
File "D:/work/爬虫/Day12/my12306_0.py", line 129, in
main()
File "D:/work/爬虫/Day12/my12306_0.py", line 125, in main
spider.run()
File "D:/work/爬虫/Day12/my12306_0.py", line 120, in run
self.search_left_ticket()
File "D:/work/爬虫/Day12/my12306_0.py", line 96, in search_left_ticket
count = train_num[9] # 提取出二等座的信息,二等座的索引值是10
IndexError: string index out of range
4.3.1 第一次报错纠正
仔细检查了一下,问题出现第88行代码:
train_tr_lst = train_tr.text.split('\n')
这里我们直接以换行符为标志进行分割了,而分割出来的字符串长这样子:
['K178', '西安', '郑州', '01:15', '08:18', '07:03', '当日到达', '-- -- -- -- 有 -- 有 -- 有 无 -- 预订']
看出来没有,一等座和二等座的有无信息,甚至预定按钮信息,全部在列表的一个元素里,这样我们怎么能选择呢?所以修改成下面的:
train_tr_lst = train_tr.text.replace('\n',' ').split(' ')
以空格为标志来分割,这次我们再执行一下看看。
又报错同样的信息
已经登录成功
Traceback (most recent call last):
File "D:/work/爬虫/Day12/my12306_0.py", line 129, in
main()
File "D:/work/爬虫/Day12/my12306_0.py", line 125, in main
spider.run()
File "D:/work/爬虫/Day12/my12306_0.py", line 120, in run
self.search_left_ticket()
File "D:/work/爬虫/Day12/my12306_0.py", line 96, in search_left_ticket
count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
IndexError: string index out of range
我们再打印一下车次信息:
['G1282', '西安北', '郑州东', '13:08', '15:10', '02:02', '当日到达', '4', '候补', '有', '--', '--', '--', '--', '--', '--', '--', '--', '预订']
['G430', '西安北', '郑州东', '13:19', '15:37', '02:18', '当日到达', '9', '有', '有', '--', '--', '--', '--', '--', '--', '--', '--', '预订']
['K608', '西安', '郑州', '13:23', '20:50', '07:27', '当日到达', '--', '--', '--', '--', '有', '--', '有', '--', '有', '无', '--', '预订']
4.3.2 第二次报错纠正
这次分割的没有错了,但为什么会报错呢?再检查发现问题在96行:
# count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
,车次信息的列表名搞错了,应该改为:
count = train_tr_lst[9]
4.4 最后正确代码
这次应该没有问题了。要把一等座的对应代码也改回来。全部改完后的代码时这样子的:
import csv
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
def __init__(self, from_station, to_station, train_data, train_wanted):
"""
:param from_station: 出发站
:param to_station: 目的站
:param train_data: 出发日期
:param train_wanted: 想要的车次
"""
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.train_wanted = train_wanted
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
'''
'TrainSpider' object has no attribute 'station_codes_dict'
'''
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver, 300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
driver.get(self.left_ticket_url)
# 出发地
from_station_input = driver.find_element_by_id('fromStation') # 找到出发地输入框元素
from_station_code = self.station_codes_dict[self.from_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % from_station_code, from_station_input) # 把实例出发地传入输入框
# 上面这行代码的解释:"arguments[0].value"这是Java里的占位符,"%s"这是python里的占位符
# %from_station_code,from_station_input这句意思是用后面的from_station_input被前面的from_station_code代替
# 目的地
to_station_input = driver.find_element_by_id('toStation') # 找到目的地输入框元素
to_station_code = self.station_codes_dict[self.to_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % to_station_code, to_station_input) # 把实例目的地传入输入框
# 出发日期
train_date_input = driver.find_element_by_id('train_date')
driver.execute_script('arguments[0].value="%s"' % self.train_data, train_date_input)
# 查询按钮
search_btn = driver.find_element_by_id('query_ticket')
# search_btn.click() # 点击查询按钮
ag_btn = driver.find_element_by_id('qd_closeDefaultWarningWindowDialog_id')
ag_btn.click() # 点击通告按钮
driver.execute_script('arguments[0].click();', search_btn)
# 解析车次信息
WebDriverWait(driver, 300).until(
EC.presence_of_all_elements_located((By.XPATH, '//tbody[@id="queryLeftTable"]/tr'))
)
# 获取tr标签
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
for train_tr in train_trs: # 遍历所有的车次
# train_tr_lst = train_tr.text.split('\n')
train_tr_lst = train_tr.text.replace('\n',' ').split(' ')
# print(train_tr_lst)
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
# count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
count = train_tr_lst[9]
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
elif seat_type == 'M': # 如果有一等座
count = train_tr_lst[8] # 提取出一等座的信息,一等座的索引值是8
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
if is_searched:
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
order_btn.click() # 点击
break # 退出
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
def main(): # 用来调用各个方法
spider = TrainSpider('西安', '郑州', '2021-01-30',{'G430':['O','M']})
spider.run()
if __name__ == '__main__':
main()
这次成功跳转了:

5. 确认乘客和车次信息
当我们进入确认购买页面后,我们需要作几个操作
- 选择乘车人
- 选择席别
- 提交订单
这些操作之前,要等待页面加载完成才行,所以理所当然的有这样一行代码:
def confirm_passengers(self):
# 确认页面
WebDriverWait(driver, 300).until(
EC.url_contains(self.confirm_url)
)
我们定义了一个新的方法,用来确认购买的。confirm_url是确认购买的页面网址。
5.1 等待
下面我们要添加乘客性名,需要先找到乘客性名所在的标签,然后显示等待,等待目标标签都出现,然后查找乘客性名标签,并遍历。
def confirm_passengers(self):
# 确认页面
WebDriverWait(driver, 300).until(
EC.url_contains(self.confirm_url)
)
WebDriverWait(driver,300).until(
EC.presence_of_all_elements_located(By.XPATH,'//*[@id="normal_passenger_id"]/li[1]/label')
)
passenger_lables = driver.find_elements_by_xpath('//*[@id="normal_passenger_id"]/li[1]/label')
for passenger_lable in passenger_lables: # 遍历姓名标签
name = passenger_lable.text # 提取姓名字符串
5.2 曾加乘客姓名参数
下面我们要把要购买车票的乘客姓名作为参数传入初始化方法中,以便调用:
def __init__(self, from_station, to_station, train_data, train_wanted,passengers):
"""
:param from_station: 出发站
:param to_station: 目的站
:param train_data: 出发日期
:param train_wanted: 想要的车次
:param passengers: 要购票的乘客姓名,是列表形式 ['张三’,'李四']
"""
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.train_wanted = train_wanted
self.passengers = passengers
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
5.3 勾选购票乘客姓名
后面的代码这样写,遍历姓名标签,如果姓名在购票的乘客的列表中,那么就对这个乘客的姓名标签作点击勾选动作:
passenger_lables = driver.find_elements_by_xpath('//*[@id="normal_passenger_id"]/li[1]/label')
for passenger_lable in passenger_lables: # 遍历姓名标签
name = passenger_lable.text # 提取姓名字符串
if name in self.passengers: # 如果标签里的姓名在购票姓名列表里
passenger_lable.click() # 点击勾选乘客姓名动作
5.4 确认需要购买席位信息
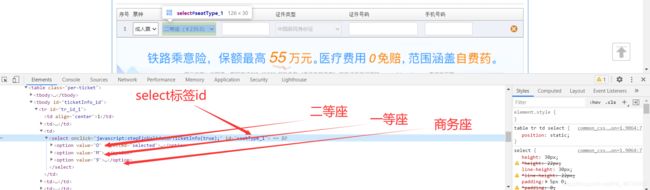
我们右键检查源代码,可以看到二等座,一等座,商务座的标签。和select标签的id,这是后面要用的。
我们选择席位类别需要用到trains = {‘G403’:[‘O’,‘M’]}里面的值。车次,我们可以在112~116行代码里确定下来(这时我们可以添加代码“车次”来确定车次):
if is_searched:
seat_select = train_num # 代码“车次”: 点击时确定了的车次,以备后面选择席位类别使用
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
order_btn.click() # 点击
break # 退出
但是在这里调用不了,我们可以把它添加到初始化方法里:
self.passengers = passengers
self.seat_select = None
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
下面我们就可以通过车次来确定座位类别:
# 确认需要购买的席位信息
seat_select = Select(driver.find_element_by_id('seatType_1')) # 将找到的select标签座位参数传递到Select类里面去
seat_types = self.train_wanted[self.seat_select] # train_wanted这个时输入的车次字典,self.seat_select这个是车次的键,取出车次字典里面的值:座位类别
# 座位类别一共两个,我们遍历一下
for seat_type in seat_types:
# 将座位类别传递到seat_select.select_by_value()中去
seat_select.select_by_value(seat_type)
可是如果我们要选的座位类别已经卖完了不就报错了吗?所以这里用try语句解决这个问题,导入一下异常模块NoSuchElementException,看最后一行:
rom selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
from selenium.webdriver.support.ui import Select # 在选择席位类别时用到
from selenium.common.exceptions import NoSuchElementException # 当所选的座位类别卖完时用到
如果出现异常,让它跳过继续循环。如果找到了座位类别,就break,跳出循环:
# 确认需要购买的席位信息
seat_select = Select(driver.find_element_by_id('seatType_1')) # 将找到的select标签座位参数传递到Select类里面去
seat_types = self.train_wanted[self.seat_select] # train_wanted这个时输入的车次字典,self.seat_select这个是车次的键,取出车次字典里面的值:座位类别
# 座位类别一共两个,我们遍历一下
for seat_type in seat_types:
try:
# 将座位类别传递到seat_select.select_by_value()中去
seat_select.select_by_value(seat_type)
except NoSuchElementException:
continue
else:
break
6. 提交订单
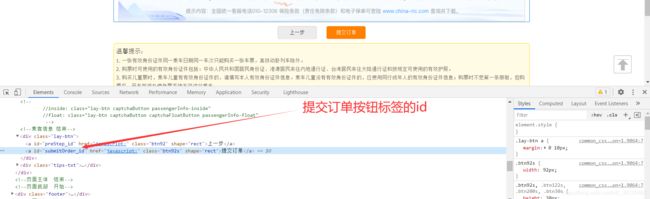
下面我们来提交订单,我们右键检查,在源代码中找到提交订单的按钮标签:
代码:
# 座位类别一共两个,我们遍历一下
for seat_type in seat_types:
try:
# 将座位类别传递到seat_select.select_by_value()中去
seat_select.select_by_value(seat_type)
except NoSuchElementException:
continue
else:
break
# 提交订单
sub_btn = driver.find_element_by_id('submitOrder_id')
sub_btn.click() # 点击提交
成功以后,系统会在后台为我们生成一个订单。
执行一下,报错:
raceback (most recent call last):
File "D:/work/爬虫/Day13/demo_12306.py", line 166, in
main()
File "D:/work/爬虫/Day13/demo_12306.py", line 161, in main
spider = TrainSpider('西安', '郑州', '2021-01-30',{'G430':['O','M']})
TypeError: __init__() missing 1 required positional argument: 'passengers'
位置参数:乘客姓名没有传入。填写姓名后再执行,又报错:
已经登录成功
Traceback (most recent call last):
File "D:/work/爬虫/Day13/demo_12306.py", line 166, in
main()
File "D:/work/爬虫/Day13/demo_12306.py", line 162, in main
spider.run()
File "D:/work/爬虫/Day13/demo_12306.py", line 157, in run
self.search_left_ticket()
File "D:/work/爬虫/Day13/demo_12306.py", line 114, in search_left_ticket
if is_searched:
UnboundLocalError: local variable 'is_searched' referenced before assignment
赋值前引用了局部变量 ‘is_searched’ 。这个变量忘记先定义和赋值了,补上:
# 获取tr标签
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
is_searched = False # 在这里先赋值变量,不然后面调用此变量时会报错
for train_tr in train_trs: # 遍历所有的车次
# train_tr_lst = train_tr.text.split('\n')
train_tr_lst = train_tr.text.replace('\n',' ').split(' ')
# print(train_tr_lst)
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
# count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
count = train_tr_lst[9]
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
再次执行,没有报错,但是没有点击预定按钮动作。用一下之前的办法execut_script:
if is_searched:
seat_select = train_num # 点击时确定了的车次,以备后面选择席位类别使用,在这里调用不了,我们可以添加到初始化变量里
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
driver.execute_script('arguments[0].click();', order_btn)
break # 退出
再次执行,这一次时票卖完了,还是没有报错。改了一趟车。再执行一次。
这次到了这一步:

没有勾选乘客,也没有提交订单。显然,点击动作又没有生效。为避免类似问题,后面一处也换成了execut_script()方法来点击:
勾选乘客姓名动作
for passenger_lable in passenger_lables: # 遍历姓名标签
name = passenger_lable.text # 提取姓名字符串
if name in self.passengers: # 如果标签里的姓名在购票姓名列表里
driver.execute_script('arguments[0].click();', passenger_lable)
# passenger_lable.click() # 点击勾选乘客姓名动作
提交订单动作
# 座位类别一共两个,我们遍历一下
for seat_type in seat_types:
try:
# 将座位类别传递到seat_select.select_by_value()中去
seat_select.select_by_value(seat_type)
except NoSuchElementException:
continue
else:
break
# 提交订单
sub_btn = driver.find_element_by_id('submitOrder_id')
# sub_btn.click() # 点击提交
driver.execute_script('arguments[0].click();', sub_btn)
再执行一次。
仍然没有选择乘客姓名,仔细研究发现不同的乘客姓名的xpath路径时不一样的,于是使用正则修改一下:
passenger_lables = driver.find_elements_by_xpath('//*[@id="normal_passenger_id"]/li[.]/label') # 将li[]里面的数字用.代替
这次还不行,直接去掉里面的数字,再式。
还不行,还是手写吧:
'//ul[@id="normal_passenger_id"]/li/label'
还不行,这时发现一行代码高亮,说明有错误
def confirm_passengers(self, passenger_label=None):
# 确认页面
WebDriverWait(driver, 300).until(
EC.url_contains(self.confirm_url)
)
WebDriverWait(driver, 300).until(
EC.presence_of_element_located(By.XPATH, '//ul[@id="normal_passenger_id"]/li/label')
)
# WebDriverWait(driver, 300).until(
# EC.presence_of_element_located((By.XPATH, '//ul[@id="normal_passenger_id"]/li/label'))
# )
将老师的代码复制过来仔细检查发现,我的少了一对括号,加上应该可以了。
还是不行,头大。最后发现一点,我乘客姓名传入的方法不对,应该以列表的形式:
spider = TrainSpider('漯河', '西安', '2021-02-01', {'G836': ['O', 'M']}, '李丙勋')
应该是这样的
spider = TrainSpider('漯河', '西安', '2021-02-01', {'G836': ['O', 'M']}, ['李丙勋'])
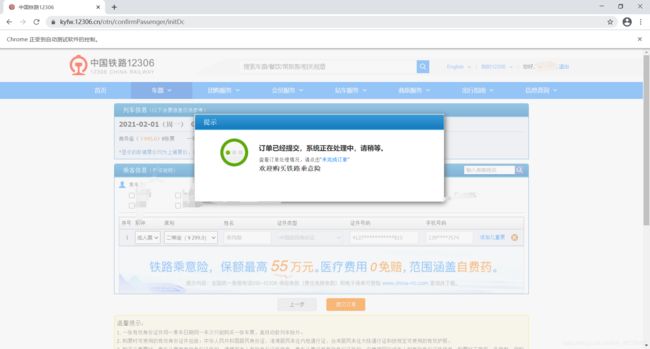
后来还是没有成功。仔细检查并修改了若干次,最后终于成功了,见截图:
其中有这样几个错误:
- 代码缺失 发现run方法里面竟然缺少调用confirm_passengers()的代码
- 类属性调用方法错误 在调用seat_select,并赋值seat_select = train_num时错误,正确的调用方法应该是:self.seat_select = train_num
- 变量名拼写错误,把label错拼成lable
最后修改后,成功的生成了订单。刚好需要给家父买春节来西安过年的票,就用这个项目购买了,做个纪念。愿我十分的努力,换来他一点欣慰。
7. 最后正确的代码
最后,把正确的代码,也就是购票成功的代码放在这里,以便查看复习。
# @Time : 2021/1/27 11:30
# @Author : Guanghui Li
# @File : my12306_0.py
# @Software: PyCharm
import csv
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
from selenium.webdriver.support.ui import Select # 在选择席位类别时用到
from selenium.common.exceptions import NoSuchElementException,ElementNotVisibleException # 当所选的座位类别卖完时用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
confirm_url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc' # 确认购买页面
def __init__(self, from_station, to_station, train_data, train_wanted, passengers):
"""
:param from_station: 出发站
:param to_station: 目的站
:param train_data: 出发日期
:param train_wanted: 想要的车次
:param passengers: 要购票的乘客姓名,是列表形式 ['张三’,'李四']
"""
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.train_wanted = train_wanted
self.passengers = passengers
self.seat_select = None
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
'''
'TrainSpider' object has no attribute 'station_codes_dict' # 其中的一次报错
'''
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver, 300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
driver.get(self.left_ticket_url)
# 出发地
from_station_input = driver.find_element_by_id('fromStation') # 找到出发地输入框元素
from_station_code = self.station_codes_dict[self.from_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % from_station_code, from_station_input) # 把实例出发地传入输入框
# 上面这行代码的解释:"arguments[0].value"这是Java里的占位符,"%s"这是python里的占位符
# %from_station_code,from_station_input这句意思是用后面的from_station_input被前面的from_station_code代替
# 目的地
to_station_input = driver.find_element_by_id('toStation') # 找到目的地输入框元素
to_station_code = self.station_codes_dict[self.to_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % to_station_code, to_station_input) # 把实例目的地传入输入框
# 出发日期
train_date_input = driver.find_element_by_id('train_date')
driver.execute_script('arguments[0].value="%s"' % self.train_data, train_date_input)
# 查询按钮
search_btn = driver.find_element_by_id('query_ticket')
# search_btn.click() # 点击查询按钮
ag_btn = driver.find_element_by_id('qd_closeDefaultWarningWindowDialog_id')
ag_btn.click() # 点击通告按钮
driver.execute_script('arguments[0].click();', search_btn)
# 解析车次信息
WebDriverWait(driver, 300).until(
EC.presence_of_all_elements_located((By.XPATH, '//tbody[@id="queryLeftTable"]/tr'))
)
# 获取tr标签
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
is_searched = False # 在这里先赋值变量,不然后面调用此变量时会报错
for train_tr in train_trs: # 遍历所有的车次
# train_tr_lst = train_tr.text.split('\n')
train_tr_lst = train_tr.text.replace('\n', ' ').split(' ')
# print(train_tr_lst)
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
# count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
count = train_tr_lst[9]
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
elif seat_type == 'M': # 如果有一等座
count = train_tr_lst[8] # 提取出一等座的信息,一等座的索引值是8
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
if is_searched:
self.seat_select = train_num # 点击时确定了的车次,以备后面选择席位类别使用,在这里调用不了,我们可以添加到初始化变量里
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
driver.execute_script('arguments[0].click();', order_btn)
break # 退出
def confirm_passengers(self, passenger_label=None):
# 确认页面
WebDriverWait(driver, 300).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="normal_passenger_id"]/li[3]/label'))
)
passenger_labels = driver.find_elements_by_xpath('//ul[@id="normal_passenger_id"]/li/label')
for passenger_label in passenger_labels: # 遍历姓名标签 //*[@id="normal_passenger_id"]/li[2]/label
name = passenger_label.text # 提取姓名字符串 '//ul[@id="normal_passenger_id"]/li/label'
print(name)
if name in self.passengers: # 如果标签里的姓名在购票姓名列表里
# driver.execute_script('arguments[0].click();', passenger_label)
print('购票者:',name)
passenger_label.click() # 点击勾选乘客姓名动作
# 确认需要购买的席位信息
seat_select = Select(driver.find_element_by_id('seatType_1')) # 将找到的select标签座位参数传递到Select类里面去
seat_types = self.train_wanted[self.seat_select] # train_wanted这个时输入的车次字典,self.seat_select这个是车次的键,取出车次字典里面的值:座位类别
# 座位类别一共两个,我们遍历一下
for seat_type in seat_types:
try:
# 将座位类别传递到seat_select.select_by_value()中去
seat_select.select_by_value(seat_type)
except NoSuchElementException:
continue
else:
break
# 提交订单
sub_btn = driver.find_element_by_id('submitOrder_id')
# sub_btn.click() # 点击提交
driver.execute_script('arguments[0].click();', sub_btn)
WebDriverWait(driver, 1000).until(
EC.presence_of_element_located((By.CLASS_NAME, 'dhtmlx_window_active'))
)
btn = driver.find_element_by_id('qr_submit_id')
driver.execute_script('arguments[0].click();', btn)
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
# 2. 确定购买
self.confirm_passengers()
def main(): # 用来调用各个方法
spider = TrainSpider('漯河', '西安', '2021-02-01', {'G836': ['O', 'M']}, ['李丙勋'])
spider.run()
if __name__ == '__main__':
main()
# 确认购买页面 url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc'
8. 改进后的代码
# @Time : 2021/1/27 22:36
# @Author : Guanghui Li
# @File : testDemo_12306.py
# @Software: PyCharm
import csv
from selenium import webdriver
# from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
# from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait # 条件等待需要用
from selenium.webdriver.support import expected_conditions as EC # 设置等待条件时要用到
from selenium.webdriver.support.ui import Select # 在选择席位类别时用到
from selenium.common.exceptions import NoSuchElementException,ElementNotVisibleException # 当所选的座位类别卖完时用到
driver = webdriver.Chrome() # 类放在全局里面,避免类调用后销毁的时候,连同驱动一同销毁。
class TrainSpider():
login_url = 'https://kyfw.12306.cn/otn/resources/login.html' # 登录界面
personal_url = 'https://kyfw.12306.cn/otn/view/index.html' # 登陆后个人界面
left_ticket_url = 'https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc' # 车次余票的url
confirm_url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc' # 确认购买页面
def __init__(self, from_station, to_station, train_data, train_wanted, passengers):
"""
:param from_station: 出发站
:param to_station: 目的站
:param train_data: 出发日期
:param train_wanted: 想要的车次
:param passengers: 要购票的乘客姓名,是列表形式 ['张三’,'李四']
"""
self.from_station = from_station
self.to_station = to_station
self.train_data = train_data
self.train_wanted = train_wanted
self.passengers = passengers
self.seat_select = None
self.station_codes_dict = {} # 把车站信息字典放在初始化方法里,方便调用
self.init_station_code() # 在初始化方法里面就调用车站信息读取方法,这样当这个类一旦初始化完成的时候,所有的站点也都初始化好待用了
'''
'TrainSpider' object has no attribute 'station_codes_dict'
'''
def init_station_code(self): # 读取stations.csv文件,并新键字典,把车站名作为建,车站代号作为值
# station_codes_dict = {} # 假如我们把这个字典放在这里,那么其他方法相使用就使用不了,所以我们可以把它放到初始化方法里。
with open('stations.csv', 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
for line in reader:
name = line['name']
code = line['code']
self.station_codes_dict[name] = code # 这里我们只需要调用一下初始化方法里的字典
def login(self):
driver.get(self.login_url)
driver.maximize_window() # 窗口最大化
WebDriverWait(driver, 300).until(
EC.url_contains(self.personal_url)
)
print('已经登录成功')
def search_left_ticket(self):
driver.get(self.left_ticket_url)
# 出发地
from_station_input = driver.find_element_by_id('fromStation') # 找到出发地输入框元素
from_station_code = self.station_codes_dict[self.from_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % from_station_code, from_station_input) # 把实例出发地传入输入框
# 上面这行代码的解释:"arguments[0].value"这是Java里的占位符,"%s"这是python里的占位符
# %from_station_code,from_station_input这句意思是用后面的from_station_input被前面的from_station_code代替
# 目的地
to_station_input = driver.find_element_by_id('toStation') # 找到目的地输入框元素
to_station_code = self.station_codes_dict[self.to_station] # 从字典中提取车站代号
driver.execute_script('arguments[0].value="%s"' % to_station_code, to_station_input) # 把实例目的地传入输入框
# 出发日期
train_date_input = driver.find_element_by_id('train_date')
driver.execute_script('arguments[0].value="%s"' % self.train_data, train_date_input)
# 查询按钮
search_btn = driver.find_element_by_id('query_ticket')
# search_btn.click() # 点击查询按钮
ag_btn = driver.find_element_by_id('qd_closeDefaultWarningWindowDialog_id')
ag_btn.click() # 点击通告按钮
driver.execute_script('arguments[0].click();', search_btn) # 点击查询按钮
# 解析车次信息
WebDriverWait(driver, 300).until(
EC.presence_of_all_elements_located((By.XPATH, '//tbody[@id="queryLeftTable"]/tr'))
)
# 获取tr标签
train_trs = driver.find_elements_by_xpath('//tbody[@id="queryLeftTable"]/tr[not(@datatran)]')
is_searched = False # 在这里先赋值变量,不然后面调用此变量时会报错
for train_tr in train_trs: # 遍历所有的车次
# train_tr_lst = train_tr.text.split('\n')
train_tr_lst = train_tr.text.replace('\n', ' ').split(' ')
# print(train_tr_lst)
train_num = train_tr_lst[0] # 车次
if train_num in self.train_wanted: # 如果出现的车次有我们要的车次
seat_types = self.train_wanted[train_num] # 提取出我们所要的车次的座位类型
for seat_type in seat_types: # 遍历席位类型
if seat_type == 'O': # 如果有二等座
# count = train_num[9] # 提取出二等座的信息,二等座的索引值是9
count = train_tr_lst[9]
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
elif seat_type == 'M': # 如果有一等座
count = train_tr_lst[8] # 提取出一等座的信息,一等座的索引值是8
if count.isdigit() or count == '有': # 如果二等座的信息是数字,或者是'有'字
is_searched = True
# order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
if is_searched:
self.seat_select = train_num # 点击时确定了的车次,以备后面选择席位类别使用,在这里调用不了,我们可以添加到初始化变量里
order_btn = train_tr.find_element_by_xpath('.//a[@class="btn72"]') # 预定按钮
# order_btn.click() # 点击
driver.execute_script('arguments[0].click();', order_btn) # 点击预定按钮
break # 退出
else:
print('你所查询的车次已经无票或只有商务票') # 如果我们所能接受的座席类型都售罄,就执行该语句
def confirm_passengers(self, passenger_label=None):
# 确认页面
WebDriverWait(driver, 300).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="normal_passenger_id"]/li[3]/label'))
)
# 上面的代码为了保证购票者的信息加载完成,下面的勾选操作有效
passenger_labels = driver.find_elements_by_xpath('//ul[@id="normal_passenger_id"]/li/label')
for passenger_label in passenger_labels: # 遍历姓名标签 //*[@id="normal_passenger_id"]/li[2]/label
name = passenger_label.text # 提取姓名字符串 '//ul[@id="normal_passenger_id"]/li/label'
print(name) # 打印出所有的自己账号上添加的购票人姓名
if name in self.passengers: # 如果标签里的姓名在购票姓名列表里
# driver.execute_script('arguments[0].click();', passenger_label)
print('购票者:',name) # 打印购票者姓名
passenger_label.click() # 点击勾选乘客姓名动作
# 确认需要购买的席位信息
seat_select = Select(driver.find_element_by_id('seatType_1')) # 将找到的select标签座位参数传递到Select类里面去
seat_types = self.train_wanted[self.seat_select] # train_wanted这个时输入的车次字典,self.seat_select这个是车次的键,取出车次字典里面的值:座位类别
# 座位类别一共两个,我们遍历一下
for seat_type in seat_types:
try:
# 将座位类别传递到seat_select.select_by_value()中去
seat_select.select_by_value(seat_type) # 这句是用Select类操作方法,选择座位类别,把我们接受的座位类别传递给driver
except NoSuchElementException:
continue
else: # 遍历完成后仍然没有,就break
break
# 提交订单
sub_btn = driver.find_element_by_id('submitOrder_id')
# sub_btn.click() # 点击提交
driver.execute_script('arguments[0].click();', sub_btn) # 点击提交
WebDriverWait(driver, 1000).until(
EC.presence_of_element_located((By.CLASS_NAME, 'dhtmlx_window_active'))
) # 等待确认购票窗口加载完成
btn = driver.find_element_by_id('qr_submit_id') # 确认购买按钮
driver.execute_script('arguments[0].click();', btn) # 点击确认
def run(self): # 用来封装项目的基本功能,比如买票,只要调用这个方法就可以实现相应功能
# 1. 登录
self.login()
# 2. 车次以及余票查询
self.search_left_ticket()
# 2. 确定购买
self.confirm_passengers()
def main(): # 用来调用各个方法
spider = TrainSpider('漯河', '西安', '2021-02-01', {'G2388': ['O', 'M']}, ['李光辉'])
spider.run()
if __name__ == '__main__':
main()
# 确认购买页面 url = 'https://kyfw.12306.cn/otn/confirmPassenger/initDc'
本次博客到此结束。