Python爬虫学习笔记-第十七课(多线程与爬虫)
多线程与爬虫-爬取王者荣耀高清壁纸
- 1. 常规方法
-
- 1.1 案例思路
- 1.2 代码编写
- 2. 多线程方法
-
- 2.1 代码思路
- 2.2 完整代码
- 3. 采用selenium方法
-
- 3.1 代码思路
- 3.2 完整代码
1. 常规方法
1.1 案例思路
目标:爬取王者荣耀官网上的高清壁纸,如下图。

但是,这些图片的url在网页源代码中是找不到的,网站对图片数据做了一定的反爬。此时,通常的做法是在network里寻找数据接口,本案例中就是worklist,如下图:
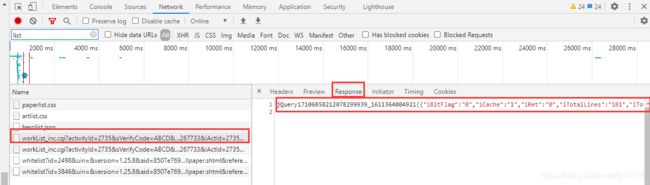
它对应的response是一个json字符串,我们可以把该字符串复制到json.cn网站进行解析,字符串需去除jQuery17106858212078299939_1611364004921以及其关联的圆括号,如下图:
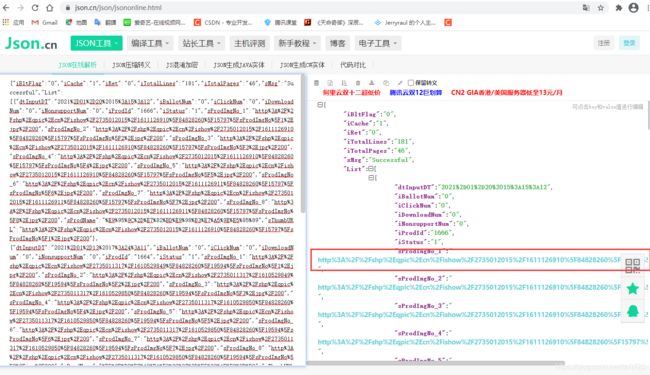
在代码中如何获取到该json字符串:首先找到worklist对应的Request Url,但是这个url不能直接使用,里面包含了json的回调参数&jsoncallback=jQuery17106858212078299939_1611364004921,需要将其去除,才能访问url得到正确的数据,这部分涉及js逆向有关知识点,笔者在这先不拓展了。
https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?
activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1
&jsoncallback=jQuery17106858212078299939_1611364004921&iAMSActivityId=51991&_everyRead=true&iTypeId=1
&iFlowId=267733&iActId=2735&iModuleId=2735&_=1611364005076
将处理后的url放入浏览器,进行访问,得到如下结果:

拿到上述json字符串后,将其转化为python字典,我们就可以进行一系列的操作,提取图片名字以及不同尺寸壁纸的url,然后下载保存。
1.2 代码编写
完整代码如下:
import os
import requests
from urllib import parse
from urllib import request
class KingHonor(object):
def __init__(self):
self.target_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=4&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=1&iFlowId=267733&iActId=2735&iModuleId=2735&_=1611364005076'
self.req_headers = {
'referer': 'https://pvp.qq.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
self.size_lst = ['1024_768', '1280_720', '1280_1024', '1440_900', '1920_1080', '1920_1200','1920_1440']
# 获取包含图片url信息的json字符串,并将其转化为python字典
def get_jsondata(self):
res_obj = requests.get(self.target_url, headers=self.req_headers)
# 将json类型的数据转换成python字典
result = res_obj.json() # requests第三方库提供的方法
# datas = json.loads(res_obj.text) # python内置的模块提供的方法
pict_datas = result['List']
return pict_datas
# 获取不同规格图片的url,返回一个url列表
def extract_images(self, data):
image_urls = []
for i in range(2, 9):
# 将字符串进行解码后,替换‘200’为‘0’
image_url = parse.unquote(data[f'sProdImgNo_{i}']).replace('200', '0')
image_urls.append(image_url)
return image_urls
# 下载图片到本地
def download_pictures(self, pict_datas):
for path_index, pict_data in enumerate(pict_datas):
# 获取图片的url
image_urls = self.extract_images(pict_data)
# 获取图片的名字
pict_name = parse.unquote(pict_data['sProdName'])
# 创建文件夹 image\pict_name+index\
dirpath = os.path.join('image', pict_name + str(path_index+1))
os.mkdir(dirpath)
# 下载一个英雄所有尺寸的图片
for index, image_url in enumerate(image_urls):
request.urlretrieve(image_url, os.path.join(dirpath, self.size_lst[index]+'.jpg'))
print(f'{pict_name} download successfully.')
def run(self):
picture_datas = self.get_jsondata()
self.download_pictures(picture_datas)
if __name__ == '__main__':
kh = KingHonor()
kh.run()
运行结果:
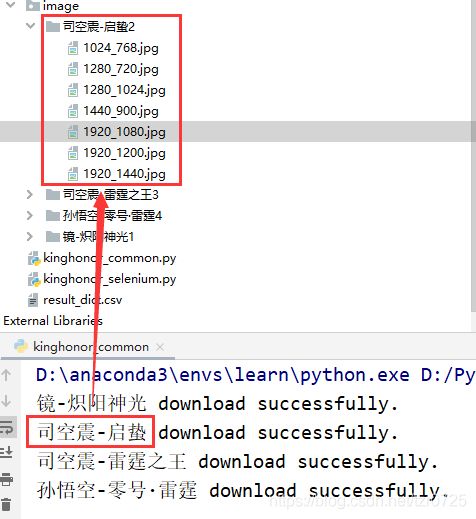
这里笔者不小心把worklist搞错了,实际下载的是新新英雄皮肤壁纸,不过方法和原理都是类似的。
总结采用request方法爬取目标图片的大致过程:
- 发现数据不在网页源码当中,然后通过NetWork找到了一个数据接口worklist;
- response 复制到了json.cn网站 数据是错误的
jsoncallback=Jquery的数据删掉; - 每一个Object就是一组图片,sProdImgNo_1表示封面小图:
3.1 通过编号来获取不同规格的图片,必须把将url中的’200’替换为’0’;
3.2 发现图片的url做了编码,需采用parse.unquote进行解码; - 动态添加图片保存路径os.path.join();
- 以像素尺寸为图片命名,采用enumerate()动态获取像素尺寸命名:1024_768.jpg等。
2. 多线程方法
2.1 代码思路
队列1存放的是每一页的url地址,生产者去请求并解析每一页的url地址,主要目的是获取图片的名字及其对应的url。
队列2存放的是图片的url以及name,消费者从队列2当中请求图片的url地址并下载图片。
2.2 完整代码
import os
import threading
import queue
import time
from urllib import request
from urllib import parse
import requests
req_headers = {
'referer': 'https://pvp.qq.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
produce_finish = False
# 定义生产者
class Producer(threading.Thread):
def __init__(self, page_queue, image_queue, *args, **kwargs):
super(Producer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.image_queue = image_queue
self.size_lst = ['1024_768', '1280_720', '1280_1024', '1440_900', '1920_1080', '1920_1200', '1920_1440']
# 获取不同规格图片的url,返回一个url列表
def extract_images(self, data):
image_urls = []
for i in range(2, 9):
# 将字符串进行解码后,替换‘200’为‘0’
image_url = parse.unquote(data[f'sProdImgNo_{i}']).replace('200', '0')
image_urls.append(image_url)
return image_urls
def run(self) -> None:
# 队列里还有url数据,就继续生产
while not self.page_queue.empty():
page_url = self.page_queue.get()
res = requests.get(page_url, headers=req_headers)
result = res.json()
pict_datas = result['List']
for pict_index, pict_data in enumerate(pict_datas):
image_urls = self.extract_images(pict_data)
pict_name = parse.unquote(pict_data['sProdName'])
dirpath = os.path.join('image', pict_name+str(pict_index+1))
# 如果文件夹不存在
if not os.path.exists(dirpath):
os.mkdir(dirpath)
# 把图片的url放到队列当中
for index, image_url in enumerate(image_urls):
dict = {
}
dict['image_url'] = image_url
dict['image_path'] = os.path.join(dirpath, self.size_lst[index] + '.jpg')
self.image_queue.put(dict)
print(page_url, 'produce has finished.')
# 定义消费者
class Consumer(threading.Thread):
def __init__(self, image_queue, *args, **kwargs):
super(Consumer, self).__init__(*args, **kwargs)
self.image_queue = image_queue
def run(self) -> None:
# 生产者线程还没有结束
while not produce_finish or not self.image_queue.empty():
if not self.image_queue.empty():
image_obj = self.image_queue.get()
# 获取图片的url 和下载的路径
image_url = image_obj.get('image_url')
image_path = image_obj.get('image_path')
# 下载图片
try:
request.urlretrieve(image_url, image_path)
except:
print(image_path, 'download failed.')
else:
time.sleep(1)
if __name__ == '__main__':
# 创建页数的队列(队列一)
page_queue = queue.Queue(5)
# 创建图片队列(队列二)
image_queue = queue.Queue(1000)
# 目标url为网站的前两页
for i in range(0, 2):
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={page}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1611144188371'.format(page=i)
# 把页数的url放到队列当中
page_queue.put(page_url)
# 定义两个生产者线程
pro_ths = []
for x in range(2):
th = Producer(page_queue, image_queue)
th.start()
pro_ths.append(th)
# 定义四个消费者线程
con_ths = []
for x in range(4):
th = Consumer(image_queue)
th.start()
con_ths.append(th)
# 确保生产者线程全部结束
for i in range(len(pro_ths)):
pro_ths[i].join()
produce_finish = True
# 确保消费者线程全部结束
for i in range(len(con_ths)):
con_ths[i].join()
运行结果:

总结多线程的方式去爬取壁纸:
- 翻页 page=0 第一页,以此类推,用格式化字符串获取网页url;
- 创建了2个生产者线程,4个消费者线程 (因为消费者做的事情比较多,发起请求,保存图片);
- 生产者线程中只要page_queue不为空,就继续生产;
- 消费者线程中循环退出的条件是生产者线程结束,并且image_queue队列已空。
3. 采用selenium方法
3.1 代码思路
高清壁纸中不同像素尺寸对应的标签如下图:

大致流程:
- 用selenium访问目标url后,显式等待高清壁纸的标签加载完成;
- 采用xpath获取图片的名字和不同尺寸的url;
- 动态添加图片保存路径,给图片命名(这一步与之前的方法一致)。
3.2 完整代码
import os
from urllib import parse
from urllib import request
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support import expected_conditions as EC
# 创建驱动,将其设为全局变量
driver = webdriver.Chrome()
class KingHonorSele(object):
def __init__(self):
self.url = 'https://pvp.qq.com/web201605/wallpaper.shtml'
self.size_lst = ['1024_768', '1280_720', '1280_1024', '1440_900', '1920_1080', '1920_1200', '1920_1440']
# 加载图片
def load_pictures(self):
# 访问目标url
driver.get(self.url)
# 添加显式等待
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.ID, 'Work_List_Container_267733'))
)
print('图片加载完成.')
# 获取图片名字和url
def get_url_name(self):
# 获取英雄姓名标签
hero_name_tags = driver.find_elements_by_xpath('//div[@class="p_newhero_item"]/h4/a')
# print(type(hero_name_tags))
# 壁纸基础xpath语句
picture_base_xpath = '//div[@class="p_newhero_item"]/ul/li[@class="sProdImgDown sProdImgL{}"]/a'
pict_datas = []
for i in range(2, 9):
# 得到图片的xpath
picture_xpath = picture_base_xpath.format(str(i))
# 获取该尺寸对应的所有图片的url标签
picture_url_tags = driver.find_elements_by_xpath(picture_xpath)
# 对于该图片尺寸, 遍历每个英雄
for index, picture_url_tag in enumerate(picture_url_tags):
# name_tag = next(hero_name_tags)
pict_name = hero_name_tags[index].text
pict_url = picture_url_tag.get_attribute('href')
dirpath = os.path.join('image', pict_name + str(index + 1))
# 如果文件夹不存在
if not os.path.exists(dirpath):
os.mkdir(dirpath)
pict_path = os.path.join(dirpath, self.size_lst[i-2]+'.jpg')
path_url = {
}
path_url.setdefault('pict_url', pict_url)
path_url.setdefault('pict_path', pict_path)
pict_datas.append(path_url)
return pict_datas
# 下载图片
def download_pictures(self, pict_datas):
for pict_data in pict_datas:
pict_url = pict_data['pict_url']
pict_path = pict_data['pict_path']
try:
request.urlretrieve(pict_url, pict_path)
except:
print(pict_path, 'download failed.')
def run(self):
self.load_pictures()
pict_datas = self.get_url_name()
self.download_pictures(pict_datas)
if __name__ == '__main__':
khs = KingHonorSele()
khs.run()
运行结果:
