参与百度飞桨深度学习7日打卡营技术心得
前言
最近正在学习python相关的知识,有幸关注了飞桨的公众号,看到了百度正在进行深度学习7日打卡营活动,虽然没有基础,但是还是很想学学,便报名参加了,7天的课程,紧张而又充实,特别感谢百度飞桨的老师们,助教们,还有服务器的运维人员们,看到老师们认真的教授知识点,助教仔细的答疑,运维人员深夜还在处理平台的问题,真的好像又回到了校园时代,真心对你们说声:你们辛苦了!7天的学习,从一个个实战项目中,学习到了爬虫、数据处理、DNN、CNN及VGG,由浅入深,感觉能学到很多很实用的东西,以后还会持续关注你们的课程。下面分别写下自己的感受,仅供参考:
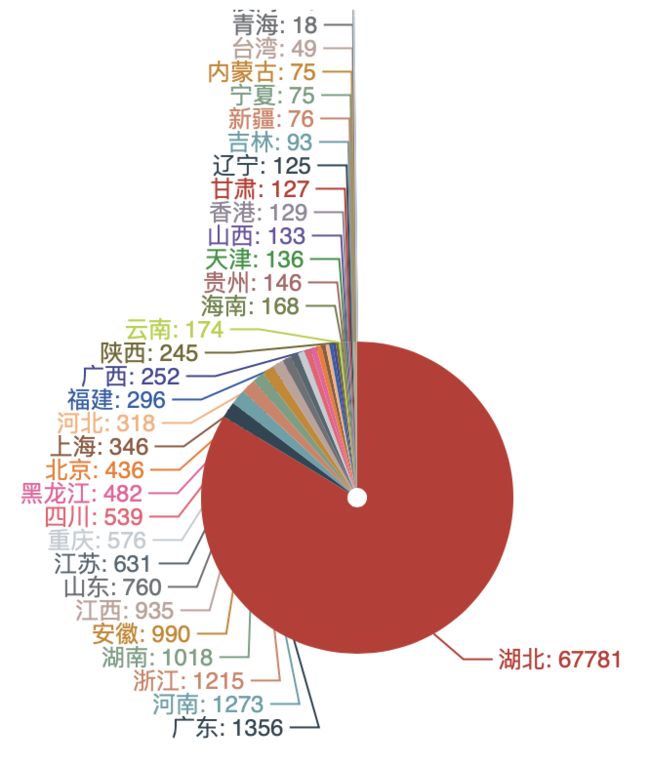
- 疫情可视化项目 ,学习PaddlePaddle的安装及爬虫、图表处理;
- 手势识别 ,学习和使用DNN网络;
- 车牌识别,学习和使用CNN网络;
- 口罩分类,学习并体现下VGG网络的强大;
- 人流密度检测 ,比赛项目实战;
- 模型压缩,PaddleSlim和PaddleLite;
疫情可视化项目
-
1、PaddlePaddle的安装
- 参考这个,选择自己的环境就可以很方便的进行安装
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/index_cn.html
-
2、数据的爬取与保存
-
使用基于丁香园公开的统计数据,利用爬虫爬取并进行本地保存
主要实现过程包括四步:1.发送请求(requests模块)—>2.获取响应数据(服务器返回)—>3.解析并提取数据(re正则)—>4.保存数据
使用的模块:python自带的request,re
感觉不是太难,主要掌握正则表达式,基本都可以OK,下面是主要的正则代码及保存代码
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch',
#re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_text, re.S)
with open("data/statistics_data.json", "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)
-
3、可视化图表展示
-
采用百度的python开源图表框架Pycharts
api可参考: https://pyecharts.org/#/zh-cn/ 直接按照API进行数据处理,一般没有太大的难度
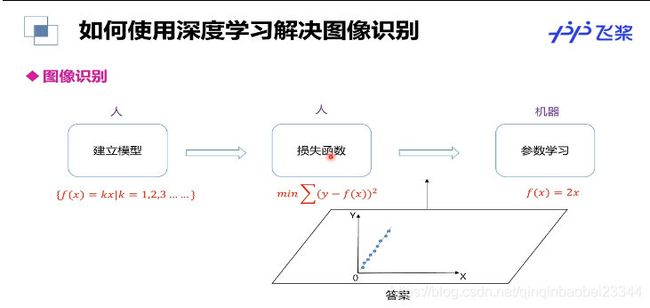
手势识别
学习深度学习的概念及其三部曲
确定函数集合—>评价好坏–>挑出最好的函数,我觉得最主要的过程就是下面的两张图:
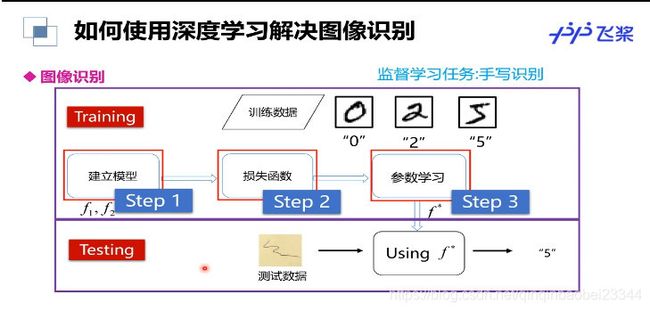
训练列表的生成:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store':
continue
character_imgs = os.listdir(os.path.join(data_path,character_folder))
count = 0
for img in character_imgs:
if img =='.DS_Store':
continue
if count%10 == 0:
f_test.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
else:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
count +=1
全连接DNN网络的配置
# 定义DNN网络
class DNN(fluid.dygraph.Layer):
def __init__(self):
super(DNN, self).__init__()
self.hidden1 = Linear(100,100,act='relu')
self.hidden2 = Linear(100,100,act='relu')
self.hidden3 = Linear(100,100,act='relu')
self.hidden4 = Linear(3*100*100,10,act='softmax')
def forward(self, input):
x = self.hidden1(input)
x = self.hidden2(x)
x = self.hidden3(x)
x = fluid.layers.reshape(x,shape=[-1,3*100*100])
y = self.hidden4(x)
return y
车牌识别
主要对卷积神经网络进行学习
全神经网络虽然很好,但是有其自身的不足,特别是对图像数据无法很好的进行处理,使用全连接神经网络处理图像的最大问题就是:全连接层的参数太多,对于MNIST数据,每一张图片的大小是28281,其中2828代表的是图片的大小,1表示图像是黑白的,有一个色彩通道。假设第一层隐藏层的节点数为500个,那么一个全连接层的神经网络有2828500+500=392500个参数,而且有的图片会更大或者是彩色的图片,这时候参数将会更多。参数增多除了导致计算速度减慢,还很容易导致过拟合的问题。所以需要一个合理的神经网络结构来有效的减少神经网络中参数的个数。卷积神经网络就可以更好的达到这个目的。
# 生成车牌字符图像列表
data_path = '/home/aistudio/data'
character_folders = os.listdir(data_path)
label = 0
LABEL_temp = {
}
if(os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if(os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store' or character_folder == '.ipynb_checkpoints' or character_folder == 'data23617':
continue
print(character_folder + " " + str(label))
LABEL_temp[str(label)] = character_folder #存储一下标签的对应关系
character_imgs = os.listdir(os.path.join(data_path, character_folder))
for i in range(len(character_imgs)):
if i%10 == 0:
f_test.write(os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(label) + '\n')
else:
f_train.write(os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(label) + '\n')
label = label + 1
print('图像列表已生成')
卷积神经网络的主要结构
# 定义网络
class CnnNet(fluid.dygraph.Layer):
def __init__(self):
super(CnnNet,self).__init__()
self.hidden1_1 = Conv2D(1,28,5,1)
self.hidden1_2 = Pool2D(pool_size=2, pool_type='max',pool_stride=1)
self.hidden2_1 = Conv2D(28,32,3,1)
self.hidden2_2 = Pool2D(pool_size=2, pool_type='max',pool_stride=1)
self.hidden3 = Conv2D(32,32,3,1)
self.hidden4 = Linear(32*10*10,65, act='softmax')
def forward(self,input):
x = self.hidden1_1(input)
x = self.hidden1_2(x)
x = self.hidden2_1(x)
x = self.hidden2_2(x)
x = self.hidden3(x)
x = fluid.layers.reshape(x, shape=[-1,32*10*10])
y = self.hidden4(x)
return y
每层的计算 配老师上课的一张手写图:字体可是很好看的哦

口罩分类
在DNN及CNN的基础上,形成的VGG网络。它是Oxford的Visual Geometry Group的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。VGG的重要思想 就是采用固定大小的卷积核
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
主用能够应用于图像分类问题的处理
乱序处理,有助于生成更好的训练集
'''
划分训练集与验证集,乱序,生成数据列表
'''
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path,train_list_path,eval_list_path)
VGG的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
pool_padding=0,
pool_type='max',
conv_stride=1,
conv_padding=1,
act=None):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
pool_padding=pool_padding #填充大小
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return x
人流密度检测
*属于比赛阶段,哈哈哈,自己弄的也不怎么好,就不献丑了。就说下总体的感受吧
练丹需谨慎,小心糊锅,本人胡了好多次,哎。。。
记得抢GPU啊,好的炼丹炉对成功炼丹的帮助不止一星半点

#可视化图片所有标注信息
width = im.size[0] #获取宽度
height = im.size[1] #获取长度
print(width,height)
for a in range(len(ann)): #遍历所有标注
for x in range(width):
for y in range(height):
# r,g,b = im.getpixel((x,y))
if(x > (ann[a]['x']-5) and x < (ann[a]['x']+5) and y > ann[a]['y'] and y < (ann[a]['y']+ann[a]['h'])):
im.putpixel((x,y),(255,0,0)) #画一条长(x,y)到(x,y+h)的红线,红线宽为正负5个像素点
if(x > (ann[a]['x']+ann[a]['w']-5) and x < (ann[a]['x']+ann[a]['w']+5) and y > ann[a]['y'] and y < (ann[a]['y']+ann[a]['h'])):
im.putpixel((x,y),(255,0,0)) #画一条长(x+w,y)到(x+w,y+h)的红线,红线宽为正负5个像素点
if(y > (ann[a]['y']-5) and y < (ann[a]['y']+5) and x > ann[a]['x'] and x < (ann[a]['x']+ann[a]['w'])):
im.putpixel((x,y),(255,0,0)) #画一条长(x,y)到(x+w,y)的红线,红线宽为正负5个像素点
if(y > (ann[a]['y']+ann[a]['h']-5) and y < (ann[a]['y']+ann[a]['h']+5) and x > ann[a]['x'] and x < (ann[a]['x']+ann[a]['w'])):
im.putpixel((x,y),(255,0,0)) #画一条长(x,y+h)到(x+w,y+h)的红线,红线宽为正负5个像素点
plt.imshow(im)
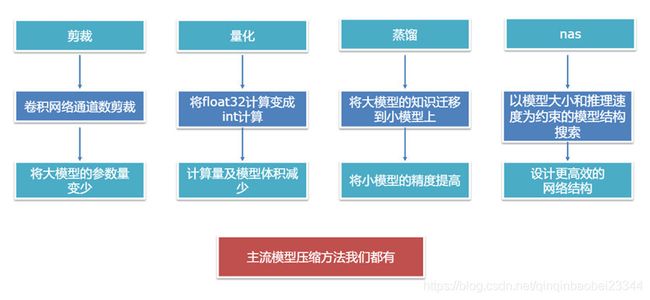
模型压缩
*主要学习和了解PaddleSlim和PaddleLite的使用方法
-
PaddleSlim
-
压缩模型的好的方法:1、将模型的参数量减小;2、提高小模型的精度;3、减少模型计算量;4、设计更高效的网络结构
 PaddleLite
PaddleLite
-
模型部署工具,详细参考下发图表

致谢
最后,再次衷心感谢百度的各位老师们及相关工作人员!