豆瓣250|Python数据爬取
豆瓣250python爬虫项目
- 环境搭建以及相关工具包的下载
-
- 配置python
- 安装lxml、zope.interface
- 安装Twisted、pyOpenSSL
- 安装win32py
- 安装scrapy(关键爬虫框架)
- python爬虫
-
- 创建项目
- 找到要爬取的信息
-
- 建立items
- 更改settings.py
- 编写MySpider
- 编写项目启动文件entrypoint.py
- 运行entrypoint.py
环境搭建以及相关工具包的下载
在进行第一个爬虫项目之前,配置好相关的环境是必要的,这里运用了scrapy的爬虫框架。
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
制作 Scrapy 爬虫 一共需要4步:
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
配置python
这里使用的版本是python3.6版本,在python官网主页即可下载:https://www.python.org/downloads
至于python环境变量的设置和path的路径跟别的java,mysql环境配置是一样的,在网上都有教程。
安装lxml、zope.interface
安装lxml是个非常有用的python库,它可以灵活高效地解析xml,与BeautifulSoup、requests结合,是编写爬虫的标准姿势。在网站http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml找到对应版本,下载下来
打开cmd,输入pip install 下载路径\lxml。
或者直接在命令行输入>pip install lxml
如果输入上述命令行没有反应的话,可以改为输入>python -m pip install lxml
安装zope.interface
可在cmd中用下载命令:python -m pip install zope.interface
安装Twisted、pyOpenSSL
安装Twisted,可在cmd中用下载命令:python -m pip install Twisted,它是用Python实现的基于事件驱动的网络引擎框架。

安装pyOpenSSL
可在cmd中用下载命令:python -m pip install pyOpenSSL安装
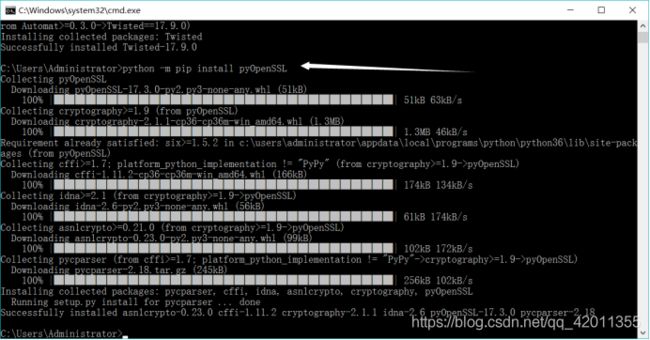
安装win32py
提供win32api,下载地址:
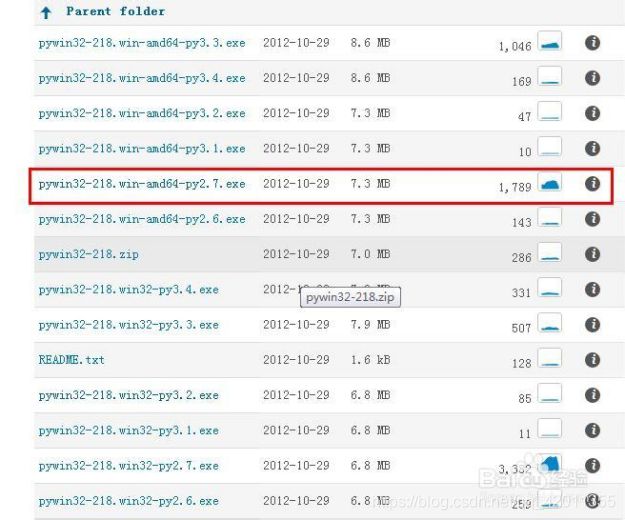
https://sourceforge.net/projects/pywin32/files/
打开的页面里,你会发现有几十个版本的pywin32,怎么找呢?python版本是2.7 64位,我找到的是下面这个。点击它就能直接下载。
下载完成以后,这是一个exe文件,直接双击安装就可以了。点击下一步。

在第二步,你会看到你的python安装目录,如果没有检测到你的python安装目录,八成你现在的pywin32版本是不对的,重新下载。点击下一步

安装状态,显示ready to install以后,点击下一步

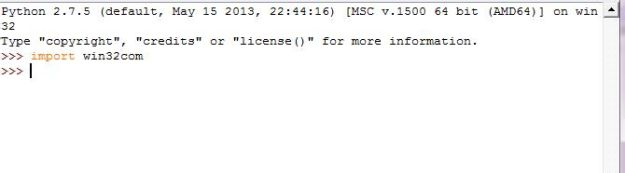
看到这个界面,说明你安装完成,不过你不要高兴太早,我们接着要测试一下是否安装成功

在python中,引入win32com,测试一下,如果没有错误提示,说明安装成功
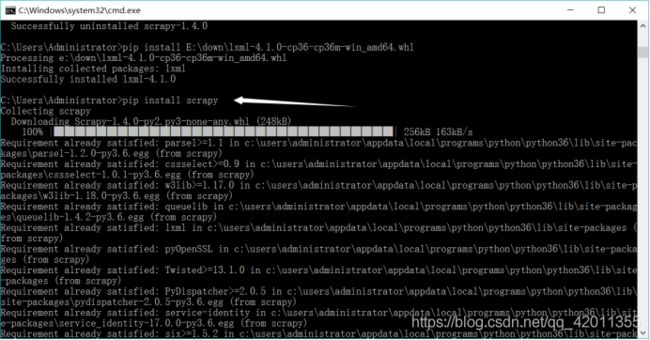
安装scrapy(关键爬虫框架)
直接在cmd中输入>python -m pip install scrapy回车即可
python爬虫
项目目标为:

创建项目
打开命令行,cd找到你想创建工程的路径下,输入:scrapy startproject scrapytest01
文件解释:
scrapytest01:项目名
scrapy.cfg: 项目的配置文件
scrapytest01/: 该项目的python模块。
scrapytest01/items.py: 项目中的item文件,用于爬取的数据结构定义,且存储数据的容器
scrapytest01/pipelines.py: 项目中的pipelines文件,用于处理数据的过程,如清理、去重、验证、存储等.
scrapytest01/settings.py: 项目的设置文件,提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。
scrapytest01/spiders/: 放置spider代码的目录,用于如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item).
然后用python的工程软件打开这个项目文件,我这里选择用的IDEA,打开后是这个样子:
然后在spiders目录下建立MySpider.py用于之后的爬虫代码书写,工程建好,接下来就是寻找要爬取的数据了。
找到要爬取的信息
进入目标网站:https://movie.douban.com/top250
我们的目标是爬取电影250中的电影名称,电影相关人员,电影评分和下方的简要描述。

建立items
点击IDEA中工程下的item.py文件,设计好自己要爬的数据格式items:
items.py:
import scrapy
class DoubanspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#电影标题
title = scrapy.Field()
#电影相关人员
movieInfo = scrapy.Field()
#电影评分
star = scrapy.Field()
#电影简述
quote = scrapy.Field()
更改settings.py
设置好items后,我们返回目标网页,按F12进入开发人员模式,然后找到最上方一栏的网络这一栏并点击,点击左侧请求尽可能靠下方的request的请求,右侧会显示这个请求的相关信息,然后在请求表头中找到这样一行:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134
复制User-Agent后面的值。

然后在项目下settings.py中设置以下代码:
settings.py:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6788.400 QQBrowser/10.3.2767.400'
FEED_EXPORT_ENCODING = 'gb18030'
FEED_URI = u'file://D:/Program Files/IDEA/DoubanSpider/test/test.csv'
FEED_FORMAT = 'CSV'
USER_AGENT这一行是用来伪装访问的,防止爬虫过程ip被封;
FEED_EXPORT_ENCODING这一行是保证爬下来的数据保存以中文的形式;
FEED_URI这一行就是爬下来的数据保存的路径
FEED_FORMAT这一行是爬下来数据保存的形式。
编写MySpider
我们要爬取电影的相关信息,所以我们必须知道它的html部分在哪:
电影在标签div下的class=“item”里面:

电影标题在标签div下class="info"然后是div下class=“hd”,然后a标签,span标签,所以它的xpath路径为:
’div[@class=“info”]/div[@class=“hd”]/a/span/text()'

其他的item也同理,直接上代码,里面有部分解释:
MySpider.py:
from scrapy.spiders import Spider
from DoubanSpider.items import DoubanspiderItem
import scrapy
class MySpider(Spider):
#爬虫名字
name = 'DoubanSpider'
#设置访问域
allowed_domains = ['douban.com']
#开始连接
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item = DoubanspiderItem()
#电影区域的xpath
movies = response.xpath('//div[@class="item"]')
print('============================================')
for each in movies:
#电影标题的xpath
title = each.xpath('div[@class="info"]/div[@class="hd"]/a/span/text()')
#下面的if判断都是用来判断这个区域是否为空,不为空则将这个值记录下来
if title:
item['title'] = title.extract()[0]
#电影相关人员的xpath
movieInfo = each.xpath('div[@class="info"]/div[@class="bd"]/p[@class=""]/text()')
if movieInfo:
item['movieInfo'] = movieInfo.extract()[0].replace(' ','').replace('\n','').replace('\t','').replace('\xa0','').replace('...','')
#电影评分的xpath
star = each.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')
if star:
item['star'] = star.extract()[0]
#电影简述的xpath
quote = each.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()')
if quote:
item['quote'] = quote.extract()[0]
yield item
#定义分页器的xpath,实现每页数据的爬取
nextLink = response.xpath('//span[@class="next"]/a/@href').extract()
if nextLink:
yield scrapy.Request('https://movie.douban.com/top250%s'% nextLink[0],callback=self.parse)
MySpider.py中的东西才是我们爬虫的重中之重:
编写项目启动文件entrypoint.py
entrypoint.py:
from scrapy import cmdline
#DoubanSpider跟MySpider.py中爬虫名称要一致
cmdline.execute(['scrapy','crawl','DoubanSpider'])

运行entrypoint.py
运行程序后,稍等片刻便可在你设置的路径下找到test.csv文件了,里面便是爬取到的数据:

一共250个数据:
