【opencv学习笔记——Kmeans数据聚类与图像分割】
简介
kmeans作为一种聚类算法,可以将数据贴以标签,进而进行数据或图像的数据聚类.
算法原理
Step 1 :从数据集中随机选取一个样本点作为初始聚类中心C1;
Step 2:首先计算每个样本与当前已有聚类中心之间的最短距离(即最近的聚类中心的距离),用D(x)表示;接着计算每个样本点被选为下一个聚类中心的概率D(x)2∑ni=1D(xi)2。最后,按照轮盘法选择出下一个聚类中心;
Step 3:重复第2步知道选择出K个聚类中心;
之后的步骤同原始K-means聚类算法相同;
其中详情可以参考:https://blog.csdn.net/the_lastest/article/details/78288955
也可以参考一个有趣博文: 点此
实际上就是去不断的去寻找几个适合的中心点(离各个点都比较近),给每个中心点周围的点贴以标签,这样就可以区别分类数据
kmeans
函数详解
C++: doublekmeans(InputArraydata,
int K,
InputOutputArray bestLabels,
TermCriteriacriteria,
int attempts, int flags,
OutputArraycenters=noArray() )
data:输入样本,要分类的对象Mat,浮点型,每行一个样本(我要对颜色分类则每行一个像素,RGB图像有三个通道);
K: 类型数目;
bestLabels: int Mat,每个样本对应一个类型 label
TermCriteria criteria:结束条件(最大迭代数和理想精度)
int attempts:根据最后一个参数确定选取的最理想初始聚类中心(选取attempt次初始中心,选择compactness最小的)
int flags :
- KMEANS_RANDOM_CENTERS 随机选取初始化中心点
- KMEANS_PP_CENTERS 自动选取算法
- KMEANS_USE_INITIAL_LABELS 用户自定义但是如果此时的attempts大于1,则后面的聚类初始点依旧使用随机的方式
代码
# include<opencv2\opencv.hpp>
# include <iostream>
using namespace std;
using namespace cv;
int main(int argc, char** argv) {
Mat img(500, 500, CV_8UC3);
RNG rng(12345);
Scalar colortab[] = {
//用于不同的标签数据
Scalar(0,0,255),
Scalar(0,255,0),
Scalar(255,0,0),
Scalar(0,255,255),
Scalar(255,0,255)
};
int numCluster = rng.uniform(2, 5);
printf("number of clusters:%d\n", numCluster);
int sampleCount = rng.uniform(5, 1000);
Mat points(sampleCount, 1, CV_32FC2);
Mat labels;
Mat centers;
//生成随机数
for (int k = 0; k < numCluster; k++) {
Point center;
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
Mat pointChunk = points.rowRange(k*sampleCount / numCluster, //Mat的rowRange和colRange函数可以获取某些范围内行或列的指针
k == numCluster - 1 ? sampleCount : (k + 1)*sampleCount / numCluster);
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));//用随机数填充矩阵
}
randShuffle(points, 1, &rng);//将原数组打乱
//使用Kmeans
kmeans(points, numCluster, labels, TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 0.1), 3, KMEANS_PP_CENTERS, centers);
//用不同颜色显示分类
img = Scalar::all(255);
for (int i = 0; i < sampleCount; i++) {
int index = labels.at<int>(i); //这里labels中的每个i表示每个聚类的标签
Point p = points.at<Point2f>(i);
circle(img, p, 2, colortab[index], -1, 8); //显示每个聚类的颜色不同
}
//以每个聚类的中心绘制圆
for (int i = 0; i < centers.rows; i++) {
int x = centers.at<float>(i, 0);
int y = centers.at<float>(i, 1);
circle(img, Point(x, y), 40, colortab[i], 2, 8, 0);
}
imshow("Kmeans_Data", img);
waitKey(0);
return 0;
}
对于图片数据来说,它的每个像素点(RGB有三个)
// 问题 kmeans函数中的 labels的结构
// 使用 index = row * width + col 岂不是多此一举?
// 不明白Kmeans函数在使用时对于图像像素的计算是不是以像素的大小来计算中心值的?
# include<opencv2\opencv.hpp>
# include <iostream>
using namespace std;
using namespace cv;
Scalar colortab[] = {
Scalar(0,0,255),
Scalar(0,255,0),
Scalar(255,0,0),
Scalar(0,255,255),
Scalar(255,0,255)
};
int main(int argc, char** argv) {
Mat src, dst;
src = imread("E:/tuku/koutu.jpg");
if (src.empty()) {
cout << "can't find this picture...";
return -1;
}
imshow("input", src);
int width = src.cols;
int height = src.rows;
int dims = src.channels();
cout << dims;
//初始化定义
int sampleCount = width * height;
int clusterCount = 4;
Mat points(sampleCount,dims, CV_32F, Scalar(10));
Mat labels;
Mat center(clusterCount, 1, points.type());
//把RBG数据转换到样本数据
int index = 0;
/*for (int row = 0; row < height; row++) {
for (int col = 0; col < width; col++) {
index = row * width + col; //这里很不理解为什么要这么做, 自我理解:一次前进一个单位的width 直到row==height是可以跑满src的一个row
Vec3b bgr = src.at(row, col); //将图像的像素存取到数据中
points.at(index, 0) = static_cast(bgr[0]);
points.at(index, 1) = static_cast(bgr[1]);
points.at(index, 2) = static_cast(bgr[2]);
}
}*/
//初始化定义的另一个做法
Mat data;
for (int row = 0; row < height; row++) {
for (int col = 0; col < width; col++) {
Vec3b brgtow= src.at<Vec3b>(row, col);
Mat tem= (Mat_<float>(1, 3) << brgtow[0], brgtow[1], brgtow[2]);
data.push_back(tem);
}
}
//L-kmeans
TermCriteria criteria = TermCriteria(TermCriteria::COUNT + TermCriteria::EPS, 10, 0.1);
kmeans(data, clusterCount, labels, criteria, 3, KMEANS_PP_CENTERS, center);//若用方法2 只将 points改成data就行
//显示分割图像
Mat result = Mat::zeros(src.size(), src.type());
for (int row = 0; row < height; row++) {
for (int col = 0; col < width; col++) {
index = row * width + col;
int label = labels.at<int>(index,0);
// int clusterIdx = labels.at(n);
//pic.at(i, j) = colorTab[clusterIdx];
//n++; 写成这样我才能理解
result.at<Vec3b>(row, col)[0] = colortab[label][0];
result.at<Vec3b>(row, col)[1] = colortab[label][2];
result.at<Vec3b>(row, col)[2] = colortab[label][1];
}
}
imshow("result", result);
waitKey(0);
return 0;
}

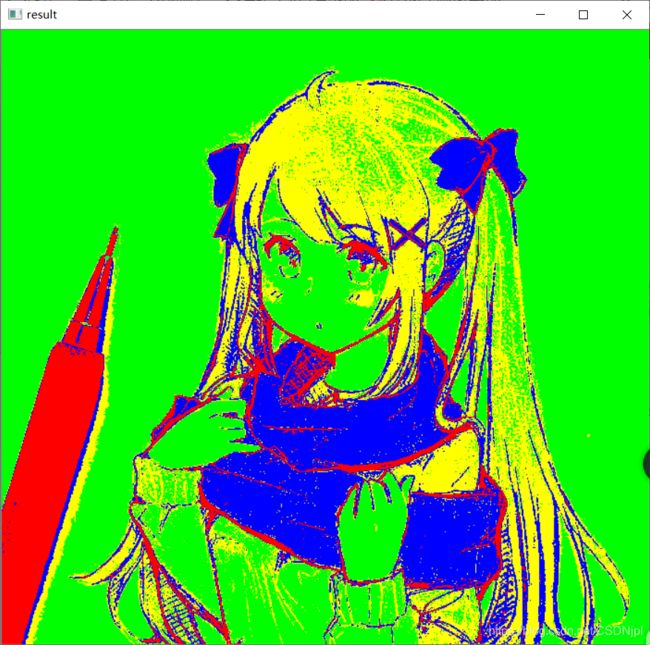
在通过像素进行图像分割时遇到的问题希望看到这篇文章的你可以不吝赐教 .
感谢