从模型搭建到训练,手把手教你Tensorboard可视化训练数据——tensorflow2.0及其以上版本
tensorboard介绍
TensorBoard是tensorflow的一个可视化工具,它可以用来展示训练和验证的loss以及val曲线图、网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。
tensorboard使用
既然tensorboard实用性那么高,但是我们怎么使用它对自己搭建的网络进行可视化呢?相信很多朋友在使用过程中艰难地摸索,最后也未必能取得效果。我在刚开始的时候也是持续踩坑,好在参考多方资料之后自己没有放弃,成功对网络进行了可视化。下面就让我手把手引领大家上手tensorboard吧。
数据集加载
由于我的主要研究方向是表情识别,因此使用的也是目前已经开源使用频率较高的数据库(CASME),数据库中是一张张地图片,我们要先把这些图片制作成tensorflow专用的数据集文件(.TFRecords文件),**制作tfrecord文件的方法后边另写一篇文章专门分享给大家。**数据集制作完成后进行加载,直接附上代码(大家进行试验的时候可以使用自己手上任意数据集,保证模型的输入形状匹配就行)。
train_dataset = tf.data.TFRecordDataset("E:\\CASMEIISpotting\\CASMEIISpotting_CAO_train.tfrecords").map(read_and_decode).shuffle(buffer_size=1000).batch(32)
validation_dataset = tf.data.TFRecordDataset("E:\\CASMEIISpotting\\CASMEIISpotting_CAO_validation.tfrecords").map(read_and_decode).shuffle(buffer_size=1000).batch(32)
test_dataset = tf.data.TFRecordDataset("E:\\CASMEIISpotting\\CASMEIISpotting_CAO_test.tfrecords").map(read_and_decode).shuffle(buffer_size=1000).batch(32)
其中"E:\CASMEIISpotting\CASMEIISpotting_CAO_train.tfrecords"是我制作的tfrecord文件绝对地址,.map是tensorflow提供的解析数据集的方法,.shuffle是数据提取的缓存区容量,这里设置为1000,.batch就是训练过程中每一次使用的样本个数,至此训练集、验证集以及测试集数据已经准备完毕,下一步就是开始搭建我们的网络。
网络搭建
这里我才用的是自己设计的一种CNN网络架构,大家仅供参考,具体问题还是要具体分析。
def SMENet_model():
model = models.Sequential()
#===========================================================================
model.add(layers.Conv2D(filters=96, kernel_size=7, strides=2,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_1", input_shape=( 192, 192, 3)))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_1"))
#===========================================================================
model.add(layers.Conv2D(filters=96, kernel_size=5, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_2"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_2"))
#===========================================================================
model.add(layers.Conv2D(filters=96, kernel_size=5, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_3"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_3"))
#===========================================================================
model.add(layers.Conv2D(filters=128, kernel_size=3, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_4"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_4"))
#===========================================================================
model.add(layers.Conv2D(filters=128, kernel_size=3, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_5"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_5"))
#===========================================================================
model.add(layers.Flatten())
model.add(layers.Dense(500, activation='relu', name="Dense_1"))
model.add(layers.Dense(500, activation='relu', name="Dense_2"))
model.add(layers.Dense(200, activation='relu', name="Dense_3"))
model.add(layers.Dense(2, activation='sigmoid', name="output"))
# Gradient Descent Optimizer
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
metrics = ["accuracy"] # ["accuracy", "sparse_categorical_crossentropy"]
model.compile(optimizer=optimizers.RMSprop(lr=InitialLearningRate, name="RMSprop"), loss=loss, metrics=metrics)
# model.compile(loss="mse", optimizer=optimizers.RMSprop(lr=1e-4), metrics=['accuracy'])
return model
至此模型已经搭建完毕,下边我们就配置一下训练过程中tensorboard的可视化吧。
tensorboard可视化配置
首先,在你电脑的任意地方(看心情)先建立存放日志的文件夹,建立好之后,在程序中声明一下,如下:
output_folder = "C:\\Users\\11468\\Desktop\\ResNet\\SMENet_3Dmodel\\log"
log_dir= os.path.join(output_folder,'logs_{}'.format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S")))
if not os.path.exists(log_dir):
os.makedirs(log_dir)
日志的存储路径创造成功之后,开始配置tensorboard。
tensorboard = tf.keras.callbacks.TensorBoard(log_dir=log_dir,
histogram_freq=1,#对参数和激活做直方图,一定要有测试集
write_graph=True,#模型结构图
write_images=True,#把模型参数做为图片形式存到
update_freq='epoch',#epoch,batch,整数,太频的话会减慢速度
profile_batch=2,#记录模型性能
embeddings_freq=0,
embeddings_metadata=None#这个还不太清楚如何使用
) #各个参数的作用请参看文档,需要正确使用
最后再把callback回调组装好。
callbacks=[lr, earlystop, tensorboard, model_check_point, reduce_lr]
下边就可以开始训练啦。
model.fit(train_dataset, validation_data=validation_dataset,
epochs=4, verbose=1, callbacks=callbacks)
loss, acc = model.evaluate(test_dataset)
print("Transformed model, accuracy: {:5.2f}%".format(100 * acc))
训练完成之后我们要做的就是调用tensorboard进行可视化
可视化步骤
如下图所示就是训练完成之后生成的事件文件,我们需要调用其进行可视化。

找到时间文件之后,我们“Windows + R”打开黑屏终端,输入“conda activate 你的虚拟环境的名字”激活你的虚拟环境,环境激活成功之后,如下图所示,在命令行中输入“tensorboard --logdir ”你的tensorboard文件路径“,回车之后会返回一个网址,在浏览器上输入此网址就可以及进行可视化了。

把网址输入浏览器之后打开看到我们的界面如图所示。
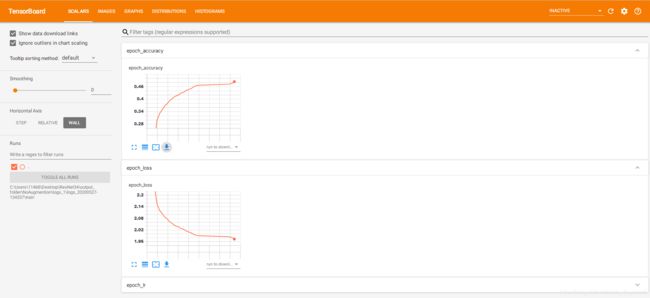
最后附上完整代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 27 18:54:15 2020
@author: Ranlei Cao
@Email : [email protected]
@weixin: Brilliant_eyes
"""
import os
import datetime
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
# model build
InitialLearningRate = 1e-4
lr_decay_epochs = 5
def SMENet_model():
model = models.Sequential()
#===========================================================================
model.add(layers.Conv2D(filters=96, kernel_size=7, strides=2,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_1", input_shape=( 192, 192, 3)))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_1"))
#===========================================================================
model.add(layers.Conv2D(filters=96, kernel_size=5, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_2"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_2"))
#===========================================================================
model.add(layers.Conv2D(filters=96, kernel_size=5, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_3"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_3"))
#===========================================================================
model.add(layers.Conv2D(filters=128, kernel_size=3, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_4"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_4"))
#===========================================================================
model.add(layers.Conv2D(filters=128, kernel_size=3, strides=1,
padding="SAME", data_format="channels_last",
use_bias=True, name="conv_5"))
model.add(layers.MaxPooling2D(pool_size=2, strides=2, name="pool_5"))
#===========================================================================
model.add(layers.Flatten())
model.add(layers.Dense(500, activation='relu', name="Dense_1"))
model.add(layers.Dense(500, activation='relu', name="Dense_2"))
model.add(layers.Dense(200, activation='relu', name="Dense_3"))
model.add(layers.Dense(2, activation='sigmoid', name="output"))
# Gradient Descent Optimizer
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
metrics = ["accuracy"] # ["accuracy", "sparse_categorical_crossentropy"]
model.compile(optimizer=optimizers.RMSprop(lr=InitialLearningRate, name="RMSprop"), loss=loss, metrics=metrics)
# model.compile(loss="mse", optimizer=optimizers.RMSprop(lr=1e-4), metrics=['accuracy'])
return model
model = SMENet_model()
print("model architecture:\n")
model.summary()
# model compile configure
output_folder = "C:\\Users\\11468\\Desktop\\ResNet\\SMENet_3Dmodel\\log"
log_dir= os.path.join(output_folder,'logs_{}'.format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S")))
if not os.path.exists(log_dir):
os.makedirs(log_dir)
save_path = "C:\\Users\\11468\\Desktop\\ResNet\\SMENet_3Dmodel\\cp.ckpt"
model_check_point = tf.keras.callbacks.ModelCheckpoint(filepath=save_path,
monitor="val_accuracy",
verbose=1,
save_best_only=True,
save_weights_only=True,
save_freq="epoch")
#当模型训练不符合我们要求时停止训练,连续5个epoch验证集精度没有提高0.001%停
earlystop=tf.keras.callbacks.EarlyStopping(monitor='val_accuracy',min_delta = 0.0001, patience=5, verbose=0)
# define a class to indicate learningrate is decaying exponentially
class learningRateExponentialDecay:
def __init__(self, InitialLearningRate, decay_epochs, decay_rate):
self.InitialLearningRate = InitialLearningRate
self.decay_epochs = decay_epochs
self.decay_rate = decay_rate
def __call__(self, epoch):
dtype = type(self.InitialLearningRate)
decay_epochs = np.array(self.decay_epochs).astype(dtype)
decay_rate = np.array(self.decay_rate).astype(dtype)
epoch = np.array(epoch).astype(dtype)
p = epoch / decay_epochs
lr = self.InitialLearningRate * np.power(decay_rate, p)
return lr
lr_scheduler = learningRateExponentialDecay(InitialLearningRate, lr_decay_epochs, 0.96)
lr = tf.keras.callbacks.LearningRateScheduler(lr_scheduler, verbose=1)
#降低学习率(要比学习率自动周期变化有更大变化和更长时间监控)
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',factor=0.1,patience=5,
verbose=1, mode="auto", min_lr=0)
#保存训练过程中大数标量指标,与tensorboard同一个文件
csv_logger = tf.keras.callbacks.CSVLogger(os.path.join(log_dir,'logs.log'), separator=',', append=False)
#还要加入tensorboard的使用,这种方法记录的内容有限
tensorboard = tf.keras.callbacks.TensorBoard(log_dir=log_dir,
histogram_freq=1,#对参数和激活做直方图,一定要有测试集
write_graph=True,#模型结构图
write_images=True,#把模型参数做为图片形式存到
update_freq='epoch',#epoch,batch,整数,太频的话会减慢速度
profile_batch=2,#记录模型性能
embeddings_freq=0,
embeddings_metadata=None#这个还不太清楚如何使用
) #各个参数的作用请参看文档,需要正确使用
callbacks=[lr, earlystop, tensorboard, model_check_point, reduce_lr]
# dataset parse
feature_description = {
# 定义Feature结构,告诉解码器每个Feature的类型是什么
'image_raw': tf.io.FixedLenFeature([], tf.string),
'label': tf.io.FixedLenFeature([], tf.int64)
}
def read_and_decode(example_string, normlize=False):
"""
Parameters
----------
example_string : Example created by TFRecordwriter
Returns
-------
dataset.
"""
feature_dict = tf.io.parse_single_example(example_string, feature_description)
image = tf.io.decode_raw(feature_dict['image_raw'], out_type=tf.int8)
image = tf.reshape(image, [192, 192, 3])
label = tf.cast(feature_dict['label'], tf.float32)
if normlize:
image = tf.cast(image, dtype='float32') / 255.
return image, label
train_dataset = tf.data.TFRecordDataset("E:\\CASMEIISpotting\\CASMEIISpotting_CAO_train.tfrecords").map(read_and_decode).shuffle(buffer_size=1000).batch(32)
validation_dataset = tf.data.TFRecordDataset("E:\\CASMEIISpotting\\CASMEIISpotting_CAO_validation.tfrecords").map(read_and_decode).shuffle(buffer_size=1000).batch(32)
test_dataset = tf.data.TFRecordDataset("E:\\CASMEIISpotting\\CASMEIISpotting_CAO_test.tfrecords").map(read_and_decode).shuffle(buffer_size=1000).batch(32)
# model training
model.fit(train_dataset, validation_data=validation_dataset,
epochs=4, verbose=1, callbacks=callbacks)
loss, acc = model.evaluate(test_dataset)
print("Transformed model, accuracy: {:5.2f}%".format(100 * acc))