Sklearn 数据预处理与特征工程 preprocessing&impute
- 数据预处理:目的是为了提高数据质量,使数据挖掘的过程更加有效,更加容易,同时也提高挖掘结果的质量。数据预处理的对象主要是清理其中的噪声数据、空缺数据和不一致数据。
- 特征工程:降低计算成本、提升模型上限
- 模块 preprocessiong: 几乎包含了所有预处理的所有内容
- 模块 Impute:填补缺失值专用
目录:
1、无量纲化
- 线性:中心化处理、缩放处理
- 中心化处理:中心化的本质是让所有记录减去一个固定值,让所有的数据平移到某个位置。
- 缩放处理:缩放的本质是通过处以一个固定值,将数据固定在某个范围之内,取对数也算是一种缩放处理。
- 非线性
2、缺失值
3、处理连续特征
4、生成多项式特征
5、自定义转换器
6、编码分类特征
一、无量纲化
1、线性变换
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
通过减掉均值并将数据缩放到单位方差来标准化特征,标准化完后的特征符合标准正态分布,即方差为1, 均值为0.
sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1), copy=True)
通过最大值最小值将每个特征缩放到给定范围,默认为[0,1]。
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
sklearn.preprocessing.MaxAbsScaler(copy=True)
通过让每一个特征里的数据,除以该特征中绝对值最大的数值,将数据缩放到[-1,1]。这种做法并没有中心化数据,因此不会破坏数据的稀疏性。
sklearn.preprocessing.RobustScaler(with_centering=True, with_scaling=True, quantile_range=(25.0, 75.0), copy=True)
数据集的标准化是通过去除均值,缩放到单位方差来完成, 但是异常值通常会对样本的均值和方差造成负面影响,当异常值很多噪声很大时,用中位数和四分位范围通常会产生更好的效果。
这个缩放器删除中位数,并根据百分数范围缩放数据。
sklearn.preprocessing.Normalizer(norm='l2', copy=True)[source]
norm = ‘l1’, ‘l2’, or ‘max’ (‘l2’ by default)
if “l1”: vector x / sum(abs(x));
if “l2”: vextor x / sum(x^2);
2、非线性变换
sklearn.preprocessing.PowerTransformer(method='yeo-johnson', standardize=True, copy=True)[source]
Power Transformer are applied to make data more Gaussian-like.
Currently, PowerTransformer supports the Box-Cox transform and the Yeo-Johnson transform.
Box-Cox requires input data to be strictly positive, while Yeo-Johnson supports both positive or negative data.
sklearn.preprocessing.QuantileTransformer(n_quantiles=1000, output_distribution='uniform', ignore_implicit_zeros=False, subsample=100000, random_state=None, copy=True)
通过缩小边缘异常值和非异常值之间的距离来提供特征的非线性变换。通过执行一个秩转换能够使异常的分布平滑化,并且能够比缩放更少地受到离群值的影响。但是它的确使特征间及特征内的关联和距离失真了。
该方法将特征变换为均匀分布或正态分布(通过设置output_distribution=‘normal’)。因此,对于给定的特性,这种转换倾向于分散最频繁的值,还减少了(边缘)异常值的影响。
二、缺失值
sklearn.impute.SimpleImputer(missing_values=nan, strategy='mean', fill_value=None, verbose=0, copy=True, add_indicator=False)
| 参数 | 含义&输入 |
|---|---|
| missing_values | 告诉SimpleImputer,数据中的缺失值长什么样,默认空值np.nan |
| strategy | “mean”:使用均值填补;“media”:中值填补;“most_frequent”:众数填补;“constan”:参考fill_value中的数据填补 |
| fill_value | 当参数“strategy”为“constant”时可用,可输入字符串或数字表示要填充的值 |
| copy | 默认为True,将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中去 |
三、处理连续特征
sklearn.preprocessing.Binarizer(threshold=0.0, copy=True)
根据阈值将数据二值化(将特征值设为0或1),大于阈值的值映射为1,小于或等于的值映射为0。
四、生成多项式特征
sklearn.preprocessing.PolynomialFeatures(degree=2, interaction_only=False, include_bias=True, order='C')
For example, if an input sample is two dimensional and of the form [a, b], the degree-2 polynomial features are [1, a, b, a^2, ab, b^2].
五、自定义转换器
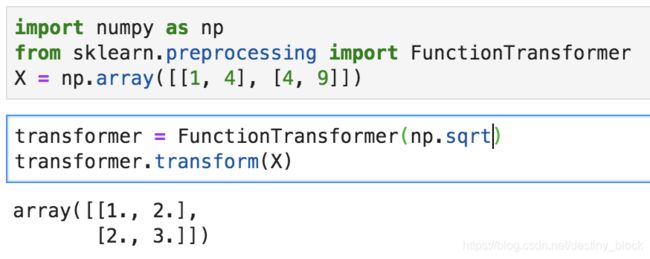
class sklearn.preprocessing.FunctionTransformer(func=None, inverse_func=None, validate=False, accept_sparse=False, check_inverse=True, kw_args=None, inv_kw_args=None)
六、编码分类特征
1、数据特征
sklearn.preprocessing.OrdinalEncoder(categories='auto', dtype=<class 'numpy.float64'>)
将分类特征转换为分类数值。

sklearn.preprocessing.OneHotEncoder(categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error')[source]

2、标签
sklearn.preprocessing.LabelBinarizer(neg_label=0, pos_label=1, sparse_output=False)
Binarize labels in a one-vs-all fashion
dim(result) = (number of data) * (number of targets)

sklearn.preprocessing.LabelEncoder
Encode target labels with value between 0 and n_classes-1.

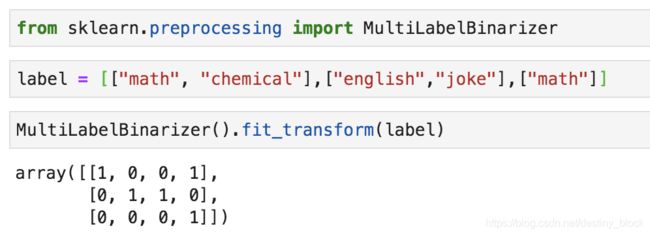
sklearn.preprocessing.MultiLabelBinarizer(classes=None, sparse_output=False)