使用python爬取斗破苍穹小说网
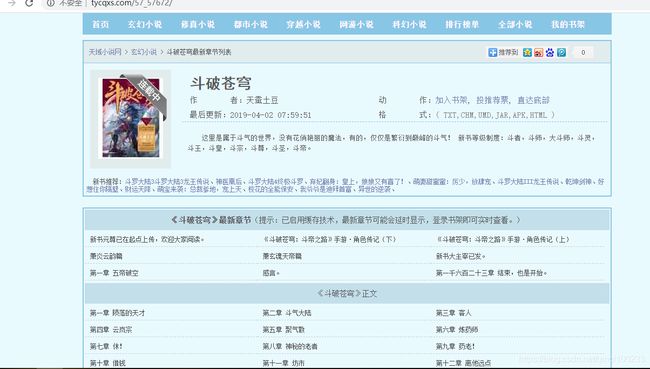
使用python爬取斗破苍穹小说网,学会了以后就不用去看付费的小说了不多bb直接上源码
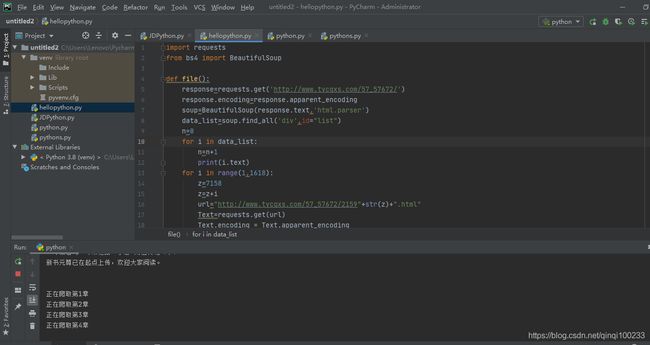
import requests
from bs4 import BeautifulSoup
def file():
response=requests.get('http://www.tycqxs.com/57_57672/')
response.encoding=response.apparent_encoding
soup=BeautifulSoup(response.text,'html.parser')
data_list=soup.find_all('div',id="list")
n=0
for i in data_list:
n=n+1
print(i.text)
for i in range(1,1618):
z=7158
z=z+i
url="http://www.tycqxs.com/57_57672/2159"+str(z)+".html"
Text=requests.get(url)
Text.encoding = Text.apparent_encoding
soup = BeautifulSoup(Text.text, 'html.parser')
comment = soup.find_all('div', id="content")
for p in comment:
c=p.text
path = "E:/python小说爬取/第" + str(i) + "章.txt"
f = open(path, "w",encoding='utf-8')
for line in c:
f.write(line)
print("正在爬取第{}章".format(i))
f.close()
file()
运行的结果是一点毛病都没有,这是最基本的python操作
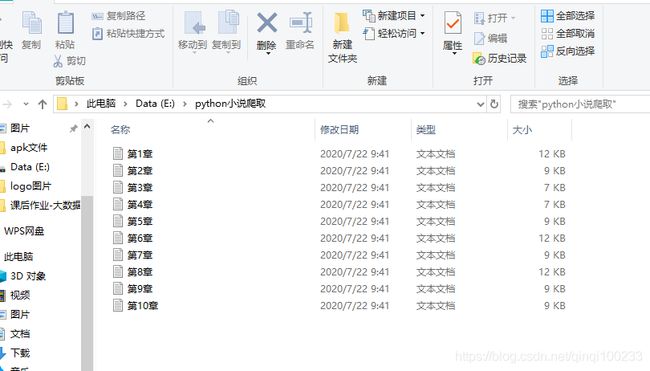
这里要注意你放的盘里面都必须有这个文件夹