Pandas——⑦合并数据(merge)
Pandas——合并数据(merge)
python入门常用操作:https://blog.csdn.net/qq_33302004/article/details/112859327
目录
一、merge基本用法以及on属性
二、how属性以及使用多列作为连接
三、indicator
四、按照index完成merge
五、suffixes
一、merge基本用法以及on属性
on='列名':以某一列为标准合并(连接)
import pandas as pd
import numpy as np
# 1. on = '列名‘: 以某一列为标准合并(连接)
left = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
})
right = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
})
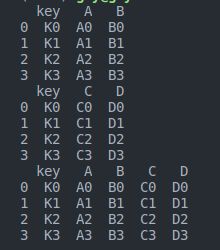
print(left)
print(right)
res1 = pd.merge(left,right, on='key')
print(res1)
print('\n')输出:
二、how属性以及使用多列作为连接
默认的合并方法是 how='inner'
how有4种取值:['left', 'right', 'inner', 'outer']
import pandas as pd
import numpy as np
# 2. 多列合并(连接)以及how的使用
left = pd.DataFrame({
'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']
})
right = pd.DataFrame({
'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']
})
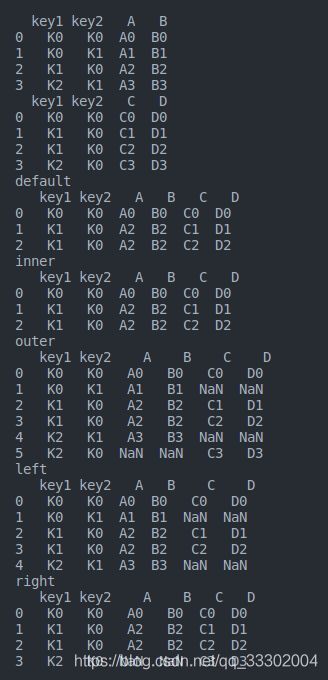
print(left)
print(right)
# 默认的合并方法是 how='inner'
res1 = pd.merge(left, right, on=['key1', 'key2'])
print('default\n', res1)
# 默认的合并方法是 how='inner'
res2 = pd.merge(left, right, on=['key1', 'key2'], how='inner')
print('inner\n', res2)
# how有4种取值:['left', 'right', 'inner', 'outer']
res3 = pd.merge(left, right, on=['key1', 'key2'], how='outer')
print('outer\n', res3)
res4 = pd.merge(left, right, on=['key1', 'key2'], how='left')
print('left\n', res4)
res5 = pd.merge(left, right, on=['key1', 'key2'], how='right')
print('right\n', res5)
print('\n')输出:
三、indicator
给出提示信息,展示该行来自哪里
使用 indicator = '列名',修改indicator列的列名
import pandas as pd
import numpy as np
# 3.indicator
df1 = pd.DataFrame({
'col1':[0,1],
'col_left':['a', 'b']
})
df2 = pd.DataFrame({
'col1':[1,2,2],
'col_right':[2,2,2]
})
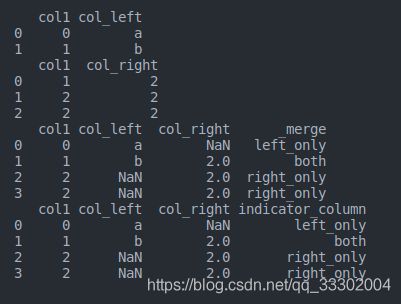
print(df1)
print(df2)
# 给出提示信息,展示该行来自哪里
res1 = pd.merge(df1,df2, on='col1', how='outer', indicator=True)
print(res1)
# 修改indicator列的列名
res2 = pd.merge(df1,df2, on='col1', how='outer', indicator='indicator_column')
print(res2)
print('\n')输出:
四、按照index完成merge
# 4.index
left = pd.DataFrame(
{
'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']
},
index = ['k0', 'k1', 'k2']
)
right = pd.DataFrame(
{
'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']
},
index = ['k0', 'k2', 'k3']
)
print(left)
print(right)
res1 = pd.merge(left, right, left_index = True, right_index=True, how='outer')
print(res1)
res2 = pd.merge(left, right, left_index = True, right_index=True, how='inner')
print(res2)
print('\n')输出:

五、suffixes
处理名字相同但是内涵不同的数据,为数据列重新命名
为非连接列重新命名
import pandas as pd
import numpy as np
# 5.suffixes
# 处理名字相同但是内涵不同的数据,为数据列重新命名
boys = pd.DataFrame({
'k': ['k0', 'k1', 'k2'],
'age': [1,2,3]
})
girls = pd.DataFrame({
'k': ['k0', 'k0', 'k3'],
'age': [4,5,6]
})
print(boys)
print(girls)
# 为非连接列重新命名
res1 =pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
print(res1)
res2 =pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='outer')
print(res2)输出:
