[论文笔记] 人脸检测方向系列论文
目录
1. MTCNN
2. FaceBoxes
3. PyramidBox
4. SRN
5. DSFD
6. RetinaFace
7. AInnoFace
1. MTCNN
论文链接:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks,发表时间:2016.04
MTCNN 这篇论文总页数不过 5 页,不过一直到现在为止都算比较热门,可见其当时的影响力。MTCNN 的标题已经点明了这篇论文的两个亮点:通过 Multi-task 的方式,同时学习 Face Detection 和 Face Alignment 以及采用级联的卷积神经网络作为所使用模型。
![[论文笔记] 人脸检测方向系列论文_第1张图片](http://img.e-com-net.com/image/info8/ee902716af344bf2b38f13aa6bcaa254.jpg)
在 MTCNN 中,作者提出了一种级联的框架(如上图所示),共分为三个阶段,其对应的结构分别为:P-Net(Proposal Network),R-Net(Refinement Network),O-Net(Output Network)。可以看的出来,P-Net 用于提出大量的 Face Proposal,R-Net 基于这些 Proposal 进行 Refinement,最后,由 O-Net 再次进行人脸检测,总体来说是一个 coarse-to-fine 的过程。
![[论文笔记] 人脸检测方向系列论文_第2张图片](http://img.e-com-net.com/image/info8/1f1b5e48fe97461f89b3ddc081fb590d.jpg)
Inference Pipeline:
-
Pre-Processing
先对输入图像多次缩放到不同大小(最小尺寸仍大于 P-Net 的输入尺寸),以此得到图像金字塔(Image Pyramid)。可以根据所使用数据集人脸尺寸分布确定缩放因子(Resize Factor),一般设在 0.7-0.8 比较合适(缩放因子大,易延长推理时间;缩放因子小,易漏掉小尺寸人脸)。
-
Stage 1 (P-Net)
由于每张图像经过多次缩放,所得到的图像金字塔较大,故输入经过 P-Net 后,可以得到大量的 Feature Map(注意,P-Net 为全卷积层,输出大小由输入尺寸所决定)。 P-Net 所输出的 Feature Map 的尺寸为 H x W x 16,将任意一点映射回原图像上,从其对应点开始,向右下方截取 12 x 12 大小的区域,再根据 Feature Map 对应位置上的 Bounding Box Regression 进行坐标调整,即可得到该 Feature Map 对应位置的 Bounding Box 预测结果。(可以想象成对原图做 Sliding-Window,尺寸为 12 x 12,每个窗口都进行预测)
对于这些候选区域,先根据 Face Classification 得分进行筛选,再通过非极大值抑制(Non-Maximuim Suppression, NMS)进行筛选,最终得到筛选后的人脸候选区域。
![[论文笔记] 人脸检测方向系列论文_第3张图片](http://img.e-com-net.com/image/info8/3ee5db8fc1ac4b019bb320f9e71b1f42.jpg)
-
Stage 2 (R-Net)
由 P-Net 输出的人脸候选区域,根据其 Bounding Box 坐标,在原图上进行截取(需要截取 Bounding Box 最大边长的正方形,以此保障缩放时不产生形变并保留更多的人脸框周围细节),并缩放至 24 x 24,以此作为 R-Net 的输入。R-Net 与 P-Net 一样,对于所输出候选区域,也是先根据 Face Classification 得分进行筛选,再利用 Bounding Box Regression 通过非极大值抑制进行筛选,最终得到筛选后的人脸候选区域。
-
Stage 3 (O-Net)
同样的,由 R-Net 输出的人脸候选区域,根据其 bounding box 坐标,在原图上进行截取,并缩放至 48 x 48,以此作为 R-Net 的输入。O-Net 与 R-Net 一样,对于所输出候选区域,还是先根据 Face Classification 得分进行筛选,再利用 Bounding Box Regression 通过非极大值抑制进行筛选,最终得到筛选后的人脸候选区域。
训练细节:
-
数据标注划分标准
Positive Face:与 ground-truth 比较, IOU > 0.65 的图像
Part Face:与 ground-truth 比较,0.65 > IOU > 0.4 的图像
Negative Face:与 ground-truth 比较,IOU < 0.3的图像
Landmark Face:带有 Landmark 标注信息的图像 -
训练过程中,P-Net/R-Net/O-Net 三个网络单独训练。作者从 WIDER Face 上随机进行裁剪,以此收集 Positive/Negative/Part Faces,并在 CelebA 上进行人脸裁剪,以此收集 Landmark Faces,将其作为 P-Net 的输入,以此训练 P-Net。待 P-Net 训练完毕后,将之前收集到的人脸数据输入到 P-Net 中,得到大量候选区域,在原图上进行截取,按照数据标注划分标准对其进行划分,以此得到 R-Net 的训练数据。同样的,R-Net 训练完毕后,将之前收集到的人脸数据输入到 P-Net/R-Net 中,得到大量候选区域,在原图上进行截取,按照数据标注划分标准对其进行划分
-
作者在训练过程中采用了 Online Hard sample mining(与 OHEM 相似),对 mini-batch 中每个样本的 loss 进行排序,选取前 70% 作为困难样本,仅反向传递由困难样本得到的梯度。
-
在 P-Net/R-Net 训练过程中,人脸检测 Loss:人脸边框回归 Loss:人脸关键点回归 Loss = 1 : 0.5 : 0.5;在 O-Net 训练过程中,人脸检测 Loss:人脸边框回归 Loss:人脸关键点回归 Loss = 1 : 0.5 : 1。
PS : MTCNN 的官方代码:kpzhang93/MTCNN_face_detection_alignment。此外,在 Github 上有许多关于 MTCNN 不错的复现,这里推荐两个我使用过的:ipazc/mtcnn(基于 Tensorflow 实现的),kuaikuaikim/DFace(基于 PyTorch 实现的)。
2. FaceBoxes
论文链接:FaceBoxes: A CPU Real-time Face Detector with High Accuracy, 发表时间:2017.08
这篇论文在保持较高准确率的前提下,大幅提高在 CPU 上的运行速度(‘As a consequence, the proposed detector
runs at 20 FPS on a single CPU core and 125 FPS using a GPU for VGA-resolution images’),以此达到实时人脸检测。
![[论文笔记] 人脸检测方向系列论文_第4张图片](http://img.e-com-net.com/image/info8/1826ea87f1804eb4a511fc02ace4f3af.jpg)
该论文的创新点包括:Rapidly Digested Convolutional Layers (RDCL),Multiple Scale Convolutional Layers (MSCL),Anchor Densification Strategy。
![[论文笔记] 人脸检测方向系列论文_第5张图片](http://img.e-com-net.com/image/info8/e5311c1c86214aac93cfa3f4b895f867.jpg)
关于 Rapidly Digested Convolutional Layers(RDCL):
在这篇论文中,作者为了加快模型运行速度,通过设计合适的 Kernel Size 和 Stride Size,快速地将输入进行压缩,并利用 C.ReLU 减少输入的 Channel 数量。依据上图所示,整个 RDCL 的 Stride Size 为 32,即输入经过 RDCL 后将压缩至原来的 1/32。此外,作者还利用了激活函数 C.ReLU 进行加速。激活函数 C.ReLU 出自 Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units,其公式为 C R e L U ( x ) = [ R e L U ( x ) , R e L U ( − x ) ] CReLU(x)=[ReLU(x),ReLU(−x)] CReLU(x)=[ReLU(x),ReLU(−x)]。
![[论文笔记] 人脸检测方向系列论文_第6张图片](http://img.e-com-net.com/image/info8/2e638856b71a46da92dbc75082435edb.jpg)
关于 Multiple Scale Convolutional Layers(MSCL):
作者认为之所以 RPN 用作人脸检测器效果不好,其原因有两个:RPN 中的 Anchor 只和其最后的卷积层相关,其输出的特征和分辨率在处理人脸变化上太弱;RPN 虽然使用不同的尺度的 Anchor 来检测人脸,但只有单一的感受野,不能匹配不同尺度的人脸。故,作者采取在不同尺度上的 feature map 进行人脸检测,并使用 Inception Module 丰富感受野的信息,以此捕捉多尺度信息。
PS: 在这里谈下 Object Detection 中的 Single/Multi Shot 和 Single/Multi Scale。在目标检测中,Single Shot 指的是输入仅为一张图像,而 Multi Shot 指的是输入包含不同尺寸的同一图像,即下图中所示的 Image Pyramid;Single Scale 指的是仅在单一 Feature Map 上进行预测,而 Multi Scale 指的是在多个 Feature Map 上进行预测,即下图中所示的 Prediction Pyramid。(个人理解,望指正)
![[论文笔记] 人脸检测方向系列论文_第7张图片](http://img.e-com-net.com/image/info8/d153675247094d4f92f127f86c4b2e8d.jpg)
关于 Anchor densification strategy:
由 Figure 1 可知,FaceBoxes 在 Inception3/Conv3_2/Conv4_2 上进行人脸检测,其 Anchor 大小分别为 32/64/128 (for Inception3),256 (for Conv3_2),512 (for Conv4_2),对应的 Tiling Interval 分别为 32/32/32/64/128。按照作者所提出的 Tiling Density 公式( A d e n s i t y = A s c a l e / A i n t e r v a l A_{density} = A_{scale}/A_{interval} Adensity=Ascale/Ainterval),这些 Anchor 的密度指数分别为 1/2/4/4/4。
作者认为,相较于大尺度 Anchor,小尺度 Anchor 显得更加稀疏。为解决这一不平衡问题,作者便设计了 Anchor Densification Strategy,将尺寸为 32 的 Anchor 密度增加 4 倍,尺寸为 62 的 Anchor 密度增加 2 倍。(具体做法如下图所示)
![[论文笔记] 人脸检测方向系列论文_第8张图片](http://img.e-com-net.com/image/info8/590a455620fe4e0ca560b8dad33a2b0f.jpg)
训练细节:
-
Matching strategy
作者在模型训练过程中,认为与某个人脸的 Bounding Box 有着最高的 IOU 的 Anchor 是匹配的,以及与任意人脸的 bounding box 的 IOU 超过 0.35 的 Anchor 也是匹配的。
-
Loss function
作者采用 2-class softmax loss (for classification) + smooth L1 loss (for regression) 作为 Loss Function。
-
Hard negative mining
在 Object Detection 中,Negative Anchor 数量往往会远大于 Positive Anchor 的数量,由此导致 Negative Anchor 在梯度回传中占主导地位,并最终影响模型的训练与收敛。故,作者在计算各个 Anchor 的 Loss 后,会对其进行排序,按照其排序次序进行挑选,保证负样本和正样本的比例最高不超过 3:1。
PS : Faceboxes 的官方代码:sfzhang15/FaceBoxes(基于 Caffe 实现的),Github 上也有基于 PyTorch 实现的项目:zisianw/FaceBoxes.PyTorch。
3. PyramidBox
论文链接:PyramidBox: A Context-assisted Single Shot Face Detector, 发表时间:2018.03
PyramidBox 由百度所提出,在该篇论文中,作者提出 Pyramid Anchor/Low-level Feature Pyramid NetWork(LFRN)/Context-Sensitive Prict Module(CPM),以此解决非受控环境中人脸尺寸小、模糊、遮挡等问题,并曾在 WIDER Face/FDDB 取得了 SOTA:FDDB(Discontinues:0.987, Continues:0.860),WIDER FACE(Val-Easy:0.961, Val-Medium:0.950, Val-Hard:0.889,Test-Easy:0.956, Test-Medium:0.946, Test-Hard:0.887)。
PS: 在 2019 年 4 月,中科院和百度在 PyramidBox 的基础上进行改进,共同提出了:PyramidBox++: High Performance Detector for Finding Tiny Face。
![[论文笔记] 人脸检测方向系列论文_第9张图片](http://img.e-com-net.com/image/info8/871c4ac5cf994667805cfaee528139d5.jpg)
关于 Pyramid Anchor:
在这篇论文中,作者认为上下文信息(contextual information)对人脸检测很重要,尤其是对于小尺寸、模糊、存在遮挡的人脸。于是,作者就提出了上下文相关的 Pyramid Anchor,即不仅仅对人脸进行 Anchor 设置,还对肩膀、身体设置相应的 Anchor。(不过作者为保证竞赛的公平,提出使用半监督的方式进行 Anchor 标签的生成,生成的方式需要仔细阅读才好理解)
对于第 i i i 层中的第 j j j 个 Anchor 来说,它的标签由以下公式所决定:
![[论文笔记] 人脸检测方向系列论文_第10张图片](http://img.e-com-net.com/image/info8/0dda52bf4860487b99f89375d5c3ec00.jpg)
此外,作者在实验中的设置为:

对此,我的理解是这样的:网络中生成 Feature Map 进行预测的层会设置大量 Anchor,为了对各个 Anchor 生成 Head/Face/Body Label,需要先计算该 Anchor 映射回原图的区域大小,并进行相应的 Down-Sampling(按照作者的设置,若下采样系数为 1 的映射区域 IOU 大于阈值,则该 Anchor 具有 Face Label;若下采样系数为 S p a 1 S_{pa}^{1} Spa1 的映射区域 IOU 大于阈值,则该 Anchor 具有 Head Label;若下采样系数为 S p a 2 S_{pa}^{2} Spa2 的映射区域 IOU 大于阈值,则该 A 具有 Body Label)。
![[论文笔记] 人脸检测方向系列论文_第11张图片](http://img.e-com-net.com/image/info8/1d1dad9ccee94c24999ac10a5687c968.jpg)
关于 Low-level Feature Pyramid NetWork(LFRN):
在目标检测中,为了提高小尺寸物体检测率,往往会采取高层语义信息特征结合低层的高分辨率进行预测。其中,Feature Pyramid Networks for Object Detection就提出了自顶向下(Top-Down)框架。于是,在这篇论文中,作者依照这个思路设计了 LFRN,用于融合高层语义信息和低层高分辨率。
不过,作者也指出并非所有高层语义信息对与小尺寸人脸检测都是有用的,原因如下:小尺寸人脸与大尺寸人脸的纹理特征往往不同,且高层语义特征往往会含有大量噪声(由于网络步长、网络层数、输入尺寸所导致)。所以,作者一改从最后一层向下融合的习惯,改为从中间开始向下融合,以此避免高层语义信息对低层特征带来的扰动。
![[论文笔记] 人脸检测方向系列论文_第12张图片](http://img.e-com-net.com/image/info8/0efb308e243541469d5df522b16076f9.jpg)
关于 Context-Sensitive Prict Module(CPM):
为了更好的利用上下文信息,作者在 Inception-ResNet 的启发下设计了 CPM,与其他模块相比,该模块显得更深、更宽。并且,作者借鉴 S 3 F D S^3FD S3FD 中的 Max-out(即对背景标签选取得分最高者,以减少负样本的误检率),提出 Max-in-out(即对正负样本都选取得分最高者)。
![[论文笔记] 人脸检测方向系列论文_第13张图片](http://img.e-com-net.com/image/info8/a341ea8c3b584aceacf3a0de295a955a.jpg)
第 l l l 层 CPM 的输出大小为 w l ∗ h l ∗ c l w_l*h_l*c_l wl∗hl∗cl,其中, w l = h l = 640 / l w_l=h_l=640/l wl=hl=640/l, c l = 20 c_l=20 cl=20。而 CPM 输出中的每个 Channel 用于对 Face/Head/Body 进行分类与回归:人脸识别用 4 个 Channel,头部和人体识别各用 2 个 Channel,人脸/头部/人体检测各用 4 个 Channel 进行回归。其中,人脸识别的 4 个 Channel 设为 4 = c p l + c n l 4=cp_l + cn_l 4=cpl+cnl, c p l cp_l cpl 用于判别区域是否为前景, c n l cn_l cnl 用于判别区域是否为背景。(作者认为在网络底层,大量 Anchor 所对应的区域都是背景,故设置: 当 l = 1 时 , c p l = 1 ; 当 l ≠ 1 时 , c p l = 1 当 l=1 时, cp_l = 1; 当 l \neq 1时, cp_l = 1 当l=1时,cpl=1;当l=1时,cpl=1)
![[论文笔记] 人脸检测方向系列论文_第14张图片](http://img.e-com-net.com/image/info8/e4db6e0d88904c7a8ab5c502f368f49d.jpg)
训练细节:
-
Train Dataset
论文中,作者利用 WIDER FACE 的 12880 张图像进行训练,并使用 Color Distort/Random Crop/Horizontal Flip 进行数据增强。
-
Data-anchor-sampling
为了解决样本不均衡以及更好的识别小尺寸人脸,作者提出 Data-anchor-sampling 用于改变训练集的数据分布,原文的解释为:“In short, data-anchor-sampling resizes train images by reshaping a random face in this image to a random smaller anchor size.”。此外,作者认为这一处理可以使得小尺寸人脸数据的比例比大尺寸人脸更大,并增加了小尺寸人脸的多样性,从而使得模型能更好的检测小尺寸人脸。
具体步骤为:设置各预测层的 Anchor 大小为 s i = 2 4 + i , f o r i = 0 , 1 , . . , 5 s_i=2^{4+i}, for\ i=0,1,..,5 si=24+i,for i=0,1,..,5。令 i a n c h o r = a g r m i n i a b s ( s a n c h o r i − s f a c e ) i_{anchor}=agrmin_iabs(s_{anchor_i-s_{face}}) ianchor=agrminiabs(sanchori−sface),即与所选择人脸大小最相近的 Anchor 下标。接着,从 { 0 , 1 , . . . , m i n ( 5 , i a n c h o r + 1 ) } \{0,1,...,min(5,i_{anchor}+1)\} { 0,1,...,min(5,ianchor+1)} 中随机选择,作为 i t a r g e t i_{target} itarget。最终,将所选择人脸进行缩放: s t a r g e t = r a n d o m ( s i t a r g e t / 2 , s i t a r g e t ∗ 2 ) s_{target}=random(s_{i_{target}}/2,s_{i_{target}}*2) starget=random(sitarget/2,sitarget∗2)。同时,原图做同样比例的缩放: s ∗ = s t a r g e t / s f a c e s*=s_{target}/s_{face} s∗=starget/sface。
-
PyramidBox Loss
关于这点,原文比较繁杂,故直接放原文。
![[论文笔记] 人脸检测方向系列论文_第15张图片](http://img.e-com-net.com/image/info8/c9cb3399464d4c8ab26cfde2aba4f04a.jpg)
![[论文笔记] 人脸检测方向系列论文_第16张图片](http://img.e-com-net.com/image/info8/c934527d53c0444797418a66914a06d2.jpg)
![[论文笔记] 人脸检测方向系列论文_第17张图片](http://img.e-com-net.com/image/info8/0c73959481f543968a15cfe632d9a92d.jpg)
PS : Github 复现项目:EricZgw/PyramidBox(基于 TensorFlow 实现的),Goingqs/PyramidBox(基于 PyTorch 实现的)。
4. SRN
论文链接:Selective Refinement Network for High Performance Face Detection, 发表时间:2018.09
SRN 由中科院电子研究所和自动化所提出,曾在 WIDER Face 取得了 SOTA:WIDER FACE(Val-Easy:0.964, Val-Medium:0.953, Val-Hard:0.902,Test-Easy:0.959, Test-Medium:0.949, Test-Hard:0.897)。
在本篇论文中,作者认为目前的人脸检测还有两个问题需要解决:解决高 Recall 时所出现的大量 fasle positive (该现象在小尺寸人脸检测问题上更显著)以及提高人脸检测框的精度。于是,作者便以此为出发点,设计了 **Selective Two-Step Classification(STC)**和 Selective Two-Step Regression(STR),分别用于筛选 false positive 和提高人脸检测精度,并仿照 Inception Module 设计 Receptive Field Enhancement(RFE),以此增加所生成特征的感受野的多样性,从而提高在不同宽高比的人脸上的检测精度。
PS: 在 2019 年 1 月,本篇论文的共同一作 Shifeng Zhang 以一作身份发了篇改进论文:Improved Selective Refinement Network for Face Detection,作者团队为中科院自动化所和京东 AI 研究院。
![[论文笔记] 人脸检测方向系列论文_第18张图片](http://img.e-com-net.com/image/info8/dea58512bf1a4778ab2caa350bc39f1b.jpg)
关于网络结构:
本篇论文采用 ResNet-50 作为 Backbone,由四个 Residual Block 生成的 Feature Map 记为 C2/C3/C4。其中,C6 和 C7 由 C5 通过两层 3 x 3 卷积层进行下采样所生成。此外,上图中 P2/P3/P4/P5 由 C2/C3/C4 通过 Lateral Connction 生成,尺寸与其保持一致,而 P6/P7 由 P5 通过两层 3 x 3 卷积层进行下采样所生成。在上图中,STC 仅在 C2/C3/C4/P2/P3/P4 上使用,STR 仅在 C5/C6/C7/P5/P6/P7 上使用,且任意 Feature Map 都要经过 RFE,再进行预测。
由于本篇论文的方法是 anchor-based 的,就意味着每个 Feature Map 都要进行 Anchor 的设置。在论文中,作者对每个金字塔层都设定了两种 Anchor 尺寸: 2 S 2S 2S 和 2 2 S 2\sqrt{2}S 22S(其中, S S S 表示该金字塔层的总步长),以及一个特定的 aspect ratio(宽高比):1.25。
PS: 关于作者所绘制的网络结构图,可以看出网络的前向计算可分为两部分:1-st step,即图中上半部分所示,分别生成C2/C3/C4/C5/C6/C7,各个 Feature Map 输入到 RFE 中,分别在进行人脸检测;2-nd step,即图中下半部分所示,分别生成P2/P3/P4/P5/P6/P7,各个 Feature Map 输入到 RFE 中,分别在进行人脸检测。
关于 Selective Two-Step Classification(STC):
为了解决人脸检测中负样本过多的问题,作者设计了 STC,通过 1st-step 中的分类对易分负样本进行过滤,以此减少 2nd-step 中的分类的搜索空间。此外,作者认为没必要在所有金字塔层上都进行 Two-Step 分类操作,因为高层 Feature Map 上 Anchor 的占比小,且正负样本数量不均衡的问题相较于底层更轻。故,作者仅在 P2/P3/P4 上进行 Two-Step 分类操作。
作者对其做了相应的实验,实验结果如下所示:
![[论文笔记] 人脸检测方向系列论文_第19张图片](http://img.e-com-net.com/image/info8/0067ad89b1fd47ad8119f09429b236ba.jpg)
具体流程为:在 1st-step 中,C2/C3/C4 对 Anchor 做了分类和回归预测;在 2nd-step 中,P2/P3/P4 分别对 C2/C3/C4 所预测的 Anchor 进行筛选(即去除置信度低的 Anchor),并对所保留的 Anchor 再次进行分类预测。
此外,对于人脸预测中的分类任务,作者采用 Focal Loss 作为分类任务的损失函数,具体细节如下图所示:
![[论文笔记] 人脸检测方向系列论文_第20张图片](http://img.e-com-net.com/image/info8/8b59b31a33c2455e93bdeb4802bb1555.jpg)
关于 Selective Two-Step Regression(STR):
在目标检测中,One-Stage 算法一般仅对 Bounding Box 做一次回归预测,作者认为这是不够的,无法提高人脸检测问题中的预测框的精度,于是作者便设计了 STR。但是,在 Cascade R-CNN 中,作者指出盲目的进行多次 Bounding Box 回归预测,对最终的预测精度并无帮助。于是,作者对其做了相应的实验,实验结果如下所示:
![[论文笔记] 人脸检测方向系列论文_第21张图片](http://img.e-com-net.com/image/info8/08a54441d6e34bd5928cd3ff4df78466.jpg)
作者也对实验结果做了分析,给出了两个可能的原因:底层的 Feature Map 主要是通过密集采样的 Anchor 检测小尺寸人脸,且底层的 Feature Map 的特征表达能力并不强,再次进行 Bounding Box 回归,其精度可能会下降;令底层的 Feature Map 进行 Two-Step 回归操作,会使得 Reg Loss 增大,导致模型忽略了分类的精度,最终影响到整个模型的预测精度。故,作者仅在 P5/P6/P7 上进行 Two-Step 回归操作。
具体流程为:在 1st-step 中,C5/C6/C7 对 Anchor 做了分类和回归预测;在 2nd-step 中,P5/P6/P7 分别对 C5/C6/C7 所预测的 Bounding Box 进行边框调整,即再次进行回归预测。
此外,对于人脸预测中的回归任务,作者采用 Smooth-L1 Loss 作为回归任务的损失函数,具体细节如下图所示。
![[论文笔记] 人脸检测方向系列论文_第22张图片](http://img.e-com-net.com/image/info8/9cd0117189544a689c78c75f1e99b175.jpg)
关于 Receptive Field Enhancement(RFE):
作者对 WIDER Face 统计中发现,有部分人脸的宽高比高于 2 或者低于 0.5。由于常见人脸检测算法中都采用正方形的卷积核尺度,这将导致模型的感受野与这些人脸的宽高比存在不匹配现象。为解决这个问题,作者依据 Inception Module,提出了 RFE(结构如下图所示)。
其中,先用 1 x 1 的卷积核将 Feature Map 的通道数至原通道数1 / 4,再分别经过 1 x k/k x 1 的卷积核(k = 3,5),提供矩形框的感受野,再通过 1 x 1 的卷积核,最后所有分支进行 Element-wise Sum。
![[论文笔记] 人脸检测方向系列论文_第23张图片](http://img.e-com-net.com/image/info8/d4ec12a2a32349e1a311e0eb01b4e8e7.jpg)
训练细节:
-
Data Augmentation
- Photometric Distortions
- 对原图随机扩充 [1, 2] 倍,并进行 zero-padding 操作。
- 从原图裁剪两个正方形区域,并从中随机选择一个区域参与训练,裁剪方式为:以原图的短边长为目标长度进行裁剪;以原图的短边长乘以 [0.5, 1.0] 内的随机因子作为目标长度进行裁剪。
- 对裁剪所得区域进行随机水平翻转,并缩放至1024 x 1024。
-
Anchor Matching
在 1st-step 中,正样本为 IoU > 0.7,负样本为 IoU < 0.3,其他 Anchor 忽略。
在 2nd-step 中,正样本为 IoU > 0.5,负样本为 IoU < 0.4,其他 Anchor 忽略。
PS : 作者所开源代码 ChiCheng123/SRN(基于 PyTorch 实现的)。
5. DSFD
论文链接:DSFD: Dual Shot Face Detector, 发表时间:2018.10
DSFD 由南京理工大学与腾讯优图联合提出,整体为 One-Stage 算法,对每个金字塔层进行 Dual-Shot。此外,作者为提高 Second-Shot 的检测精度,设计了 Feature Enhance Module(FEM);为更好的利用不同 Feature Map 的进阶学习能力,作者设计了 Progressive Anchor Loss(PAL);此外,作者还对常见的 Anchor Matching 进行了改进,提出了 Improved Anchor Matching(IAM)。
DSFD 在大量小尺寸人脸场景表现不错(不过据说运行很慢),且曾在 WIDER Face/FDDB 取得了 SOTA:FDDB(Discontinues:0.991, Continues:0.862),WIDER FACE(Val-Easy:0.966, Val-Medium:0.957, Val-Hard:0.904,Test-Easy:0.960, Test-Medium:0.953, Test-Hard:0.900)。
![[论文笔记] 人脸检测方向系列论文_第24张图片](http://img.e-com-net.com/image/info8/f632abe580484bbbb925b1ef5dcd8207.jpg)
关于网络结构:
在论文中,作者使用 VGG16 作为 Backbone(作者也有用 ResNet 作为 Backbone),并以 conv3_3/conv4_3/conv5_3/conv_fc7/conv6_2/conv7_2 的输出作为 Original Feature Map,分别记为 of_1/of_2/of_3/of_4/of_5/of_6,并以此构建 First Shot Detection Layer;接着,作者将所有 Original Feature Map 输入到 FEM 中,得到 Enhanced Feature Map,分别记为 ef_1/ef_2/ef_3/ef_4/ef_5/ef_6,并以此构建 Second Shot Detection Layer。
在 DSFD 中,作者认为在使用 FEM 和新的 Anchor 设计策略后,无需设计三种尺度的 Stride/Anchor/Receptive Field 去满足等比例间隔原则。作者在不同金字塔层的设置如下所示:(论文中,作者令 First Shot 中的 Anchor 大小为 Second Shot 中的一半,但是并没有对比实验分析)
![[论文笔记] 人脸检测方向系列论文_第25张图片](http://img.e-com-net.com/image/info8/62df8545fe944ed1983bbc987473be1b.jpg)
在 Inference 时,First Shot Detection Layer 的预测结果将被忽略,并仅在 Second Shot Detection Layer 中取前五千个预测结果,再对其进行 NMS 操作(筛选的 IOU 阈值为0.3),最终生成 750 个预测结果。
关于 Feature Enhance Module(FEM):
作者为了增强各金字塔层所生成的 Feature 的语义信息以及更好的探究相连两层的相关信息,便设计了 FEM,具体结构如下所示:
![[论文笔记] 人脸检测方向系列论文_第26张图片](http://img.e-com-net.com/image/info8/0430f9f889e649aab5a5c3b4640d2182.jpg)
关于 Progressive Anchor Loss(PAL):
在 Object Detection 中,常见的 Reg Loss 为 Focal Loss/Hierarchical Loss 等等。而作者认为这些 Loss 并没有考虑到各个层次的 Feature Map 的 progressive learning ability,于是,作者便针对这点设计了 PAL,具体细节如下所示:
First Shot multi-task Loss 如下所示:
![[论文笔记] 人脸检测方向系列论文_第27张图片](http://img.e-com-net.com/image/info8/3e9fb147f5f14027a3c3d0dcb213ed98.jpg)
Second Shot multi-task Loss 如下所示:
![[论文笔记] 人脸检测方向系列论文_第28张图片](http://img.e-com-net.com/image/info8/2c1d66a7112d49f4ac4d377a308528a0.jpg)
![[论文笔记] 人脸检测方向系列论文_第29张图片](http://img.e-com-net.com/image/info8/b7c859d0d9ee4a8c9b85211a8bbe7982.jpg)
Progressive Anchor Loss 如下所示:

关于 Improved Anchor Matching(IAM):
作者认为常见的 Anchor Match Method 都忽略了数据增强中的 Random Sampling,这将导致正负样本的不均衡问题更加严重。于是,作者便对常见的 Anchor Match Method 做出改进,提出了 IAM,以此解决离散的 Anchor Scale 和连续的 Face Scale 之间的矛盾。
该论文中,作者设置了以 3/5 的概率,使用 SSD 中的数据增强策略;以 2/5 的概率,使用 PyramidBox 中所用的 Data-Anchor-Sampling。(实验中,作者设置的 IOU 为 0.4)
PS : 官方开源代码 TencentYoutuResearch/FaceDetection-DSFD(基于 PyTorch 实现的)。
6. RetinaFace
论文链接:RetinaFace: Single-stage Dense Face Localisation in the Wild, 发表时间:2019.05
RetinaFace 由 InsightFace 和帝国理工大学联合提出(InsightFace 为目前针对 2D 与 3D 人脸分析(含检测、识别、对齐、属性识别等)最知名和开发者最活跃的开源库),是目前开源的人脸检测算法中效果最好的算法(仅比 AlnnoFace 低一点点)。
在论文中作者除了进行人脸检测外,还引进了人脸关键点检测(作者特意对 WIDER FACE 进行人脸关键点标注)和自监督网格解码器,进行多任务学习。RetinaFace 在 WIDER Face 曾取得 SOTA:WIDER FACE(Val-Easy:0.969, Val-Medium:0.961, Val-Hard:0.918,Test-Easy:0.963, Test-Medium:0.956, Test-Hard:0.914)。
![[论文笔记] 人脸检测方向系列论文_第30张图片](http://img.e-com-net.com/image/info8/e1fab0c241794e85ac343c46001fdc20.jpg)
关于网络结构:
在论文中,作者采用 FPN 中的 Feature Pyramid 结构,并以 ResNet-152 作为 Backbone,其中, C2/C3/C4/C5 为 ResNet 中各个 Residual Block 所生成的 Feature Map,而 C6 由 C5 经过 3*3 的卷积层生成(步长为 2)。
![[论文笔记] 人脸检测方向系列论文_第31张图片](http://img.e-com-net.com/image/info8/df3e662aa0eb45cc9b3b04c9bc7e0ad5.jpg)
此外,类似于 PyramidBox,作者也设计了 Context Module 用于增加模型的感受区域以及上下文信息,不过与 PyramidBox 不同,论文中每层特征金字塔层都接一个独立的 Context Module。作者还仿照 WIDER Face Challenge 2018 的冠军,将所有带有 Lateral Connection 的 3*3 卷积层和 Context Module 中的所有卷积层替换为可变形卷积网络(DDeformCable Convolution Network,DCN)。
关于 Dense Regression Branch:
作者在这一分支中,将原图中的人脸由 2D 映射到 3D 模型上,再由 3D 模型解码到 2D上,最后计算解码得到的图像与原图的像素距离,以此作为损失值。 其中,该分支用到了 Mesh Decoder,该网格解码器是基于图卷积网络的。(这块了解的不多,可查阅 Generating 3d faces using convolutional mesh autoencoders 和 Dense 3D Face Decoding over 2500FPS: Joint Texture & Shape Convolutional Mesh Decoders)
![[论文笔记] 人脸检测方向系列论文_第32张图片](http://img.e-com-net.com/image/info8/c55a54bd53e94147aaa614f7894903e6.jpg)
该分支所用 Loss 为 Dense Regression Loss,具体细节如下所示:
![[论文笔记] 人脸检测方向系列论文_第33张图片](http://img.e-com-net.com/image/info8/a58b8df76e8d4654ae5180cee709babf.jpg)
关于 Multi-task Loss:
论文中,作者设计的 Multi-task Loss 为:
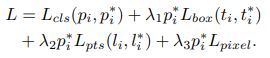
L c l s L_{cls} Lcls 为 Face Classification Loss, L b o x L_{box} Lbox 为 Face Box Regression Loss, L p t s L_{pts} Lpts 为 Facial Landmark Regression Loss, L p i x e l L_{pixel} Lpixel 为 Dense Regression Loss。其中,Dense Regression Loss 细节如下所示:
![[论文笔记] 人脸检测方向系列论文_第34张图片](http://img.e-com-net.com/image/info8/e46b0716b12943c68d0ab43784d7a1c1.jpg)
其他细节:
-
Anchor Setting
作者对特征金字塔的各个层都设置了不同的 Anchor Scale 以及 Stride,细节如下所示:
![[论文笔记] 人脸检测方向系列论文_第35张图片](http://img.e-com-net.com/image/info8/1cf156b9fa554b85876f34f36e37bec8.jpg)
训练过程中,正样本为 IoU > 0.5,负样本为 IoU < 0.3,其他 Anchor 忽略。此外,作者还采用 OHEM 以缓解正负样本间的 Imbalance 问题,即对负样本按照 Loss 值进行排序与选取,保持正负样本的比例为 1:3。
-
Data Augmentation
作者将常见的随机裁剪修改为裁剪正方形区域,其边长为原图最短边长乘以 [0.3, 1] 中的随机因子。除此以外,作者还采用随机翻转以及色彩抖动。
-
Test Details
在测试阶段,作者将图像缩放至不同大小以形成 Image Pyramid(图像最短边长的范围为 [500, 800, 1100, 1400, 1700]),将所生成图像金字塔输入模型后所得结构进行 Voting,以得到最终预测结果。
PS : 官方开源代码 deepinsight/insightface(基于 MXNet 实现的),Github 复现项目:supernotman/RetinaFace_Pytorch(基于 PyTorch 实现的)。
7. AInnoFace
论文链接:Accurate Face Detection for High Performance, 发表时间:2019.05
AlnnoFace 由创新奇智(AInnovation) 所提出,目前为 WIDER Face 榜单第一(不过尚未开源):WIDER FACE(Val-Easy:0.970, Val-Medium:0.961, Val-Hard:0.918,Test-Easy:0.965, Test-Medium:0.957, Test-Hard:0.912)。虽然 AlnnoFace 并没有提出很创新的 Idea,不过作者将很多现有的方法融到了一起,达到了最好的性能,这其中的工作量是非常大的,很多细节值得我们去了解。(不过有点遗憾的是,论文中并没有公布 Ablation Study 细节,不然就可以更好的理解各个模块的作用了)
![[论文笔记] 人脸检测方向系列论文_第36张图片](http://img.e-com-net.com/image/info8/a79d584b30574d6d959a3193da9f87b3.jpg)
在论文中,作者以 RetinaNet 作为 AlnnoFace 的网络框架,以 ResNet-152 作为 Backbone(按照 FPN 所示生成 6-level Feature Pyramid),并以 Focal Loss 作为其中 class subnet 的损失函数( F L p t = − α ∗ ( 1 − p t ) γ log ( p t ) FL_{p_t}=-\alpha * (1-p_t)^\gamma \log(p_t) FLpt=−α∗(1−pt)γlog(pt)),IOU Loss 作为其中 box subnet 的损失函数( L I O U = − ln I n t e r s e c t i o n ( B p , B g t ) U n o i n ( B p , B g t ) L_{IOU}=-\ln{\frac{Intersection(B_p,B_{gt})}{Unoin(B_p,B_{gt})}} LIOU=−lnUnoin(Bp,Bgt)Intersection(Bp,Bgt))。
作者为了解决人脸检测中存在的两个问题:low recall effciency 和 low location accuracy,便引入 SRN 中所提出的 Selective Two-step Classification(STC)和 Selective Two-step Regression(STR)。关于这两个操作的细节,可以往上翻阅,查看关于 SRN 的笔记。
在数据增强部分,作者除了使用常见的随机扩充/裁剪/翻转/颜色抖动外,还以 0.5 的概率使用 PyramidBox 中的 data-anchor-sampling,以此使得训练数据的尺寸分布多样化。为了减少小尺寸人脸检测中的 false positive,作者仿照 PyramidBox 中对前/背景进行 max-out 操作,并设置 c p = c n = 3 c_p=c_n=3 cp=cn=3。 此外,作者还采用了 Multi-scale Testing 操作,即测试时,将图像缩放多个尺寸进行测试,并通过 voting 将预测结果进行融合。
参考资料:
- 总结人脸识别的方向(FD,FA,FR,FV)
- ChanChiChoi/awesome-Face_Recognition
- 人脸识别合集 | 绪论与目录
- 人脸检测–MTCNN从头到尾的详解
- MTCNN人脸检测—PNet网络训练
- 对PyramidBox的理解
- 人脸检测:Faceboxes(IJCB2017)
- 论文阅读:FaceBoxes: A CPU Real-time Face Detector with High Accuracy
- PyramidBox 论文走读
- PyramidBox 人脸检测算法
- Selective Refinement Network
- arxiv2018_SRN
- arxiv2018_DSFD
- Face Detection DSFD 论文理解
- insightface新作:RetinaFace单阶段人脸检测
- AInnoFace:Accurate Face Detection for High Performance(论文阅读笔记)
- arxiv2019_AFD_HP
如果你看到了这篇文章的最后,并且觉得有帮助的话,麻烦你花几秒钟时间点个赞,或者受累在评论中指出我的错误。谢谢!
作者信息:
知乎:没头脑
CSDN:Code_Mart
Github:Tao Pu