python基础 - 数据类型
文章目录
- 前言
- 一、整型(int)
-
- 1.定义整型
- 2.转换为整型
- 3.其他
- 二、布尔值(bool)
-
- 1.布尔值的表示
- 2.转换为布尔值
- 3.其他
- 三、字符串
-
- 1.字符串的表示
- 2.常见方法
- 3.转换为字符串
- 4.公共的功能
- 5.字符串编码
- 四、元组
-
- 1.元组的定义
- 2.字符串、列表转换为元组:
- 3.其他(公共的功能)
- 4.嵌套
- 知识补充:range
- range和for循环
- 五、列表
-
- 1.列表的定义
- 2.常用方法
- 3.转换为列表
- 4.其他(公共的功能)
- 5.嵌套
- 6.复制列表
- 六、字典
-
- 1.字典的定义
- 2.常见方法
- 3.转换
- 4.其他(公共的功能)
- 七、集合
-
- 1.集合的定义
- 2.常见方法
- 3.转换
- 4.其他(公共的功能)
前言
- Number(数字)- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
不可变数据类型:数字,字符串,元组;
可变数据类型:列表,字典,集合;
一、整型(int)
(1) python3支持int、float、bool、complex(复数);
(2) 内置的type()函数可以用来查询变量所指的对象类型;
(3) 数值的除法包括两个运算符:"/“返回一个浮点数,”//"返回一个整数。
(4) 在混合计算时,python会把整型转换成浮点型。
1.定义整型
>>> num = 10
>>> print(type(num)) # 2.转换为整型
- 在项目开发和面试题中经常会出现一些“字符串”和布尔值转换为整型的情况。
- 如果给定一个按照二进制、八进制、十六进制规则存储的字符串时,可通过int转换为十进制的整数。
(1).布尔值转整型
>>> n1 = int(True)
>>> print(n1) # 1 True转换为整数 1
>>> n2 = int(False)
>>> print(n2) # 0 False转换为整数 0
(2).字符串转整型
>>> v1 = int("186",base=10)
>>> print(v1) # 186 把字符串看成十进制的值,然后再转换为十进制整数
>>> v2 = int("0b1001",base=2)
>>> print(v2) # 9 把字符串看成二进制的值,然后再转换为十进制整数(0b表示二进制)
>>> v3 = int("0o144",base=8)
>>> print(v3) # 100 把字符串看成八进制的值,然后转换为十进制整数(0o表示八进制)
>>> v4 = int("0x59",base=16)
>>> print(v4) # 89 把字符串看成十六进制的值,然后转换为十进制整数(0x表示十六进制)
3.其他
- python2中跟整数相关的数据类型有两种:int(整型)、long(长整型),二者都是整数,只不过能表示的值范围不同。
- int,可表示的范围:-9223372036854775808~9223372036854775807
- long,整数值超出int范围之后自动会转换为long类型(无限制)。
- python3中去除了long只剩下:int(整型),并且 int 长度不再限制。
二、布尔值(bool)
布尔值,其实就是“真”,“假”两个值的统称。
1.布尔值的表示
>>> t = True
>>> f = False
2.转换为布尔值
- 在以后的项目开发中,会经常使用其他类型转换为布尔值的情景,此处只要记住一个规律即可;
- 整数0、空字符串、空列表、空元祖、空字典转换为布尔值时均为False;其他均为True。
>>> bool(0) # False
>>> bool(-10) # True
>>> bool(10) # True
>>> bool('dd') # True
>>> bool('') # False
>>> bool(' ') # True
>>> bool([]) # False 空列表
>>> bool([11,22,33]) # True 非空列表
>>> bool({
}) # False 空字典
>>> bool({
1:'11',2:'22'}) # True 非空字典
3.其他
- 如果在if、while条件后面写一个值当作条件时,会默认转换为布尔类型,然后再做条件判断。
>>> if 666:
print('666判定不为空')
>>> if 'ee':
print('ee判定不为空')
>>> if 0:
print("000")
else:
print("111")
三、字符串
1.字符串的表示
msg = "hello world"
msg = """
hello world
hello python
"""
# 三个引号,支持多行/换行表示一个字符串
# 使用制表符添加空格
>>> print("Languages:\n\tPython\n\tC\n\tJava")
Languages:
Python
C
Java
2.常见方法
(1) startswith() / endswith() 判断字符串是否以xx开头/结尾?得到一个布尔值
>>> msg = 'hello world'
>>> ret = msg.startswith('he')
>>> print(ret) # True
>>> ret2 = msg.endswith('ld')
>>> print(ret2) # True
(2) split() / join() 字符串切割,得到一个列表;字符串拼接,得到一个新字符串
- 分割:split()可以基于指定分隔符将字符串分隔成多个子字符串(存储到列表中)。如果不指定分隔符,则默认使用空白字符(换行符/空格/制表符)。
- 拼接:join()的作用和 split()作用刚好相反,用于将一系列子字符串连接起来。
注:使用“+”拼接字符串,会生成新的字符串对象;使用join函数,join函数在字符串拼接前会计算字符串的长度,然后逐一拷贝,仅新建一次对象。
>>> msg = '123|python|456'
>>> ret = msg.split('|')
>>> print(ret) # ['123', 'python', '456']
>>> msg_list = ['111','python','222']
>>>> ret2 = '_'.join(msg_list)
>>> print(ret2) # 111_python_222
# 字符串拼接," + "
>>> first_name = "ada"
>>> last_name = "lovelace"
>>> full_name = first_name + " " + last_name
>>> print("hello," + full_name.title() + "!") # hello,Ada Lovelace!
(3) title() / upper() / lower() 修改字符串大小写,得到一个新字符串
>>> msg = "hello world"
>>> ret = msg.title()
>>> print(ret) # Hello World
>>> ret2 = msg.upper()
>>> print(ret2) # HELLO WORLD
>>> ret3 = msg.lower()
>>> print(ret3) # hello world
(4) strip() 去除字符串两边的空格、换行符、制表符,得到一个新字符串
>>> msg = " python "
>>> ret = msg.strip()
>>> print(ret) # python
注:title(),upper(),lower(),strip()都是对字符串的一次性操作,要想永久改变字符串,必须将修改后的操作结果存回到变量中,即的命名格式小写字母加下划线,msg=msg.title()。
(5) replace() 字符串内容替换,得到一个新字符串
>>> msg = "hello,python!hello,world!"
>>> ret = msg.replace('hello','hey')
>>> print(ret) # hey,python!hey,world!
(6) format() 格式化字符串,得到一个新字符串
- 格式化字符串:所谓格式化字符串,就是预先制定好一个模板,在模板中预留几个空位,然后根据需要填上相应的内容。
(1).旧式格式化字符串( % 运算符 )
>>> name = "Bob"
>>> error = "Index"
>>> num = 10
>>> ret = "Hey %s,there is a %s error,and this errors have %d!" % (name,error,num)
>>> print(ret) # Hey Bob,there is a Index error,and this errors have 10!
(2).新式格式化字符串( str.format )
>>> ret = "{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
>>> print(ret) # hello world
>>> ret2 = "{0} {1}".format("hello", "world") # 设置指定位置
>>> print(ret2) # hello world
>>> ret3 = "网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com")
>>> print(ret3) # 网站名:菜鸟教程, 地址 www.runoob.com
# 通过字典设置参数
>>> site = {
"name": "菜鸟教程", "url": "www.runoob.com"}
>>> ret4 = "网站名:{name}, 地址 {url}".format(**site)
>>> print(ret4) # 网站名:菜鸟教程, 地址 www.runoob.com
(3).字符串插值 / f-Strings(Python 3.6+)
# 这种格式化字符串的新方法允许在字符串常量中使用嵌入的 Python 表达式,在字符串常量前加上字母“f”。
>>> a,b = 5,10
>>> ret = f"Five plus ten is {a + b} and not {2 * (a + b)}."
>>> print(ret) # Five plus ten is 15 and not 30.
3.转换为字符串
- python开发中经常使用的是:数字转换为字符串类型
>>> num = 888
>>> data = str(num)
>>> print(type(data)) # 4.公共的功能
(1) len() 获取字符串长度
>>> msg = "python"
>>> ret = len(msg)
>>> print(ret) # 6
(2) 索引 获取字符串中某个字符的值
>>> msg = "python"
>>> print(msg[0]) # p
>>> print(msg[-1]) # n
>>> print(msg[len(msg)-1]) # n
(3) 切片 获取字符串中n连续的字符的值
>>> msg = "hello,python"
>>> print(msg[:]) # hello,python
>>> print(msg[1:]) # ello,python
>>> print(msg[:6]) # hello,
>>> print(msg[2:-1]) # llo,pytho
>>> print(msg[0:len(msg)]) # hello,python
(4) 步长 字符串中 跳步选择数据
>>> msg = "hello,python"
>>> print(msg[0:5:2]) # hlo
>>> print(msg[:8:2]) # hlop
>>> print(msg[2::3]) # l,tn
>>> print(msg[::2]) # hlopto
>>> print(msg[6:1:-1]) # p,oll
>>> print(msg[::-1]) # nohtyp,olleh
(5) for循环 想要循环显示字符串的每个字符,通过之前的 while循环 + 索引 可以实现,现在通过for循环则可以更方便的实现
>>> msg = "python"
>>> for item in msg:
print(item)
p
y
t
h
o
n
5.字符串编码
- ASCII 编码:10个数字、26个英文字母、一些特殊字符。最多表示256个符号,每个字符占用一个字节。
- GBK、GB2312编码:我国制定的中文编码标准,规定英文字符母占用 1 个字节,中文字符占用 2 个字节;
- UTF-8 编码:国际通用的编码格式,它包含了全世界所有国家需要用到的字符,其规定英文字符占用 1 个字节,中文字符占用 3 个字节。
- python3常用的两种字符串类型,str和bytes。
- python3:默认使用utf-8编码,所以可以正常解析中文,无需指定 UTF-8 编码。str用来表示Unicode字符,bytes用来表示二进制数据。
>>> s = "python中文"
>>> t = s.encode() # 编码。。将str转换成bytes类型。python默认utf-8编码
>>> t
b'python\xe4\xb8\xad\xe6\x96\x87'
>>> tt = s.encode("GBK") # 也可手动指定其他编码格式
>>> tt
b'python\xd6\xd0\xce\xc4'
>>> t.decode() # 解码。。将bytes转换成str类型。
'python中文'
四、元组
(1)python将不能修改的值称为不可变的,而不可变的列表被称为元组。
(2)元组的元素不允许添加、删除和修改,只能读。
1.元组的定义
- 建议在元组的最后多加一个逗号,用于标识它是一个元组;
- 元组只有一个元素时,必须添加逗号。
msg = (11,22,33)
msg = ('123','python',)
msg = ('c',)
2.字符串、列表转换为元组:
- 其他类型转换为元组,一般可以被循环的元素才能转换,目前只有字符串和列表。
(1).字符串转元组
>>> name = 'python'
>>> data = tuple(name)
>>> data
('p', 'y', 't', 'h', 'o', 'n')
(2).列表转元组
>>> name_list = ['python','java','c']
>>> data = tuple(name_list)
>>> data
('python', 'java', 'c')
3.其他(公共的功能)
(1) len() 获取元组长度
>>> user_tuple = ('wang','zhao','qian','li')
>>> print(len(user_tuple)) # 4
(2) 索引 获取元组中某个字符的值
>>> user_tuple = ('wang','zhao','qian','li')
>>> print(user_tuple[0]) # wang
>>> print(user_tuple[-1]) # li
(3) 切片 获取元组中n连续的字符的值
>>> user_tuple = ('wang','zhao','qian','li')
>>> print(user_tuple[0:2]) # ('wang', 'zhao')
>>> print(user_tuple[1:]) # ('zhao', 'qian', 'li')
>>> print(user_tuple[:-1]) # ('wang', 'zhao', 'qian')
(4) 步长 元组中 跳步选择数据
>>> user_tuple = ('wang','zhao','qian','li','ding','tian','hu')
>>> print(user_tuple[1:4:2]) # ('zhao', 'li')
>>> print(user_tuple[0::2]) # ('wang', 'qian', 'ding', 'hu')
>>> print(user_tuple[1::2]) # ('zhao', 'li', 'tian')
>>> print(user_tuple[4:1:-1]) # ('ding', 'li', 'qian')
(5) for循环
>>> for item in user_tuple:
print(item)
wang
zhao
qian
li
ding
tian
hu
4.嵌套
- 由于列表和元组都可以充当 容器 ,它们内部都可以放很多元素,并且支持元素内的各种嵌套。
>>> tu = (11,22,(33,44))
>>> tu1 = tu[0]
>>> print(tu1) # 11
>>> tu2 = tu[2][1]
>>> print(tu2) # 44
知识补充:range
- range在python中可以快速生成一个特定范围的数字 列表
v1 = range(1,6) # 生成的数为:[1、2、3、4、5]
v2 = range(1,6,2) # 生成的数为:[1、3、4]
v3= range(6,1,-1) # 生成的数为:[6、5、4、3、2]
注:
- 在python2中range会直接生成列表;python2中的xrange和python3中的range相同,生成range对象;
- 在python3中range生成是一个range对象(不会立即在内存中创建这些数,而是在循环时边使用边创建,节省内存开销)
- python2执行:range(1,1000000) 数据全部创建,速度很慢
- python3执行:range(1,1000000) 数据不立即创建,速度很快
range和for循环
- 在项目开发中range一般会和for循环放在一起使用,进而获取一些数字。
(1).数字
for i in range(10,0,-1):
print(i)
(2).列表
user_list = ["wang","zhao",'li',"zhao","qian"]
for i in range(0,len(user_list)):
print(i, user_list[i]) # i取的是(0,len(user_list))范围内的数值,int类型
for i in user_list:
print(i) # i取的是user_list内的元素,str类型
(3).字符串
username = "wang"
for i in range(0,len(username)):
print(i, username[i])
(4).元组
num_tuple = ("wang","zhao",'li')
for i in range(0,len(num_tuple)):
print(i,len(i))
五、列表
(1)列表非常适合用于存储在程序运行期间可能变化的数据集
(2)可以把列表当作是一个有序的容器,在里面可以存放很多的元素
(3)追加、删除、索引、切片、长度、循环、包含、复制列表
1.列表的定义
>>> number_list = [98,88,666,12,-1]
>>> data_list = [1,True,"zhang"]
2.常用方法
(1) append() / insert() / extend() 原列表增加元素
bicyles = ['trek','cannondale','redline','specialized']
(1).追加,在原列表中尾部追加值
>>> bicyles = ['trek','cannondale','redline','specialized']
>>> bicyles.append('honda')
>>> print(bicyles) # ['trek', 'cannondale', 'redline', 'specialized', 'honda']
(2).插入,在原列表的指定索引位置插入值
>>> bicyles.insert(1,'yamaha')
>>> print(bicyles) # ['trek', 'yamaha', 'cannondale', 'redline', 'specialized']
(3).扩展,将一个列表中的元素一次性添加到另外一个列表的末尾
>>> bicyles2 = ['trek2','cannondale2','redline2','specialized2']
>>> bicyles.extend(bicyles2)
>>> print(bicyles) # ['trek', 'cannondale', 'redline', 'specialized', 'trek2', 'cannondale2', 'redline2', 'specialized2']
(2) pop() / remove() / del / clear() 删除原列表中元素
bicyles = ['trek', 'yamaha', 'cannondale', 'redline', 'specialized', 'honda']
(1).在原列表中根据索引踢出某个元素,方法pop()有返回值 / del 无返回值
>>> ret = bicyles.pop() # 删除bicyles中最后一个元素,并将删除值赋值给ret
>>> ele = bicyles.pop(2) # 删除bicyles中索引为 2的元素,并将删除值赋值给ele
>>> print(ret) # 'honda'
>>> print(bicyles) # ['trek', 'yamaha', 'cannondale', 'redline', 'specialized']
>>> del bicyles[1]
>>> print(bicyles) # ['trek', 'cannondale', 'redline', 'specialized', 'honda']
(2).在原列表中根据值删除(从左到右找到第一个删除),方法remove() 没有返回值
>>> bicyles.remove('trek')
>>> print(bicyles) # ['yamaha', 'cannondale', 'redline', 'specialized', 'honda']
(3).清空原列表,方法clear() 没有返回值
>>> bicyles = ['trek', 'yamaha', 'cannondale', 'redline', 'specialized', 'honda']
>>> bicyles.clear()
>>> print(bicyles) # []
(3) reverse() 反转原列表
bicyles = ['trek','cannondale','redline','specialized']
>>> bicyles.reverse()
>>> print(bicyles) # ['specialized', 'redline', 'cannondale', 'trek']
(4) sort() / sorted() 列表排序
bicyles = ['trek','cannondale','redline','specialized']
(1).永久性排序,方法sort();按照字母相反的顺序,向sort()传递参数reverse=True
>>> bicyles.sort()
>>> print(bicyles) # ['cannondale', 'redline', 'specialized', 'trek']
>>> bicycle.sort(reverse=True)
>>> print(bicyles) # ['trek', 'specialized', 'redline', 'cannondale']
(2).临时按照特定顺序进行排序,不影响原始排列顺序,函数sorted()有返回值,按照字母相反的顺序,向sorted()传递参数reverse=True
>>> ret_list = sorted(bicyles)
>>> print(ret_list) # ['cannondale', 'redline', 'specialized', 'trek']
>>> print(bicyles) # ['trek', 'cannondale', 'redline', 'specialized']
3.转换为列表
- 如果想要让某些元素转换为列表类型,一般需要通过list强转,它的内部其实就是循环每个元素,再将元素追加到列表中。
- 所以,想要转换为列表类型有要求:必须可以被循环的元素才能转换为列表。
bicyles = ['trek','cannondale','redline','specialized']
(1).字符串
>>> msg = 'python'
>>> ret = list(msg)
>>> print(ret) # ['p', 'y', 't', 'h', 'o', 'n']
(2).元组
>>> tu = (11,22,33,44)
>>> ret2 = list(tu)
>>> print(ret2) # [11, 22, 33, 44]
(3).字典
>>> dic = {
1:'22',2:'33'}
>>> ret3 = list(dic)
>>> print(ret3) # [1, 2] 获取字典中所有的键
4.其他(公共的功能)
(1) len() 获取列表长度
>>> user_list = ['wang','zhao','qian','li']
>>> print(len(user_list)) # 4
(2) 索引 获取列表中某个字符的值
>>> user_list = ['wang','zhao','qian','li']
>>> print(user_list[0]) # wang
>>> print(user_list[-1]) # li
(1).根据索引删除元素
>>> user_list = ['wang','zhao','qian','li']
>>> del user_list[0]
>>> print(user_list) # ['zhao', 'qian', 'li']
(2).根据索引替换元素
>>> user_list = ['wang','zhao','qian','li']
>>> user_list[1] = 'ding'
>>> print(user_list) # ['wang', 'ding', 'qian', 'li']
(3) 切片 获取列表中n连续的字符的值
>>> user_list = ['wang','zhao','qian','li']
>>> print(user_list[0:2]) # ['wang', 'zhao']
>>> print(user_list[1:]) # ['zhao', 'qian', 'li']
>>> print(user_list[:-1]) # ['wang', 'zhao', 'qian']
(4) 步长 列表中 跳步选择数据
>>> user_list = ['wang','zhao','qian','li','ding','tian','hu']
>>> print(user_list[1:4:2]) # ['zhao', 'li']
>>> print(user_list[0::2]) # ['wang', 'qian', 'ding', 'hu']
>>> print(user_list[1::2]) # ['zhao', 'li', 'tian']
>>> print(user_list[4:1:-1]) # ['ding', 'li', 'qian']
(5) for循环
(1).for循环遍历
>>> user_list = ['wang','zhao','qian']
>>> for item in user_list:
print(item)
wang
zhao
qian
# for循环,依次遍历列表中的各个元素,使用临时变量item进行存储;
# 在 for循环中可执行更多的操作;
# 在 for循环结束后执行一些操作;
# 避免不必要的缩进;避免遗漏冒号;
(2).创建数值列表
>>> for value in range(1,5):
print(value)
使用range()时,如果输出不符合预期,尝试将指定的值加1或减1;
(3).列表解析
>>> even_nums = list(range(2,11,2))
>>> print(even_nums) # [2, 4, 6, 8, 10]
>>> squares = [value*2 for value in range(1,11)]
>>> print(squares) # [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
5.嵌套
- 列表属于 容器 ,内部可以存放各种数据,所以列表支持列表的嵌套。
- 对于嵌套的值,可以根据索引进行学习。
>>> li = [11,22,[33,44],55]
>>> li1 = li[0]
>>> print(li1) # 11
>>> li2 = li[2][1]
>>> print(li2) # 44
6.复制列表
列表的复制一共有三种原理:
赋值:(1)复制列表元素的同时也将列表的地址一并复制;当原列表n发生变化时,a也发生变化;
浅拷贝:(2)-(5)只复制列表元素,当列表n内部的子列表做出改变时,b,c,d,e中的子列表也将发生改变;
深拷贝:(6)当原列表a或其a中的子列表发生改变时,f将不发生任何变化;
>>> n = [1, 2, [3, 4]]
>>> import copy
>>> a = n (1)
>>> b = n[:] (2)
>>> c = n.copy() (3)
>>> d = list(n) (4)
>>> e = copy.copy(n) (5)
>>> f = copy.deepcopy(n) (6)
>>>> print('n:',id(n),'\n','a:',id(a),'\n','b:',id(b),'\n','c:',id(c),'\n','d:',id(d),'\n','e:',id(e),'\n','f:',id(f),'\n')
n: 2380201858240
a: 2380201858240
b: 2380201510208
c: 2380201858880
d: 2380201509760
e: 2380201509312
f: 2380201450304
>>> n[0] = 111
>>>> print(' n:',n,'\n','a:',a,'\n','b:',b,'\n','c:',c,'\n','d:',d,'\n','e:',e,'\n','f:',f,'\n')
n: [111, 2, [3, 4]]
a: [111, 2, [3, 4]]
b: [1, 2, [3, 4]]
c: [1, 2, [3, 4]]
d: [1, 2, [3, 4]]
e: [1, 2, [3, 4]]
f: [1, 2, [3, 4]]
>>> n[2][1] = 333
>>> print(' n:',n,'\n','a:',a,'\n','b:',b,'\n','c:',c,'\n','d:',d,'\n','e:',e,'\n','f:',f,'\n')
n: [111, 2, [3, 333]]
a: [111, 2, [3, 333]]
b: [1, 2, [3, 333]]
c: [1, 2, [3, 333]]
d: [1, 2, [3, 333]]
e: [1, 2, [3, 333]]
f: [1, 2, [3, 4]]
>>> print('n:',id(n[2]),'\n','a:',id(a[2]),'\n','b:',id(b[2]),'\n','c:',id(c[2]),'\n','d:',id(d[2]),'\n','e:',id(e[2]),'\n','f:',id(f[2]),'\n')
n: 2380201510016
a: 2380201510016
b: 2380201510016
c: 2380201510016
d: 2380201510016
e: 2380201510016
f: 2380201522752
- 深浅拷贝:
- 对于数字和字符串而言,赋值、浅拷贝和深拷贝没有意义,因为其永远指向同一个内存地址。
>>> import copy
>>> n = "123"
>>>> id(n)
2374287412656
>>> n1 = n
>>> id(n1)
2374287412656
>>> n2 = copy.copy(n)
>>> id(n2)
2374287412656
>>> n3 = copy.deepcopy(n)
>>> id(n3)
2374287412656

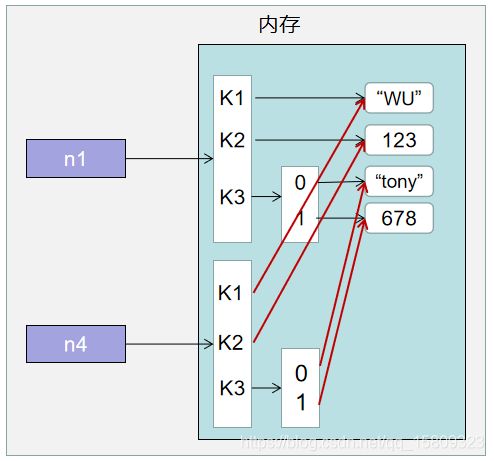
- 对于字典、元组、列表而言,进行赋值、浅拷贝、深拷贝时,内存地址的变化时不同的。
1. 赋值
>>>> n1 = {
"k1": "wu", "k2": 123, "k3": ["tony", 456]}
>>> n2 = n1
>>> print(id(n1),id(n2))
2374287088896 2374287088896
>>> print(id(n1['k3']),id(n2['k3']))
2374281138496 2374281138496

2. 浅拷贝
在内存中只额外创建第一层数据
>>> import copy
>>> n1 = {
"k1": "wu", "k2": 123, "k3": ["tony", 456]}
>>> n3 = copy.copy(n1)
>>> print(id(n1),id(n3))
2374287088896 2374287451008
>>> print(id(n1['k3']),id(n3['k3']))
2374281138496 2374281138496

3. 深拷贝
在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
>>> import copy
>>> n1 = {
"k1": "wu", "k2": 123, "k3": ["tony", 456]}
>>> n4 = copy.deepcopy(n1)
>>> print(id(n1),id(n4))
2374287088896 2374287451264
>>> print(id(n1['k3']),id(n4['k3']))
2374281138496 2374281137856
六、字典
(1) 字典也可以当作是一个容器,在内部存放数据。相较于元组和列表,字典的元素必须是键值对。
(2) 在python3.6+字典就是有序的了,之前的字典都是无序的。
1.字典的定义
info = {
"age":12, "status":True, "name":"wang","hobby":['篮球','足球']}
department_dict = {
"IT部门":["zhang","wang"],
"销售部":["张三","刘能","张扬"],
"财务部":["xu"],
}
department_dict = {
"zhang":{
"id":1,"gender":"男","email":"[email protected]"},
"wang":{
"id":1,"gender":"男","email":"[email protected]"},
...
}
注:字典的键必须可哈希。
- 可哈希的类型:int ,bool,str,tuple
- 部可哈希的类型:list ,dict
2.常见方法
(1) keys() 获取字典所有的键
>>> info = {
"age":12, "status":True, "name":"wang","email":"[email protected]"}
>>> data = info.keys() # 获取字典的所有的键,返回一个`高仿的`列表,存放的都是字典中的key
>>> print(data) # dict_keys(['age', 'status', 'name', 'email'])
>>> for i in info.keys():
print(i)
age
status
name
email
(2) values() 获取字典所有的值
>>> info = {
"age":12, "status":True, "name":"wang","email":"[email protected]"}
>>> data = info.values()
>>> print(data) # dict_values([12, True, 'wang', '[email protected]'])
>>> for j in info.values():
print(j)
12
True
wang
xx@live.com
注:
- 在Python2中,字典.keys()直接获取到的是列表;
- Python3中返回的是高仿列表,这个高仿的列表可以被循环显示
(3) items() 获取字典所有的键值对
>>> info = {
"age":12, "status":True, "name":"wang","email":"[email protected]"}
>>> data = info.items()
>>> print(data) # dict_items([('age', 12), ('status', True), ('name', 'wang'), ('email', '[email protected]')])
>>> for item in info.items():
print(item) # item是一个元组 (键,值)
('age', 12)
('status', True)
('name', 'wang')
('email', '[email protected]')
>>> for key,value in info.items():
print(key,value) # key代表键,value代表值,将键值从元组中直接拆分出来了
age 12
status True
name wang
email xx@live.com
(4) update() 更新字典的键值对
>>> info = {
"age":12, "status":True}
>>> info.update({
'age':20,'name':'wang'}) # info中没有的键直接添加,有的则更新值
>>> print(info) # {'age': 20, 'status': True, 'name': 'wang'}
(5) pop() 移除字典的键值对,有返回值
>>> info = {
"age":12, "status":True, 'name':'wang'}
>>> data = info.pop('age')
>>> print(data) # 12
>>> print(info) # {'status': True, 'name': 'wang'}
(6) get() 根据键获取值
>>> info = {
"age":12, "status":True, 'name':'wang'}
>>> data = info.get('age',None) # 根据age为键去info字典中获取对应的值,如果不存在则返回None,存在则返回值
>>> print(data) # 12 键age存在,则返回对应值
>>> data = info.get('sex')
>>> print(data) # None 键sex不存在,则返回None
>>> data = info.get('sex','male')
>>> print(data) # male 键sex不存在,返回给定值male
3.转换
- 由于字典的每一个元素都是键值对,所以想要转换为字典必须要有个特定的格式才能转换成功。
- 子元素必须包含两个元素,从而将值对应给字典的键、值
(1).元组
v = dict([("k1","v1"),("k2","v2")])
print(v) # 输出:{'k2': 'v2', 'k1': 'v1'}
(2).列表
v = dict([["k1","v1"], ["k2","v2"]])
print(v) # 输出:{'k2': 'v2', 'k1': 'v1'}
4.其他(公共的功能)
(1) len() 获取字典长度
>>> info = {
"age":12, "status":True, 'name':'wang'}
>>> data = len(info)
>>> print(data) # 3
(2) 索引 字典不同于元组和列表,字典的索引是键,而列表和元组则是0,1,… 数值。
>>> info = {
"age":12, "status":True, 'name':'wang'}
>>> print(info['age']) # 12
>>> print(info['sex']) # 报错:KeyError: 'sex',通过键为索引获取值时,键不存在会报错(以后项目开发时建议使用get方法根据键去获取值)
注: 字典根据键的查找速度非常快,远远大于列表或元组通过索引查找的速度,因为字典内部是基于hash存储。
(3) 根据键 添加、删除、修改键值对
>>> info = {
"age":12, "status":True, 'name':'wang'}
>>> info['gender'] = 'male' # gender键在字典中不存在,则自动在字典中新添加一个键值对
>>> print(info) # {'age': 12, 'status': True, 'name': 'wang', 'gender': 'male'}
>>> info['age'] = 21 # age键在info字典中已存在,则更新键对应的值
>>> print(info) # {'age': 21, 'status': True, 'name': 'wang', 'gender': 'male'}
>>> del info['gender'] # 删除info字典中键为gender的键值对(键不存在则报错)
>>> print(info) # {'age': 21, 'status': True, 'name': 'wang'}
(4) for循环
- 由于字典也属于容器,内部可以包含多个键值对,可以通过循环对其中的:键、值、键值进行循环
>>> info = {
"age":12, "status":True, 'name':'wang'}
>>> for item in info.keys(): # keys()方法可省略,等价于 for item in info: print(item)
print(item)
age
status
name
>>> for item in info.values():
print(item)
12
True
wang
>>> for key,value in info.items():
print(key,value)
age 12
status True
name wang
(5) 字典嵌套
- int, str, tuple, list, dict 五种常见数据类型中,只有tuple,list,dict类型中可包含子元素,因此可进行数据的嵌套;
- 但在嵌套和对内部数据操作时要注意:元组子元素不能变、不可哈希的list、dict不能做字典的键。
字典列表:[{
},{
},{
}...]
在字典中存储列表:{
'key1':['',''],'key2':['','',''],...}
字典中存储字典:{
'key1':{
'k1':'v1','k2':'v2'},'key2':{
'k3':'v3','k4':'v4'}}
>>> for item in user_tuple:
print(item)
wang
zhao
qian
li
ding
tian
hu
七、集合
(1) 集合与元组和列表相似都用于做容器,在内部可以放一些子元素;
(2) 集合有三个特殊特点:子元素不重复、子元素必须可哈希、无序;
(3) 目前可哈希的数据类型int,str,tuple;不可哈希的类型list,dict,set
1.集合的定义
>>> v1 = {
1,2,99,18}
>>> v2 = {
1,True,"world",(11,22,33)}
- 集合与字典虽然都是用{},但字典内部是键值对,集合内部直接是值。
2.常见方法
(1) add() 集合内添加元素
>>> data = {
"刘嘉玲", '关之琳', "王祖贤"}
>>> data.add('陈慧琳')
>>> print(data) # {'陈慧琳', '关之琳', '刘嘉玲', '王祖贤'}
>>> data = set()
>>> data.add('周杰伦')
>>> data.add('林俊杰')
>>> print(data) # {'周杰伦', '林俊杰'}
(2) discard() 删除集合内元素
>>> data = {
"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"}
>>> data.discard('关之琳')
>>> print(data) # {'刘嘉玲', '王祖贤', '李若彤', '张曼⽟'}
(3) 交集
>>> s1 = {
"刘嘉玲", '关之琳', "王祖贤"}
>>> s2 = {
"张曼玉", '关之琳', "李若彤"}
>>> s3 = s1 & s2 # 方式一,取两个集合的交集
>>> s4 = s1.intersection(s2) # 方式二,取两个集合的交集
>>> print(s3,s4) # {'关之琳'}
(4) 并集
>>> s1 = {
"刘嘉玲", '关之琳', "王祖贤"}
>>> s2 = {
"张曼玉", '关之琳', "李若彤"}
>>> s3 = s1 | s2 # 方式一,取两个集合的并集
>>> s4 = s1.union(s2) # 方式二,取两个集合的并集
>>> print(s3,s4) # {'刘嘉玲', '张曼玉', '王祖贤', '李若彤', '关之琳'}
(5) 差集
>>> s1 = {
"刘嘉玲", '关之琳', "王祖贤"}
>>> s2 = {
"张曼玉", '关之琳', "李若彤"}
>>> s3 = s1 - s2 # 方式一,差集,s1中有且s2中没有的值
>>> s4 = s1.difference(s2) # 方式二,差集,s1中有且s2中没有的值
>>> print(s3,s4) # {'刘嘉玲', '王祖贤'}
>>> s5 = s2-s1 # 方式一,差集,s2中有且s1中没有的值
>>> s6 = s2.difference(s1) # 方式二,差集,s2中有且s1中没有的值
>>> print(s5,s6) # {'张曼玉', '李若彤'}
3.转换
- 其他类型若要转换为集合,可以通过set进行转换,并且如果数据有重复自动剔除;
- str,tuple,list,dict都可以转换为集合
(1).字符串
>>> s = 'wang'
>>> s2 = set(s)
>>> print(s2) # {'a', 'w', 'n', 'g'}
(2).元组
>>> t = (11,22,33)
>>> t = (11,22,33,11)
>>> t2 = set(t)
>>> print(t2) # {33, 11, 22}
(3).列表
>>> l = [1,2,3,2,3,4,5,6]
>>> l2 = set(l)
>>> print(l2) # {1, 2, 3, 4, 5, 6}
(4).字典
>>> d = {
'age':12,'name':'wang','gender':'female','num':12}
>>> print(set(d.items())) # {('name', 'wang'), ('gender', 'female'), ('num', 12), ('age', 12)}
>>> print(set(d.keys())) # {'gender', 'age', 'num', 'name'}
>>> print(set(d.values())) # {12, 'female', 'wang'}
4.其他(公共的功能)
(1) 集合无索引、切片、步长
- 集合中没有提供 索引/切片/步长 这些功能,因为他无序,所以无法使用索引操作
(2) len() 获取集合长度
>>> data = {
"刘嘉玲", '关之琳', "王祖贤"}
>>> s = len(data)
>>> print(s) # 3
(3) for循环
>>> data = {
"刘嘉玲", '关之琳', "王祖贤"}
>>> for item in data:
print(item)
刘嘉玲
王祖贤
关之琳
数据类型总结:
| 类型 | 类名 | 定义 | 常见方法 | 转换 | 其他 | 嵌套 | 可哈希 | 备注 |
|---|---|---|---|---|---|---|---|---|
| 整型 | int | 11 | - | int(其他) | - | - | 是 | |
| 布尔值 | bool | True | - | bool(其他) | - | - | 是 | 类型空值和0转换成布尔值为False,其他为True |
| 字符串 | str | “python” | startswith() endswith() split() join() title() upper() lower() strip() replace() format () |
str(其他) | 长度len() 索引读 切片 步长 for循环 |
- | 是 | |
| 元组 | tuple | (‘北京’,‘上海’,) | - | tuple(其他) | 长度len() 索引读 切片 步长 for循环 |
支持 | 是 | 子元素只能读 |
| 列表 | list | [‘北京’,‘上海’] | append() insert() extend() pop() remove() clear() reverse() sort() copy() |
list(其他) | 长度len() 索引读、改 切片 步长 for循环 |
支持 | 否 | |
| 字典 | dict | {“name”:“wu”,“age”:18} | keys() values() items() update() pop() get() |
dict(其他) | 长度len() 索引读、写、改 for循环 |
支持 | 否 | 1.键不重复 2.键必须可哈希 |
| 集合 | set | {‘北京’,‘上海’} | add() discard() intersection() union() difference() |
set(其他) | 长度len() for循环 |
支持 | 否 | 1.值不重复 2.值必须可哈希 |