tushare数据实现股票温度计算
目录
-
- 1.tushare
- 2.股票温度
-
- 2.1计算方法
- 2.2.公式解释
- 3.实现
-
- 3.1.通过tushare获取数据
- 3.2.计算温度
- 3.3.温度和收盘价展示
- 3.4. 关于温度的统计分析
- 4.结语
1.tushare
一直用tushare获取数据,数据准确,获取方便,感谢米哥。
2.股票温度
股票价值投资 (Value Investing)一种常见的投资方式,专门寻找价格低估的证券。价值投资常用的参数就是pe,pb。可以用于个股,也可以用于板块,指数。本文用个股简单的举个例子而已。
2.1计算方法
f ( x , μ , σ ) = 1 2 π e − ( x − μ ) 2 2 σ ∗ 100 = F ( P e ) ∗ 100 f(x,\mu,\sigma) = \frac{1}{\sqrt{2\pi}}e^-\frac{(x-\mu)^2}{2\sigma}*100 = F(Pe) * 100 f(x,μ,σ)=2π1e−2σ(x−μ)2∗100=F(Pe)∗100
2.2.公式解释
假设Pe是服从正态分布的,则F(Pe)为Pe在此正态分布中纵坐标的值,取值范围是[0,1],则通过F(Pe)就可以计算Pe值在样本数据中是高分位还是低分位了。
3.实现
3.1.通过tushare获取数据
import tushare as ts
import datetime
ts.set_token(TOKEN) # TOKEN为个人申请值
pro = ts.pro_api()
end_date = datetime.date.today().strftime('%Y%m%d')
start_date = (datetime.date.today() - datetime.timedelta(days=365 * 10)).strftime('%Y%m%d') # 获取十年期间的数据
df = pro.daily_basic(ts_code='000001.sz', start_date=start_date, end_date=end_date, fields='ts_code,trade_date,close, turnover_rate,volume_ratio,pe,pe_ttm,pb')
print(df.head(5))
3.2.计算温度
import numpy as np
import pandas as pd
def norm_dist_func(x, _mean, _std):
result = norm_dist_func_s(x, _mean, _std)
return round(result * 100.0, 2)
def norm_dist_func_s(x, _mean, _std):
oor2pi = 1 / np.sqrt(2.0 * np.pi)
x2 = (x - _mean) / _std
if x2 == 0:
res = 0.5
else:
t = 1 / (1.0 + 0.2316419 * np.abs(x2))
t = t * oor2pi * np.exp(-0.5 * x2 * x2) * (0.31938153 + t * (-0.356563782 + t * (1.781477937 + t * (-1.821255978 + t * 1.330274429))))
if x2 > 0:
res = 1.0 - t
else:
res = t
return res
pe_std = np.std(df['pe'], ddof=1) # pe的标准差
pe_mean = np.mean(df['pe']) # pe的平均值
pb_std = np.std(df['pb'], ddof=1) # pb的标准差
pb_mean = np.mean(df['pb']) # pb的平均值
df['pe_temperature'] = df['pe'].apply(norm_dist_func, _mean=pe_mean, _std=pe_std) # 计算pe温度
df['pb_temperature'] = df['pb'].apply(norm_dist_func, _mean=pb_mean, _std=pb_std) # 计算pb温度
df['temperature'] = df['pe_temperature'] * 0.5 + df['pb_temperature'] * 0.5
3.3.温度和收盘价展示
可以看出,温度比较低的时候,上涨概率较大。

3.4. 关于温度的统计分析
dic_temperature_upper_counter = {} # 特定温度下的上涨次数
dic_temperature_upper_profit = {} # 特定温度下的上涨次数
dic_temperature_all = {} # 特定温度下的出现次数
for j in range(df.shape[0]):
temperature_level = str(int(df.iloc[j]['temperature_level']))
if temperature_level not in dic_temperature_upper_counter.keys():
dic_temperature_upper_counter[temperature_level] = 0
dic_temperature_all[temperature_level] = 0
dic_temperature_upper_profit[temperature_level] = 0
if df.iloc[j]['profit'] > 0:
dic_temperature_upper_counter[temperature_level] = dic_temperature_upper_counter[temperature_level] + 1
dic_temperature_all[temperature_level] = dic_temperature_all[temperature_level] + 1
for k, v in dic_temperature_upper_counter.items():
dic_temperature_upper_profit[k] = round(v / dic_temperature_all[k] * 100, 2)
print('温度{0}出现次数:{1}, 上涨概率{2}%'.format(k, dic_temperature_upper_counter[k], dic_temperature_upper_profit[k]))
sorted_dic_counter = sorted(dic_temperature_upper_profit.items(), key=lambda d: d[1], reverse=True)
print('股票:{0}最适宜温度是{1},上涨概率是{2}%'.format('000001.sz', sorted_dic_counter[0][0], sorted_dic_counter[0][1]))
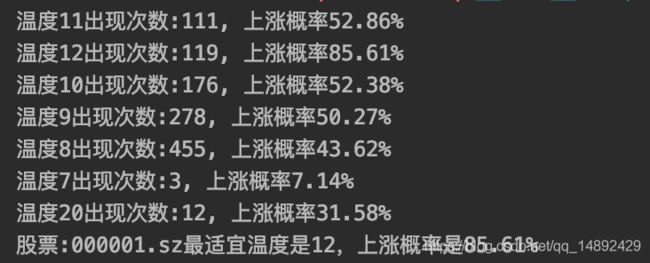
从统计数据中可以看出,并不是温度越低越好,每个股票都有自己的最适宜温度
4.结语
股票分析有很多方法,本文只是一个比较简单的方法来进行量化,再次感谢米哥提供如此好的数据源。