Nature盘点:从Fortran、arXiv到AlexNet,这些代码改变了科学界
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达

从 Fortran 编译器到 arXiv 预印本库、AlexNet,这些计算机代码和平台改变了科学界。
2019 年,「事件视界望远镜」团队拍下了第一张黑洞照片。这张照片并非传统意义上的照片,而是计算得来的——将美国、墨西哥、智利、西班牙和南极多台射电望远镜捕捉到的数据进行数学转换。该团队公开了所用代码,使科学社区可以看到,并基于此做进一步的探索。
而这逐渐成为一种普遍模式。从天文学到动物学,每一个伟大的现代科学发现背后都有计算机的身影。斯坦福大学计算生物学家、2013 年诺贝尔化学奖获得主 Michael Levitt 表示,现在的笔记本电脑在内存和时钟速度方面是 1967 年其实验室计算机的一万倍。「今天,我们拥有大量算力。但问题是,这仍然需要人类的思考。」
如果没有能够处理研究问题的软件以及知道如何编写和使用软件的研究人员,计算机再强大也是无用。「现在的研究与软件紧密相关,软件已经渗透到科研的方方面面。」软件可持续性研究所(Software Sustainability Institute)负责人 Neil Chue Hong 如是说。
最近,Nature 上的一篇文章试图揭示科学发现背后的重要代码,正是它们在过去几十年中改变了科研领域。这篇文章介绍了对科学界带来重大影响的十个软件工具,其中就包括与人工智能领域密切相关的 Fortran 编译器、arXiv、IPython Notebook、AlexNet 等。

语言先驱:Fortran 编译器(1957)
首批出现的现代计算机对用户并不友好。编程实际上是由手工完成的,通过电线连接一排排电路。后来的机器语言和汇编语言允许用户使用代码进行计算机编程,但这两种语言依然要求使用者对计算机架构有深入了解,导致很多科学家无法使用它们。
20 世纪 50 年代,随着符号语言的发展,尤其是「公式翻译」语言 Fortran 的出现,上述境况发生了改变。Fortran 语言由 IBM 的约翰 · 巴科斯(John Backus)团队开发。借助 Fortran,用户可以使用 x = 3 + 5 等人类可读的指令进行计算机编程,之后编译器将这类指令转化为快速高效的机器码。

这台使用 Fortran 编译器编程的 CDC 3600 计算机于 1963 年移送至美国国家大气研究中心。(图源:美国大气科学研究大学联盟 / 科学图片库。)
在早期,编程人员使用穿孔卡片(punch card)输入代码,复杂的模拟可能需要数万张穿孔卡片。不过,Fortran 使得并非计算机科学家的研究者也能够进行编程。普林斯顿大学气候学家 Syukuro Manabe 表示:「我们第一次靠自己进行编程。」他和同事使用 Fortran 语言开发了首批成功的气候模型之一。
60 多年过去了,Fortran 依然广泛应用于气候建模、流体动力学、计算机化学,以及其他涉及复杂线性代数并需要强大计算机快速处理数字的学科。Fortran 代码运行速度很快,仍然有很多编程人员知道如何写 Fortran。古老的 Fortran 代码库依然活跃在世界各地的实验室和超级计算机上。
信号处理器:快速傅里叶变换(1965)
当天文学家扫描天空时,他们捕捉到了随时间变化的复杂信号的杂音。为了理解这些无线电波的性质,他们需要观察这些信号作为频率函数的样子。一种被称为傅里叶变换(Fourier transform)的数学过程允许科学家实现这一点。但问题在于傅里叶变换并不高效,对大小为 N 的数据集它需要进行 N 次运算。
1965 年,美国数学家 James Cooley 和 John Tukey 开发了一种加速傅里叶变换过程的方法。借助递归(recursion)这种「分而治之」的编程方法(其中算法可以实现重复地再运用),快速傅里叶变换(fast Fourier transform, FFT)将计算傅里叶变换问题简化为 N log_2(N) 个步骤。速度也随着 N 的增加而提升。对于 1000 个点,速度提升约 100 倍;对于 100 万个点,速度提升约 5 万倍。
牛津大学数学家 Nick Trefethen 表示,FFT 的发现实际上是一种「再发现」,因为德国数学家卡尔 · 弗里德里希 · 高斯在 1805 年就完成了该发现,不过从未发表。但是,James Cooley 和 John Tukey 开启了 FFT 在数字信号处理、图像分析和结构生物学等领域中的应用。Trefethen 认为 FFT「是应用数学与工程领域伟大的发现之一。」FFT 已经在代码中实现了很多次,其中一种流行的变体是 FFTW(「西方最快的傅里叶变换」)。

默奇森天文望远镜,使用快速傅里叶变换来收集数据。
劳伦斯伯克利国家实验室(Lawrence Berkeley National Laboratory)分子生物物理学和综合生物成像部门主任 Paul Adams 回忆称,当他在 1995 年改进细菌蛋白 GroEL 的结构时,即使使用 FFT 和一台超级计算机,也需要「很多很多个小时,甚至是几天」的计算。但要没有 FFT,很难想象这件事要怎么做,花的时间将难以估量。
线性代数运算标准接口:BLAS(1979)
科学计算通常涉及使用向量和矩阵的数学运算,这些运算相对简单,但计算量大。20 世纪 70 年代,学界并没有出现一套普遍认可的执行此类运算的工具。因此,科研工作者不得不花费时间设计高效的代码来做基础的数学运算,导致无法专注于科学问题本身。
编程世界需要一个标准。1979 年,基础线性代数子程序库(Basic Linear Algebra Subprograms, BLAS)应运而生。直到 1990 年,该标准仍然在发展变化,定义了数十条涵盖向量和矩阵运算的基本程序。
田纳西州大学计算机科学家、BLAS 开发团队成员之一 Jack Dongarra 表示,BLAS 实际上将矩阵和向量运算简化成了像加减法一样的基础计算单元。
Cray-1 超级计算机。(图源:科学历史图像 / Alamy)
德州大学奥斯汀分校计算机科学家 Robert van de Geijn 表示:「BLAS 可能是为科学计算而定义的最重要接口。」除了为常用函数提供标准名称之外,研究者可以确保基于 BLAS 的代码能够以相同的方式在任何计算机上运行。该标准也使得计算机制造商能够优化 BLAS 实现,以实现硬件上的快速运行。
40 多年来,BLAS 代表了科学计算堆栈的核心,使得科学软件持续发展。乔治华盛顿大学机械与航空航天工程师 Lorena Barba 将 BLAS 称为「五层代码内的核心机制」。
预印本平台:arXiv.org(1991)
20 世纪 80 年代末,高能物理领域的研究者往往会把自己提交的论文邮寄给同行审阅,这是一种礼仪,但只邮寄给少数几个人。「那些处于食物链底端的人依赖于顶端人的施舍,这往往会把非精英机构中有抱负的研究者完全排除在特权圈之外,」物理学家 Paul Ginsparg 曾在 2011 年的一篇文章中写道。
1991 年,洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)的 Ginsparg 写了一个电子邮件自动回复器,以建立公平的竞争环境。邮件订阅者每天都会收到一份预印本列表,每份论文都带有标识符。如此一来,世界各地的用户都可以通过一封电子邮件提交或检索来自上述实验室计算机系统的论文。
Ginsparg 原本计划将文章保留三个月,将范围限制在高能物理社区,但他的同事劝他去掉了这些限制。「就是在那一刻,它从布告栏转变成了档案库,」Ginsparg 表示。在这之后,大批论文开始涌入,其学科之广远远超出了 Ginsparg 的预期。1993 年,Ginsparg 把这个系统移植到互联网上。1998 年,他正式将该系统命名为 arXiv.org。
如今,30 岁的 arXiv 收录了 180 万份预印本文章,且全部免费阅读,其每月论文提交量超过 15000 份,每月下载量高达 3000 万次。「不难看出 arXiv 为何如此受欢迎,」Nature Photonics 的编辑曾表示,「该系统为研究者提供了一种快捷、方便的科研方式,可以告诉大家你在做什么、什么时间做的,省去了传统期刊同行评审的繁琐。」
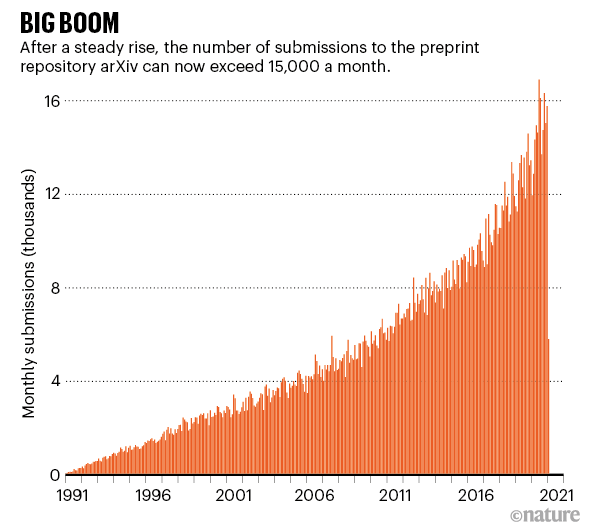
该网站的成功还对生物学、医学、社会学等其他学科类似存储库的建立起到了助推作用,成千上万份新冠病毒相关研究预印本的发布就是一个例证。
数据探索器:IPython Notebook (2011)
Fernando Pérez 在 2001 年决定「探寻拖延症」,当时他是一名研究生,决定采用 Python 的核心组件。
Python 是一种解释型语言,意味着程序会一行一行地执行。编程人员可以使用一种被称为「读取 - 求值 - 输出循环(REPL)」的计算型调用和响应(call-and-response)工具,他们可以键入代码,然后由解释器执行代码。REPL 允许快速探索和迭代,但 Pérez 指出 Python 并不是为科学构建的。例如,它不允许用户轻松地预加载代码模块或保持数据可视化的打开状态。因此 Pérez 创建了自己的版本。
2001 年 12 月,Pérez 发布了交互式 Python 解释器 IPython,它共有 259 行代码。10 年后,Pérez 和物理学家 Brian Granger、数学家 Evan Patterson 合作,将该工具迁移到 Web 浏览器,创建了 IPython Notebook,掀起了一场数据科学的革命。
和其他计算型 notebook 一样,IPython Notebook 将代码、结果、图形和文本组合到了单个文档中。但与其他此类型项目不同的是,IPython Notebook 是开源的,欢迎广大社区开发者为其发展做出贡献,并且支持 Python 这种科学家常用的语言。2014 年,IPython 演变成 Project Jupyter,支持约 100 种语言,并允许用户像在自己计算机上一样轻松地在远程超级计算机上探索数据。
Nature 在 2018 年指出:「对数据科学家而言,Jupyter 已经成为一种实际标准」。那时,GitHub 上已经有 250 万个 Jupyter notebook,如今已有近一千万个,其中包括 2016 年发现引力波和 2019 年黑洞成像的记录。Pérez 表示:「我们能为这些项目做出一点贡献也是非常有意义的」。
快速学习器:AlexNet(2012)
人工智能(AI)可分为两类,一类使用编码规则,另一类让计算机通过模拟大脑的神经结构来「学习」。多伦多大学计算机科学家、图灵奖获得者 Geoffrey Hinton 表示:「几十年来,人工智能研究者一直将第二种研究方法视为『荒谬』」。2012 年,Hinton 的研究生 Alex Krizhevsky 和 Ilya Sutskever 证明了事实并非如此。
在当年的 ImageNet 的年度竞赛上,研究者们被要求在包含 100 万张日常物品图像的数据库上训练 AI,然后在另一个图像集上测试算法。Hinton 表示:「在当时,最佳算法会在 1/4 的图像上出现分类错误」。Krizhevsky 和 Sutskever 开发的 AlexNet 是一种基于神经网络的深度学习算法,该算法将误差率降至 16%。Hinton 表示:「我们几乎将误差率降低了一半」。
Hinton 认为,该团队在 2012 年的成功反映出足够大的训练数据集、出色的编程和图形处理单元(最初为了提高计算机视频性能的处理器)新力量的结合。他表示:「突然之间,我们就能够将该算法的速度提高 30 倍,或者说可以学习 30 倍的数据」。
Hinton 表示真正的算法突破实际上发生在 3 年前。当时他的实验室创建了一个比几十年来不断完善的传统 AI 更能准确识别语音的神经网络。虽然准确率只稍微提升了一点,但已值得被记住。
AlexNet 及相关研究的成功带来了实验室、临床等多个领域深度学习的兴起。它让手机能够理解语音查询,也让图像分析工具能够轻松地从显微照片中挑选出细胞。这就是 AlexNet 在改变科学、改变世界的工具中占有一席之地的原因。
除了以上这些项目之外,入选该榜单的代码还包括生物数据库、大气环流模型、图像处理软件 NIH Image / ImageJ / Fiji 和生物大分子序列比对搜索工具 BLAST。感兴趣的同学可以去阅读原文。
原文链接:https://www.nature.com/articles/d41586-021-00075-2
推荐阅读
(点击标题可跳转阅读)
-
工作007,8天完成688次实验,独立发现催化剂:机器人研究员登上Nature封面
-
AI力量大集结!中国团队首次在Nature子刊发布中国AI全景论文
-
感知机搞不定逻辑XOR?Science新研究表示人脑单个神经元就能做到
-
3D特效师可以下班了丨Science
© THE END

转载请联系本公众号获得授权
投稿或寻求报道:[email protected]
