Blink/Flink 实践案例中的知识点整理
文章目录
- 实践案例的知识点整理
-
- 确定最终付款交易时间和订单确定时间
- 如何判断有效订单
- 点击次数作为PV、对客户的IP去重作为UV
- 怎么解决数据倾斜?
- 滚动窗口 全站总人数及走势
- 热门直播房间排行
- 去重操作
- 流计算回撤统计问题
实践案例的知识点整理
实践案例部分在内部文档中有更多的案例,但是内容很重复,学习过程中经常看到一样的内容,我认为在这部分的阅读过程中不需要像我一样把所有的案例都读一遍,只需要看我下面整理的问题就可以了,难度并不大。推荐的方法是详细看一下我整理的在实际案例中遇到问题的解决方法,然后再略读实践案例的内容。
确定最终付款交易时间和订单确定时间
首先根据订单编号做分组,因为同一个编号订单会有多次业务操作(例如下单、付款、发货),会在Binlog日志中形成多条同一订单编号的订单流水记录。使用MAX(dts_paytime)获取同一编号的最后一次操作数据库最终付款交易时间。
CREATE VIEW new_paytime AS
SELECT
dts_ordercodeofsys,
MAX(dts_paytime) AS dts_paytime
FROM orders_real
GROUP BY dts_ordercodeofsys
MIN(gmt_create) gmt_create,-- ‘创建时间’
MAX(gmt_modified) gmt_modified,-- ‘修改时间’
MIN(gmt_create)是指的订单的第一笔订单的创建时间,MAX(gmt_modified)是指的最后一比订单的时间。根据订单的业务逻辑我们可以用MAX和MIN来取相应的值。
如何判断有效订单
数据库日志会获取所有的数据记录的变更,而每个订单是有状态的。如列表所示:
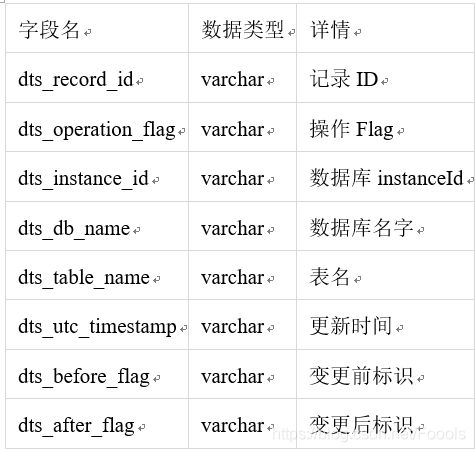
dts_record_id: 这条增量日志的唯一标识,唯一递增。如果变更类型为 update,那么增量更新会被拆分成 2 条,一条 Insert,一条 Delete。这两条记录具有相同的 record_id。
dts_instance_id: 这条增量日志所对应的数据库的 server id。
dts_db_name: 这条增量更新日志更新的表所在的数据库库名。
dts_table_name:这条增量更新日志更新的表。
dts_operation_flag: 标示这条增量日志的操作类型。取值包括:
I : insert 操作
D : delete 操作
U : update 操作
dts_utc_timestamp: 这条增量日志的操作时间戳,为这个更新操作记录 binlog 的时间戳。这个时间戳为 UTC 时间。
dts_before_flag: 表示这条增量日志后面带的各个 column 值是否更新前的值。取值包括:Y 和 N。当后面的 column 为更新前的值时,dts_before_flag=Y, 当后面的 column 值为更新后的值时,dts_before_flag=N.
dts_after_flag:表示这条增量日志后面带的各个 column 值是否更新后的值。取值包括:Y 和 N。 当后面的 column 为更新前的值时,dts_after_flag=N,当后面的 column 值为更新后的值时,dts_after_flag=Y.
对于不同的操作类型,增量日志中的 dts_before_flag 和 dts_after_flag 定义如下:
- 操作类型为:insert
当操作类型为 insert 时,后面的所有 column 值为新插入的记录值,即为更新后的值。所以 before_flag=N, after_flag=Y
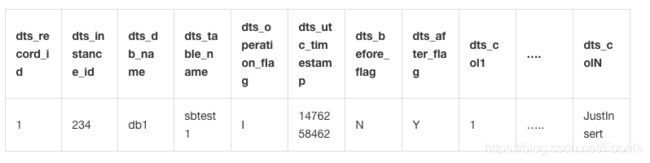
2. 操作类型为:update
当操作类型为 update 时,会将 update 操作拆为 2 条增量日志。这两条增量日志的 dts_record_id ,dts_operation_flag 及 dts_utc_timestamp 相同。
第一条日志记录了更新前的值,所以 dts_before_flag=Y, dts_after_flag=N
第二条日志记录了更新后的值,所以 dts_before_flag=N, dts_after_flag=Y
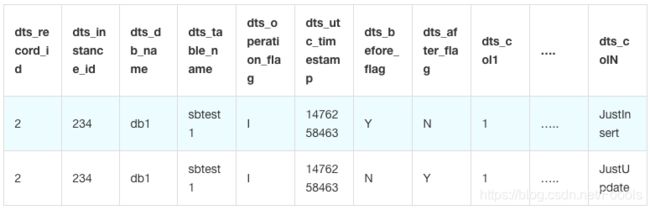
3. 操作类型为:delete
当操作类型为 delete 时,后面的所有 column 值为被删除的记录值,即为更新前的值。所以 dts_before_flag=Y, dts_after_flag=N

CREATE VIEW new_orderdetail AS
SELECT
dts_ordercodeofsys,
dts_skuname,
dts_skucode,
CASE WHEN dts_operation_flag = 'U'
AND dts_before_flag = 'Y'
AND dts_after_flag = 'N' THEN -1 * dts_quantity
WHEN dts_operation_flag = 'U'
AND dts_before_flag = 'N'
AND dts_after_flag = 'Y' THEN dts_quantity
WHEN dts_operation_flag = 'D' THEN -1 * dts_quantity
ELSE dts_quantity
END AS dts_quantity
FROM
orderdetail_real
怎么判断是有效交易订单呢?
首先是要满足dts_operation_flag=U 或者 dts_operation_flag=I,
然后dts_before_flag代表的是变更前订单状态,dts_after_flag是变更后订单状态;
所以有效交易订单为:
dts_operation_flag = 'U'
AND dts_before_flag = 'N'
AND dts_after_flag = 'Y' THEN dts_quantity
为什么THEN -1 * dts_quantity呢?
订单的取消或者是交易没有成功在总的销量里也会记录;为了保证总销量的正确性,所以把没有成交的订单数量设为负数在计算总的销量会减去这个数量。
点击次数作为PV、对客户的IP去重作为UV
count(client_ip) as pv --客户端的IP
,count(distinct client_ip) as uv--客户端去重
怎么解决数据倾斜?
假如用户的ID数据非常大,根据用户ID进行分组计算可能会造成机器热点从而导致数据倾斜,计算性能会很差!
解决方案:
mod(HASH_CODE(`a`.buyer_id),4096) hash_id
使用HASH_CODE这个离散函数来分离数据热点,接下来使用MOD函数对哈希值进行分组操作,这样做的好处是规范每个节点数据的数量避免大量数据的堆积导致数据倾斜(4096指的是分组的数量,可以根据数据的大小进行分组操作)。关于HASH_CODE的详情语法,请参考:流计算内置函数
滚动窗口 全站总人数及走势
我们使用每分钟一个窗口统计全站观看人数走势,走势最近的一分钟计算结果就是当前总人数。
CREATE VIEW view_app_total_visit_1min AS
SELECT
CAST(TUMBLE_START(app_ts, INTERVAL '60' SECOND) as VARCHAR) as app_ts,
COUNT(DISTINCT userid) as app_total_user_cnt
FROM
view_app_heartbeat_stream
GROUP BY
TUMBLE(app_ts, INTERVAL '60' SECOND);
热门直播房间排行
统计热门直播实际上为首页推荐用户使用,我们把热门的房间放在首页推广能够获取更多流量和点击。
CREATE VIEW view_app_room_visit_top10 AS
SELECT
app_ts,
room_id,
app_room_user_cnt,
rangking
FROM
(
SELECT
app_ts,
room_id,
app_room_user_cnt,
ROW_NUMBER() OVER (PARTITION BY 1 ORDER BY app_room_user_cnt desc) AS ranking
FROM
view_app_room_visit_1min
) WHERE ranking <= 10;
1.ROW_NUMBER()
定义:ROW_NUMBER()函数作用就是将select查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询,
比如查询前10个 查询10-100个学生。
实例:
1.1对学生成绩排序
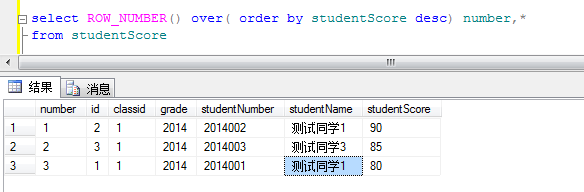
这里number就是每个学生的序号 根据studentScore(分数)进行desc倒序
1.2获取第二个同学的成绩信息
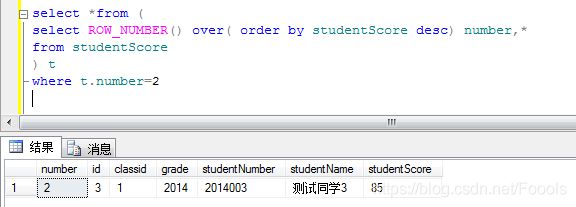
这里用到的思想就是 分页查询的思想 在原sql外再套一层select
where t.number>=1 and t.number<=10 是不是就是获取前十个学生的成绩信息纳。
去重操作
在订单表和退货表中可能会存在大量重复的数据比如商品ID、商品名称等,我们用MIN函数是为了只取第一次来的参数值,从而过滤掉其他的信息,然后再通过订单号和支付状态做分组取出我们需要的商品ID、商品名称等。
CREATE VIEW filter_hxhb_dwd_tb_trd_and_rfd_pay_ri_distinct AS
SELECT
biz_order_id biz_order_id,
pay_status pay_status,
MIN(auction_id) auction_id,
MIN(auction_title) auction_title,
MIN(buyer_id) buyer_id,
MIN(buyer_nick) buyer_nick,
MIN(pay_time) pay_time,
MIN(gmt_create) gmt_create,
MIN(gmt_modified) gmt_modified,
MIN(biz_type) biz_type,
MIN(attributes) attributes,
MIN(div_idx_actual_total_fee) div_idx_actual_total_fee
FROM
dwd_tb_trd_and_rfd_pay_ri
GROUP BY biz_order_id ,pay_status;
流计算回撤统计问题
Blink使用State在内存或者外部存储设备中对数据进行统计处理,当上游数据源需要对某些特定键值的数据做更新时,Blink会主动给下游下发一个删除消息从而“撤回”之前的那条消息,并用最新下发的消息对表做更新操作。
这样的机制在代码端实现也非常简单,只需要在数据源取最后一条数据然后按照相关维度groupBy即可:
select
coleasce(substr(plan_tms_collect_time,1,12),'3000-01-01') as plan_tms_collect_time,
count(mail_no)
from(
select mail_no,
stringLast(plan_tms_collect_time) as plan_tms_collect_time
from xx_xx_xx_xx
group by mail_no )t
group by substr(plan_tms_collect_time,1,12)
;
对订单号做groupby,然后仅仅取最后一条数据,这本质上不是撤回了之前的消息,而是只取最新的消息,来实现一种类似于去重的操作。
另外,在日常场景下,一键TT也可以实现类似的功能,设置主键之后,读取的TDDL MYSQL中的binlog,如果有数据的更新,TT就可以帮我们实现retraction的操作。
Retract源码:
def retract(acc: CountAccumulator, value: Any): Unit = {
if (value != null) {
acc.f0 -= 1L //acc.f0 存储记数
}
}