垃圾邮件分类的各种尝试(深度学习篇)【附代码】
垃圾邮件分类的各种尝试(深度学习篇)
文章目录
-
- 垃圾邮件分类的各种尝试(深度学习篇)
-
- 数据集格式
- 清洗数据集
- 使用深度学习的方法
-
- GloVe + LSTM
- 1. 读取数据
- 2. 加载GloVe词向量
- 3. 搭建网络整体结构
- 4. 设置训练参数
- 5. 训练模型并验证
- 6. 总结
上一篇博客主要介绍了利用机器学习的方法进行垃圾邮件分类,主要使用的方法有:朴素贝叶斯、SVM、逻辑回归、RF、XGBoost、LightGBM。
垃圾邮件分类的各种尝试(机器学习篇)
如果对上一篇博客介绍的方法已经掌握,那这一篇博客将打开新的世界。本篇博客将采用深度学习的方法来解决垃圾邮件分类问题。
深度学习方法:GloVe+LSTM(也可以将LSTM改为GRU或者CNN)
开源代码地址(欢迎star~):https://github.com/ljx02/Spam_Email_Classificaton
数据集下载链接:由于数据较小,暂时也放到了Git项目中
利用深度学习来解决问题的思路和上一篇介绍的思路是一样的,区别在于选择模型的时候,不光要选择合适的模型,还要搭建模型,配置模型,选择合适的网络结构进行训练。相比较机器学习有丰富的库资源,深度学习会显得复杂一些。
思路是这样的:
- 读取文本数据,先查看数据质量,可以先清洗一波数据(会有奇效)
- 特征工程,分析数据并发现特征,对特征进行向量化(需要大量经验)
- 选择网络结构,根据数据集结构和特点,选择合适的网络结构(需要大量经验判断)
- 训练模型并测试,通过不断调整超参数,来使模型达到最优(内部知识+大量经验)
- 预测结果
(可以看出,知识+经验是深度学习领域的利器~~)
数据集格式
总的数据集一共有4458条数据,将按照8:2进行划分训练集和验证集。通过分析发现,其中pam的数量有3866条,占数据集的大多数,可以考虑不平衡样本采样进行训练。
数据集的格式如图所示,有三列分别是ID,Label(pam、spam),Email

清洗数据集
具体操作流程可以参考我的上一篇文章垃圾邮件分类的各种尝试(机器学习篇)。主要的清洗包括:去掉停用词、去掉URL、去掉HTML标签、去掉特殊符号、去掉表情符号、去掉长重复字、将缩写补全、去掉单字、提取词干等等。这部分代码也几乎是一样的,可以去我的GitHub查看。
使用深度学习的方法
GloVe + LSTM
环境要求:python3.6 、TensorFlow1.14.0、Keras=2.2.4
1. 读取数据
由于数据量不是很大,还是选择了在训练集上进行分割,按8:2进行分割。
train = pd.read_csv("../data/train.csv", encoding='utf-8')
# 后期清洗完数据后,会将训练集分为训练集、验证集、测试集
train_data = tweet_pad[:3000]
test_data = tweet_pad[3000:]
# 利用train_test_split函数进行拆分,需要引入
# from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data, train[:3000]['Label'].values, test_size=0.2)
2. 加载GloVe词向量
GloVe词向量是基于共现矩阵的,所以GloVe会考虑全局特征。相比Word2Vec考虑上下文来看,似乎效果会更好一点,但实际上相差不大:D
GloVe的下载链接:http://nlp.stanford.edu/data/glove.6B.zip
还有42B,300d等更大维度更大的词向量可供下载:https://nlp.stanford.edu/projects/glove/ 但是训练时间就会~~~慎重
# 加载glove词向量
embedding_dict = {
}
with open("../glove/glove.6B.100d.txt", 'r', encoding='utf-8')as f:
for line in f:
values = line.split()
word = values[0]
vectors = np.asarray(values[1:], 'float32')
embedding_dict[word] = vectors
3. 搭建网络整体结构
为了简单易操作,采用顺序方式Sequential来搭建模型。利用Sequential搭建模型的优点是便捷,但是受限于网络类型,不支持自定义网络层。如果后续想自己定义网络层,还是推荐函数式建模。更高级的可以使用子类的方式建模~
实现简单的LSTM网络:
# 构建模型
model = Sequential()
embedding = Embedding(num_words, 100, embeddings_initializer=Constant(embedding_matrix),
input_length=MAX_LEN, trainable=False)
model.add(embedding)
model.add(SpatialDropout1D(0.2))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
4. 设置训练参数
设置训练参数有时也会带来奇效,例子中的参数设置来源于灵感~
由于参数较少,我就直接写出来(包括:Adam(lr=3e-4))
5. 训练模型并验证
训练模型的时候要注意,由于使用深度学习框架进行训练,所以输入的数据需要经过预处理,这里的预处理指分词、填充、编码。
# 分词 + 填充
MAX_LEN = 50 # 输入每句话的长度,少的填充,多的截断。
tokenizer_obj = Tokenizer()
tokenizer_obj.fit_on_texts(corpus) # 输入为两层列表格式[[...],[...],..]
sequences = tokenizer_obj.texts_to_sequences(corpus) # 返回序列化的数据格式
# 填充序列,大于50的会被截断,小于50的会填充补0,truncating表示截断,padding表示填充
tweet_pad = pad_sequences(sequences, maxlen=MAX_LEN, truncating='post', padding='post')
编码,需要生成编码矩阵。
word_index = tokenizer_obj.word_index # index从1开始,需要注意
print('Number of unique words:', len(word_index))
num_words = len(word_index) + 1 # 添加0行,index从1开始
embedding_matrix = np.zeros((num_words, 100))
# 生成编码矩阵,数据集中出现过的每一个单词对应一行,对应的是词向量
for word, i in tqdm(word_index.items()):
if i < num_words:
emb_vec = embedding_dict.get(word)
if emb_vec is not None:
# 生成编码矩阵,用于Embedding层的初始化操作
embedding_matrix[i] = emb_vec
训练模型,使用以下三个方法即可:
- model.fit()
- model.evaluate()
- model.predict()
具体使用可以参考我的GitHub:https://github.com/ljx02/Spam_Email_Classificaton
模型的结构如下图所示:
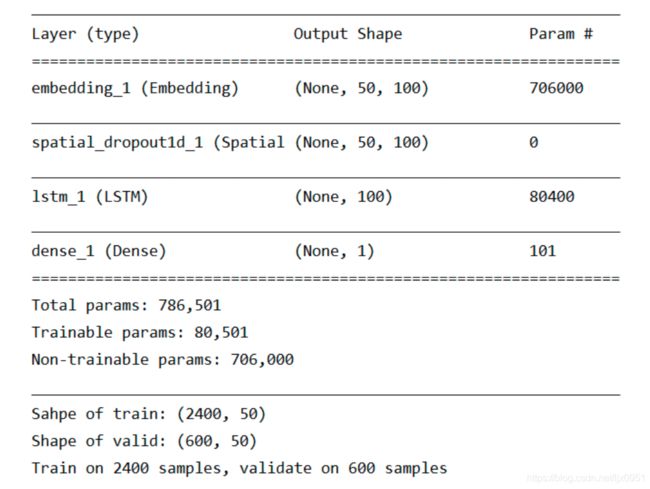
实验结果如下(数据量较小,得分偏高点:)

6. 总结
通过使用机器学习和深度学习的方法来完成垃圾邮件的分类任务,对文本数据的处理有了初步的理解。总体感觉文本类任务,首要任务就是分析特征,去掉干扰词和特征;其次将文本信息向量化,这里可以考虑的词向量有GloVe、Word2vec、FastTest等;最后就是使用合理的训练方法来拟合数据,可以是机器学习方法,也可以是深度学习方法,各有利弊吧,往往数据量大的任务可能采取深度学习的方法会好一点。
同样,在这里也提出一些后续可以改进的地方:
- 改变词向量
- 添加更深更复杂的网络
- 融合多个模型的预测结果
- 调整训练的超参数