爬虫(17)多线程练习 图片爬取案例
文章目录
- 爬虫(17)多线程练习 图片爬取案例
-
- 1. 多线程练习
- 2. 王者荣耀案例思路分析
-
- 2.1 第一种方法:直接在Previews里面找
- 2.2 第二种方法:通过json.cn网站解析
- 3. 获取数据
-
- 3.1 取出字典里的url
- 3.2 用parse.unquote()方法解析url
- 3.3 修改url得到非封面大图地址
- 3.4 定义一个函数来获取不同规格图片的url
- 3.5 获取图片名字
- 3.6 新键文件夹来存储图片(os模块的用法)
- 3.7 爬取图片
-
- 3.7.1另一种方法
- 3.7.2 完整代码
- 4. 多线程方式爬取图片
爬虫(17)多线程练习 图片爬取案例
1. 多线程练习
我们对多线程的特点进行一下解释:
进程:系统中正在运行的应用程序。
单核的cpu一次只能执行一个进程,其他的进程处于非运行状态。多软件打开的时候,cpu在快速切换,由于速度之快,我们感受不到切换。
多核的cpu可以同时执行多个进程。
线程:进程中包含的执行单元。
一个进程可以包含多个线程。Python中一次只能执行一个线程。其他的都在阻塞和等待。原因就是有锁,防止多个线程竞争资源。
下面我们用普通方式和多线程方式来爬取王者荣耀高清图片来练习多线程爬虫。
2. 王者荣耀案例思路分析
我们的需求是要爬取王者荣耀的高清图片。网址在这里:https://pvp.qq.com/web201605/wallpaper.shtml
打开网页,下拉找到高清壁纸栏目,我们看到图片有三种规格:
我们要的是最后一个规格:1920×1200的高清图片。思路是只要找到图片对应的url就可以了。我们右键检查:

我们复制一下里面的url:http://shp.qpic.cn/ishow/2735011317/1610529849_84828260_19594_sProdImgNo_1.jpg/0
在网页上粘贴,回车查找。
得到的是一个小的封面图片。我们往下看有个ul标签,点击打开这个标签:

点开后发现有很多li标签,其中有三个li标签对应三个图片的规格:

我们点开其中第一个标签里面的href里的url发现是一个图片,后面每个li标签里的都是,规格不同。
下面我们分析一下整个页面的总标签是谁:

当我的鼠标放在一个id = "Work_List_Container_267733"的div标签上时,发现高清壁纸板块的所以图片被选中。那就是这个了。后面我的鼠标滑动到class = "p_newhero_item"的标签上的时候,其中一个图片被选中,那么这个标签时每张图片的位置。而其中的li标签是 每张图片的不同规格:
下面我们查看一下总标签的id在不在网页源码里面:右键查看网页源码,Ctrl+F,在跳出的搜索框里粘贴id:

发先这个div标签里并没有url或者更多的信息。点击下一个,
也是这样。在下一个

下一个:

四个全部展开,没有我们要的信息。这就说明,这些数据并不在网页源码种,而是动态加载出来的。我们的办法有两个,一个是用selenium,一个是分析数据接口。今天我们分析数据接口。
点network,清空,然后刷新一下。点XHR看看加载内容:
通过标签的名字我们可以猜一猜:点一下herolist.json

点response看一下响应的数据:

在response收索框里输入jpg看看有没有这个文件。

我们只能去All里面去找了,后来找到了在一个worklist的元素里,有两个,内容是一样的,只不过时间戳不同。

我们点开下面的,然后点Response在出现的页面里Ctrl+F,在输入框里输入jpg,看到有180个jpg文件。那就是在这里了。

2.1 第一种方法:直接在Previews里面找
点击Preview:

复制最后一个高清的地址,然后到网页地址栏复制,回车发现并不能打开,这是因为这个地址是被编码过后的地址,需要我们解码一下:
from urllib import parse
img = parse.unquote('http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652314%5F84828260%5F14368%5FsProdImgNo%5F8%2Ejpg%2F200')
print(img)
输出:
D:\Python38\python.exe D:/work/爬虫/Day15/my_code/get_picture.py
http://shp.qpic.cn/ishow/2735012617/1611652314_84828260_14368_sProdImgNo_8.jpg/200
Process finished with exit code 0
把这个地址复制到网页地址栏里再试一下:
发现是封面小图。再次检查源码:
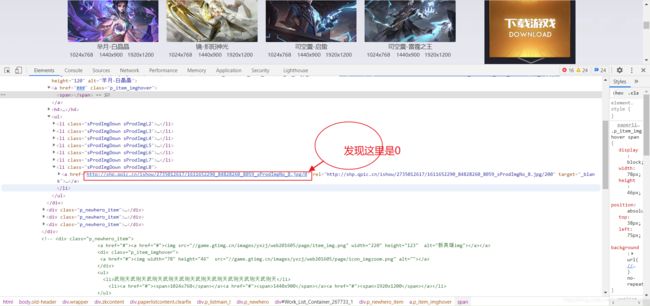
那我们把这里的url后面的200也改成0试试:

回车:
大图出现!鲜花在哪里?
2.2 第二种方法:通过json.cn网站解析
我们可以在Response里面复制其中的响应内容,然后打开json.cn网站,在左边输入框中粘贴进去:

打开json.cn网站:

发现报错了,不能正确解析,显示“无效的配置长度”。这是因为地址里有这样一段需要删除:

这是因为请求地址里有一段:
jsoncallback=jQuery的数据,原因是jQuery在解析jsoncallback时会返回jsoncallback的字符串,该字符串会被jsoncallback方法会所执行,执行时产生的数据会出现无法识别的问题。json.cn网站解析时就会报错。解决方法就是删除掉上图所示的数据。然后就能正确解析了。

后面的操作类似,就不再赘述了。以后遇到类似的问题都这样进行处理就可以了。
3. 获取数据
现在我们写代码来获取数据:
import requests
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
# 如果res.text 是个json类型的字符串
print(type(res.json()),res.json())
if __name__ == '__main__':
main()
执行结果:
{'iBltFlag': '0', 'iCache': '1', 'iRet': '0', 'iTotalLines': '468', 'iTotalPages': '24', 'sMsg': 'Successful', 'List': [{'dtInputDT': '2021%2D01%2D26%2017%3A11%3A54', 'iBallotNum': '0', 'iClickNum': '0', 'iDownloadNum': '0', 'iNonsupportNum': '0', 'iProdId': '1669', 'iStatus': '1', 'sProdImgNo_1': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F1%2Ejpg%2F200', 'sProdImgNo_2': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F2%2Ejpg%2F200', 'sProdImgNo_3': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F3%2Ejpg%2F200', 'sProdImgNo_4': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F4%2Ejpg%2F200', 'sProdImgNo_5': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F5%2Ejpg%2F200', 'sProdImgNo_6': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F6%2Ejpg%2F200', 'sProdImgNo_7': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652314%5F84828260%5F14368%5FsProdImgNo%5F7%2Ejpg%2F200', 'sProdImgNo_8': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652314%5F84828260%5F14368%5FsProdImgNo%5F8%2Ejpg%2F200', 'sProdName': '%E8%8A%88%E6%9C%88%2D%E7%99%BD%E6%99%B6%E6%99%B6', 'sThumbURL': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F1%2Ejpg%2F200'}, {'dtInputDT': '2021%2D01%2D20%2015%3A15%3A41', 'iBallotNum': '0', 'iClickNum': '0', 'iDownloadNum': '0', 'iNonsupportNum': '0', 'iProdId': '1667', 'iStatus': '1', 'sProdImgNo_1': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012015%2F1611126939%5F84828260%5F23512%5FsProdImgNo%5F1%2Ejpg%2F200', 'sProdImgNo_2': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012015%2F1611126939%5F84828260%5F23512%5FsProdImgNo%5F2%2Ejpg%2F200', 'sProdImgNo_3': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012015%2F1611126939%5F84828260%5F23512%5FsProd'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585084%5F84828260%5F20640%5FsProdImgNo%5F7%2Ejpg%2F200', 'sProdImgNo_8': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585084%5F84828260%5F20640%5FsProdImgNo%5F8%2Ejpg%2F200', 'sProdName': '%E6%BE%9CCG%E3%80%8A%E7%9B%AE%E6%A0%87%E3%80%8B', 'sThumbURL': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585083%5F84828260%5F20640%5FsProdImgNo%5F1%2Ejpg%2F200'}, {'dtInputDT': '2020%2D12%2D10%2015%3A24%3A13', 'iBallotNum': '0', 'iClickNum': '0', 'iDownloadNum': '0', 'iNonsupportNum': '0', 'iProdId': '1643', 'iStatus': '1', 'sProdImgNo_1': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585051%5F84828260%5F6762%5FsProdImgNo%5F1%2Ejpg%2F200', 'sProdImgNo_2': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F2%2Ejpg%2F200', 'sProdImgNo_3': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F3%2Ejpg%2F200', 'sProdImgNo_4': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F4%2Ejpg%2F200', 'sProdImgNo_5': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F5%2Ejpg%2F200', 'sProdImgNo_6': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F6%2Ejpg%2F200', 'sProdImgNo_7': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F7%2Ejpg%2F200', 'sProdImgNo_8': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585052%5F84828260%5F6762%5FsProdImgNo%5F8%2Ejpg%2F200', 'sProdName': '%E6%BE%9CCG%E3%80%8A%E7%9B%AE%E6%A0%87%E3%80%8B', 'sThumbURL': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607585051%5F84828260%5F6762%5FsProdImgNo%5F1%2Ejpg%2F200'}, {'dtInputDT': '2020%2D12%2D10%2015%3A19%3A54', 'iBallotNum': '0', 'iClickNum': '0', 'iDownloadNum': '0', 'iNonsupportNum': '0', 'iProdId': '1642', 'iStatus': '1', 'sProdImgNo_1': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584793%5F84828260%5F11833%5FsProdImgNo%5F1%2Ejpg%2F200', 'sProdImgNo_2': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584793%5F84828260%5F11833%5FsProdImgNo%5F2%2Ejpg%2F200', 'sProdImgNo_3': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584793%5F84828260%5F11833%5FsProdImgNo%5F3%2Ejpg%2F200', 'sProdImgNo_4': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584793%5F84828260%5F11833%5FsProdImgNo%5F4%2Ejpg%2F200', 'sProdImgNo_5': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584794%5F84828260%5F11833%5FsProdImgNo%5F5%2Ejpg%2F200', 'sProdImgNo_6': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584794%5F84828260%5F11833%5FsProdImgNo%5F6%2Ejpg%2F200', 'sProdImgNo_7': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584794%5F84828260%5F11833%5FsProdImgNo%5F7%2Ejpg%2F200', 'sProdImgNo_8': 'http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735121015%2F1607584794%5F84828260%5F11833%5FsProdImgNo%5F8%2Ejpg%2F200', 'sProdName': '%E6%BE%9CCG%E3%80%8A%E7%9B%AE%E6%A0%87%E3%80%8B', 'sThumbURL':
# 结果太长,就删掉了。
res.json()是requests第三方库所提供的将json数据类型转换为字典的方法(所以不需要import json),json.loads(res.text)是python内置的模块,将json数据转换为字典。
3.1 取出字典里的url
我们观察打印结果,我们需要的数据在’List’这个键的值里。我们定义result来接收转换的字典。
import requests
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
res = requests.get(page_url,headers=headers)
result = res.json() # 我们定义result来接收转换的字典
datas = result['List'] # 取出'List'的所有值
for data in datas:
sProdImgNo_1 = data['sProdImgNo_1'] # 遍历datas取出'sProdImgNo_1'对应的值
print(sProdImgNo_1)
if __name__ == '__main__':
main()
结果:
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012617%2F1611652313%5F84828260%5F14368%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735012015%2F1611126939%5F84828260%5F23512%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735011317%2F1610529879%5F84828260%5F27040%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735011313%2F1610516936%5F84828260%5F3358%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735010815%2F1610092059%5F84828260%5F6125%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735010717%2F1610011288%5F84828260%5F7033%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735010717%2F1610011206%5F84828260%5F4846%5FsProdImgNo%5F1%2Ejpg%2F200
http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735010716%2F1610009926%5F84828260%5F15453%5FsProd# 结果太长,就删掉了。
一共20个结果。我们在上一个版块介绍了,这个url是无法直接被使用的。
3.2 用parse.unquote()方法解析url
需要用parse.unquote()方法来解析一下。所以需要导入from urllib import parse。
import requests
from urllib import parse
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
result = res.json()
datas = result['List']
j = 0
for data in datas:
sProdImgNo_1 = parse.unquote(data['sProdImgNo_1'])
print(sProdImgNo_1)
j += 1
print(j)
if __name__ == '__main__':
main()
结果
http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735012015/1611126939_84828260_23512_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735010815/1610092059_84828260_6125_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735010717/1610011288_84828260_7033_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735010717/1610011206_84828260_4846_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735010716/1610009926_84828260_15453_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735010617/1609926266_84828260_29925_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735010616/1609921831_84828260_4181_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735121517/1608023389_84828260_23287_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735121114/1607666908_84828260_6772_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735121015/1607585083_84828260_20640_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735121015/1607585051_84828260_6762_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735121015/1607584793_84828260_11833_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735120117/1606814546_84828260_690_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735112718/1606472113_84828260_13758_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735111110/1605060341_84828260_22810_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735102010/1603161871_84828260_28416_sProdImgNo_1.jpg/200
http://shp.qpic.cn/ishow/2735092717/1601197753_84828260_29701_sProdImgNo_1.jpg/200
20
这次得到了能用的url,结果有20个。
3.3 修改url得到非封面大图地址
但这个地址得到的都是封面小图片,我们还需要将每个地址后面的200换成0
import requests
from urllib import parse
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
result = res.json() # 我们定义result来接收转换的字典
datas = result['List'] # 取出'List'的所有值
j = 0
for data in datas:
# 用parse.unquote()解析一下得到的url并处理一下将'200'换成'0'
sProdImgNo_1 = parse.unquote(data['sProdImgNo_1']) .replace('200','0')
print(sProdImgNo_1)
j += 1
print(j)
if __name__ == '__main__':
main()
结果:
http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735012015/1611126939_84828260_23512_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735010815/1610092059_84828260_6125_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735010717/1610011288_84828260_7033_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735010717/1610011206_84828260_4846_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735010716/1610009926_84828260_15453_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735010617/1609926266_84828260_29925_sProdImgNo_1.jpg/0
http://shp.qpic.cn/ishow/2735010616/1609921831_84828260_4181_sProdImgNo_1.jpg/0
... ...
结果是可以使用的了。不过第一个地址里无论结尾是0还是200都是小图。

3.4 定义一个函数来获取不同规格图片的url
现在我们要拿到所有图不同规格的图片。我们分析过,不同的规格取决于sProdImgNo_1这个变量尾部的数字,我们可以定义一个函数来解决这个问题:
import requests
from urllib import parse
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
# 定义一个函数来获取不同规格图片的url
def extract_images(data): # 传入的参数定义为data后面好对应
# 定义一个空列表来装结果
image_urls = []
for x in range(1,9):
image_url = parse.unquote(data['sProdImgNo_%d'%x]).replace('200', '0') # 处理的结果url尾部替换成0
image_urls.append(image_url) # 把解析处理过的url添加进列表
return image_urls # 把列表当作结果返回
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
# 如果res.text 是个json类型的字符串
# print(type(res.json()),res.json()) # res.json()是requests第三方库所提供的将json数据类型转换为字典的方法,所以不需要import json,json.loads(res.text)是python内置的模块,将json数据转换为字典。
result = res.json() # 我们定义result来接收转换的字典
# print(result)
datas = result['List'] # 取出'List'的所有值
for data in datas:
# sProdImgNo_1 = parse.unquote(data['sProdImgNo_1']) .replace('200','0')
image_urls = extract_images(data) # 直接用函数来接收遍历产生的data
if __name__ == '__main__':
main()
3.5 获取图片名字
现在我们需要得到每个图片的名字和我们获得的图片对应。名字就是’sProdName’: ‘%E5%8F%B8%E7%A9%BA%E9%9C%87%2D%E5%90%AF%E8%9B%B0’,不过仍需要像解析url一样解析一下。
import requests
from urllib import parse
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
# 定义一个函数来获取不同规格图片的url
def extract_images(data): # 传入的参数定义为data后面好对应
# 定义一个空列表来装结果
image_urls = []
for x in range(1,9):
image_url = parse.unquote(data['sProdImgNo_%d'%x]).replace('200', '0')
image_urls.append(image_url) # 把解析处理过的url添加进列表
return image_urls # 把列表当作结果返回
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
# 如果res.text 是个json类型的字符串
# print(type(res.json()),res.json()) # res.json()是requests第三方库所提供的将json数据类型转换为字典的方法,所以不需要import json,json.loads(res.text)是python内置的模块,将json数据转换为字典。
result = res.json() # 我们定义result来接收转换的字典
# print(result)
datas = result['List'] # 取出'List'的所有值
for data in datas:
# sProdImgNo_1 = parse.unquote(data['sProdImgNo_1']) .replace('200','0')
image_urls = extract_images(data) # 直接用函数来接收遍历产生的data
name = parse.unquote(data['sProdName']) # 获取并解析图片名字
# 打印查看一下结果
print(name)
print(image_urls)
print('=*'*60)
if __name__ == '__main__':
main()
得到的结果是:
芈月-白晶晶
['http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_1.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_2.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_3.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_4.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_5.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652313_84828260_14368_sProdImgNo_6.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652314_84828260_14368_sProdImgNo_7.jpg/0', 'http://shp.qpic.cn/ishow/2735012617/1611652314_84828260_14368_sProdImgNo_8.jpg/0']
=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*
镜-炽阳神光
['http://shp.qpic.cn/ishow/2735012015/1611126939_84828260_23512_sProdImgNo_1.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126939_84828260_23512_sProdImgNo_2.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126939_84828260_23512_sProdImgNo_3.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126939_84828260_23512_sProdImgNo_4.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126940_84828260_23512_sProdImgNo_5.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126940_84828260_23512_sProdImgNo_6.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126940_84828260_23512_sProdImgNo_7.jpg/0', 'http://shp.qpic.cn/ishow/2735012015/1611126940_84828260_23512_sProdImgNo_8.jpg/0']
=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*
司空震-启蛰
['http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_1.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_2.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_3.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_4.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529879_84828260_27040_sProdImgNo_5.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529880_84828260_27040_sProdImgNo_6.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529880_84828260_27040_sProdImgNo_7.jpg/0', 'http://shp.qpic.cn/ishow/2735011317/1610529880_84828260_27040_sProdImgNo_8.jpg/0']
=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*
司空震-雷霆之王
['http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_1.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_2.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_3.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_4.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_5.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516936_84828260_3358_sProdImgNo_6.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516937_84828260_3358_sProdImgNo_7.jpg/0', 'http://shp.qpic.cn/ishow/2735011313/1610516937_84828260_3358_sProdImgNo_8.jpg/0']
=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*=*
# 结果太长删掉了
每个名字下面有8套url。
3.6 新键文件夹来存储图片(os模块的用法)
下面我们要把图片的名字作为文件夹的名字新键文件夹来存储图片。这用到一个python内置的os模块。
下面我们举例说明os模块的用法:
import os
os.mkdir('我的文件') # 创建文件夹的方法,第一个参数是文件夹名,这里我以'我的文件'命名;运行有就会在程序所在的文件夹里创建文件夹'我的文件'

文明在E盘中的一个叫imge的文件夹中新建“我的文件夹2”
import os
# os.mkdir('我的文件') # 创建文件夹的方法,第一个参数是文件夹名,这里我以'我的文件'命名;运行有就会在程序所在的文件夹里创建文件夹'我的文件'
dirpath = os.path.join('E:\image','我的文件夹2') # 第一个参数是你要新建文件夹所在的文件夹的路径,第二个参数是新键的文件夹名,返回值是新键文件夹的路径
print(dirpath)
os.mkdir(dirpath) # 在E:\image\我的文件夹2这个路径中新建文件夹
打印结果是os.path.join(‘E:\image’,‘我的文件夹2’)的返回值,用dirpath 来接收的
E:\image\我的文件夹2
是新键文件夹的路径,我们把这个路径作为参数传入os.mkdir()方法,结果就照这个路径创建了这个文件夹
现在我们应用这个知识点来为获得的图片新建文件夹:
import requests
from urllib import parse
import os
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
# 定义一个函数来获取不同规格图片的url
def extract_images(data): # 传入的参数定义为data后面好对应
# 定义一个空列表来装结果
image_urls = []
for x in range(1,9):
image_url = parse.unquote(data['sProdImgNo_%d'%x]).replace('200', '0')
image_urls.append(image_url) # 把解析处理过的url添加进列表
return image_urls # 把列表当作结果返回
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
# 如果res.text 是个json类型的字符串
# print(type(res.json()),res.json()) # res.json()是requests第三方库所提供的将json数据类型转换为字典的方法,所以不需要import json,json.loads(res.text)是python内置的模块,将json数据转换为字典。
result = res.json() # 我们定义result来接收转换的字典
# print(result)
datas = result['List'] # 取出'List'的所有值
for data in datas:
# sProdImgNo_1 = parse.unquote(data['sProdImgNo_1']) .replace('200','0')
image_urls = extract_images(data) # 直接用函数来接收遍历产生的data
name = parse.unquote(data['sProdName']) # 获取并解析图片名字
# 在E盘里新建文件夹来存储图片,文件夹以name命名
dirpath = os.path.join('E:\image',name) # 获得新建文件夹的路径
os.mkdir(dirpath) # 将路径传入os.mkdir()方法
if __name__ == '__main__':
main()
3.7 爬取图片
下一步就是爬取图片了:
import requests
from urllib import parse
import os
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
# 定义一个函数来获取不同规格图片的url
def extract_images(data): # 传入的参数定义为data后面好对应
# 定义一个空列表来装结果
image_urls = []
for x in range(1,9):
image_url = parse.unquote(data['sProdImgNo_%d'%x]).replace('200', '0')
image_urls.append(image_url) # 把解析处理过的url添加进列表
return image_urls # 把列表当作结果返回
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
# 如果res.text 是个json类型的字符串
# print(type(res.json()),res.json()) # res.json()是requests第三方库所提供的将json数据类型转换为字典的方法,所以不需要import json,json.loads(res.text)是python内置的模块,将json数据转换为字典。
result = res.json() # 我们定义result来接收转换的字典
# print(result)
datas = result['List'] # 取出'List'的所有值
k = 0
for data in datas:
k += 1 # 用来区分重名的文件夹
# sProdImgNo_1 = parse.unquote(data['sProdImgNo_1']) .replace('200','0')
image_urls = extract_images(data) # 直接用函数来接收遍历产生的data
name = parse.unquote(data['sProdName']) # 获取并解析图片名字
# 在E盘里新建文件夹来存储图片,文件夹以name命名
dirpath = os.path.join('E:\image',name+str(k))
os.mkdir(dirpath)
for index,image_url in enumerate(image_urls):
res = requests.get(image_url,headers=headers)
with open(dirpath+'\%d.jpg'%(index+1),'wb') as f:
f.write(res.content)
print('%s下载完成'%(name+str(k)))
if __name__ == '__main__':
main()
执行结果
芈月-白晶晶1下载完成
镜-炽阳神光2下载完成
司空震-启蛰3下载完成
司空震-雷霆之王4下载完成
孙悟空-零号·雷霆5下载完成
元歌-云间偶戏6下载完成
亚瑟-潮玩骑士王7下载完成
狄仁杰-万华元夜8下载完成
虞姬-启明星使9下载完成
孙悟空-零号·赤焰10下载完成
孙膑-天狼运算者11下载完成
澜-孤猎12下载完成
澜CG《目标》13下载完成
澜CG《目标》14下载完成
澜CG《目标》15下载完成
云中君-纤云弄巧16下载完成
澜-鲨之猎刃17下载完成
鬼谷子-原初探秘者18下载完成
裴擒虎-李小龙19下载完成
小乔-天鹅之梦20下载完成
在E盘image文件夹里装满了20个图片文件夹

需要说明的是,在下载的时候发现有重名的文件夹,会报错文件夹已经存在无法创建。所以这里为了使文件夹不重名,就在遍历的时候添加一个变量k,让k累加,作为文件夹名的尾号,这样就解决问题了。
3.7.1另一种方法
我们也可以用另外一种请求方法,需要导入一个模块:
from urllib import request
request.urlretrieve(image_url,os.path.join(dirpath,'%d.jpg'%(index+1)))
上述代码里面的参数解释:
- 传入第一个参数是你所请求的url,第二个是fielder,或fielder path,就是我们下载的路径。
- 路径os.path.join(dirpath,’%d.jpg’%(index+1))里传入第一个我们的路径,第二个在这个路径里新建文件名
- index是从0开始的,我们加1作为图片文件名。
3.7.2 完整代码
完整代码:
import requests
from urllib import parse
import os
from urllib import request
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36','referer': 'https://pvp.qq.com/'}
# 定义一个函数来获取不同规格图片的url
def extract_images(data): # 传入的参数定义为data后面好对应
# 定义一个空列表来装结果
image_urls = []
for x in range(1,9):
image_url = parse.unquote(data['sProdImgNo_%d'%x]).replace('200', '0')
image_urls.append(image_url) # 把解析处理过的url添加进列表
return image_urls # 把列表当作结果返回
def main():
# 明确目标url
page_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1612141973825'
# 把url里这一段删除:&jsoncallback=jQuery171013413315924847624_1612141973463
res = requests.get(page_url,headers=headers)
# 如果res.text 是个json类型的字符串
# print(type(res.json()),res.json()) # res.json()是requests第三方库所提供的将json数据类型转换为字典的方法,所以不需要import json,json.loads(res.text)是python内置的模块,将json数据转换为字典。
result = res.json() # 我们定义result来接收转换的字典
# print(result)
datas = result['List'] # 取出'List'的所有值
os.mkdir('E:\image_1') # 在E盘创建一个新的文件夹
k = 0
for data in datas:
k += 1 # 用来区分重名的文件夹
# sProdImgNo_1 = parse.unquote(data['sProdImgNo_1']) .replace('200','0')
image_urls = extract_images(data) # 直接用函数来接收遍历产生的data
name = parse.unquote(data['sProdName']) # 获取并解析图片名字
# 在E盘里新建文件夹来存储图片,文件夹以name命名
dirpath = os.path.join('E:\image_1',name+str(k))
os.mkdir(dirpath)
for index,image_url in enumerate(image_urls):
# 传入第一个参数是你所请求的url,第二个是fielder,或fielder path,就是我们下载的路径。
# 路径os.path.join(dirpath,'%d.jpg'%(index+1))里传入第一个我们的路径,第二个在这个路径里新建文件名
# index是从0开始的,我们加1作为图片文件名
request.urlretrieve(image_url,os.path.join(dirpath,'%d.jpg'%(index+1)))
print('%s下载完成'%(name+str(k)))
if __name__ == '__main__':
main()
结果在我的E盘有了一个新的文件夹

里面装满了下载的图片:

4. 多线程方式爬取图片
我们创建两个队列,队列一存放每一页的url。定义一个生产者,从队列一当中去请求每一页的url地址。拿到response,解析每一页的url,获取每页图片的url以及名字name。创建一个队列二,存放图片的url以及图片的name。定义一个消费者,从队列二取出图片的url地址,发出请求,并下载图片。当然还有name。上升到多线程,程序的复杂度提高,页容易出现Bug。爬取速度变快,会给服务器带来压力,希望注意,道德爬取。