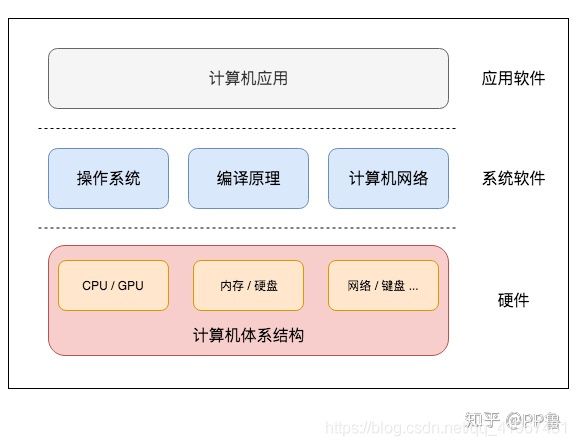
深度学习之GPU编程知识总结
概念解析
首先,我们先整理一下:平时在使用一些GPU加速算法是都是在Python环境下执行,但是一般的Python代码是没办法使用GPU加速的,因为GPU是更接近计算机底层的硬件,Python一类的高级语言是没办法直接和GPU沟通的。
然后就引出话题的重点:硬件的加速必须使用硬件语言。
查询Python+GPU关键字,除了TensorFlow,另外出镜率比较高的几个概念是:Numba、CUDA、PyCUDA、minpy。
所以如果要想使对Python和GPU加速相关知识了解更深入,必须了解一些计算机的底层知识。
一、计算机底层运行机制简单介绍
现代CPU一般使用缓存(Cache)来解决CPU读写主存慢的问题;使用多核来并行计算以加速程序运行。并行计算一般需要多线程技术,如何操作多线程对编程人员提出了挑战。
1. 计算机只能执行二进制代码
但凡具有一点计算机知识的人都应该知道,机算机是基于二进制运行的。计算机只有两个状态,开或关、真或假、1或0(其实就类似高级语言的BOOL类型),这主要是因为组成计算机的最基本原件是半导体,而半导体只能进行二进制计算。
所以奇妙的事情就在这里发生,不论是现在火热的Python、C/C++、AI和大数据等技术,甚至常见的存储形式如文本、音频、图像等,他们在计算机最底层都是以二进制形式存储、计算和传输的。所以,计算机底层设计师们的主要任务就是设计控制芯片的二进制代码。
2. 冯·诺依曼架构
1945年,天才科学家冯·诺依曼提出了一种计算机设计实现架构,奠定了现代计算机的理论基础。冯·诺依曼架构主要有几大部分:
|
冯·诺依曼架构 |

- 包含控制单元和逻辑运算单元的CPU
- 存储指令和数据的内存
- 输入和输出设备
3. CPU工作原理
CPU(Central Processing Unit),中文翻译为中央处理器,负责执行用户和操作系统下发的指令。CPU是计算机中最为核心的部分,经常被比作计算机的大脑。CPU只能接受01二进制语言,0和1用来控制高低电位。比如,一个加法运算,在x86处理器上的的二进制代码为:
01001000 00000001 11000011
这样一行代码被称为机器码,它执行了加法操作。除了这样的加法,CPU的电路还要实现很多其他指令,如存取内存数据,进行逻辑判断等。不同厂商的电路设计不同,在电路上所能进行的二进制码不同。某类CPU能支持一种指令集(instruction set architecture)。指令集相当于一种设计图纸,规定了一种CPU架构实现哪些指令。参照指令集,硬件开发人员只需要关心如何设计电路,软件开发人员只关心如何用01机器码实现软件功能。比较常见的指令集有x86、ARM、MIPS、SPARC、Power等。
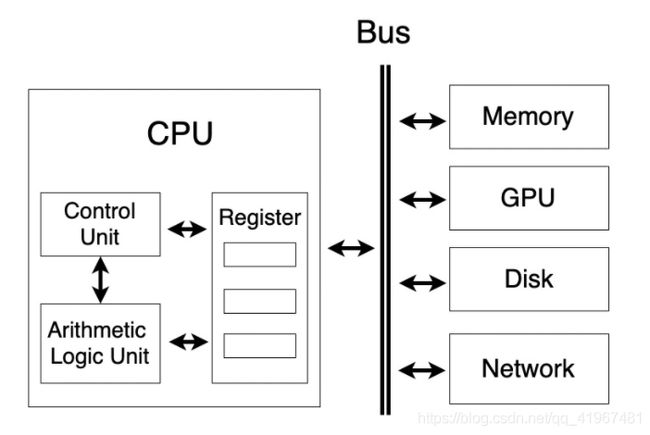
单核计算机系统示意图
一个单核CPU架构包括:
- Control Unit(CU)起协调管理功能。
- Arithmetic Logic Unit(ALU)接受控制单元的命令,负责进行加减乘与或非运算。所有数据都存放在寄存器(Register)里。
- 寄存器以极高的速度与CU和ALU交互,通常小于1纳秒。从寄存器的名字可以看出来,里面的数据是临时寄存的,这些数据和指令会被ALU和CU拿来立即进行计算。如果寄存器没有CPU想要的数据,CPU会去内存或硬盘中读取。
- CPU通过Bus(总线)读取内存或其他设备的数据。计算机中有多条总线。
所以,由上述概念我们可以总结得出,计算机执行一次运算只需要知道两个问题:1. 本次所执行的是哪个指令?2.该指令的执行对象是什么?
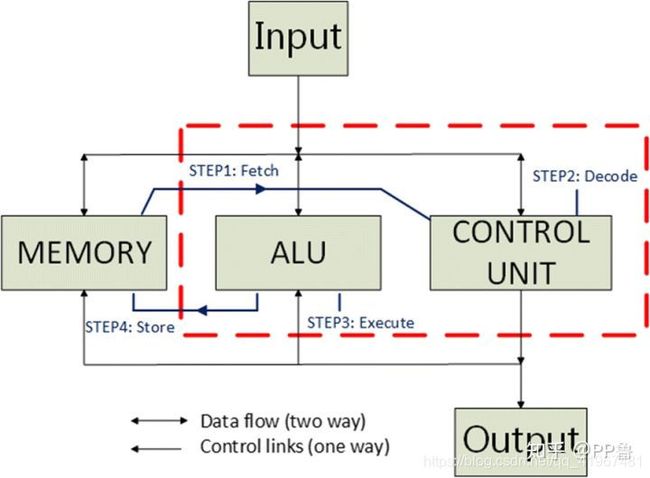
指令执行过程
因此,控制单元先取指令 Fetch,然后指令译码 Decode解析出要执行什么指令,并确认指令是对哪些数据(操作数 operand)进行操作,并将操作数从主存加载到寄存器中。ALU执行指令 Execute后结果写回 Store。
4. 存储与多核技术的诞生
随着技术的发展,计算机的速度瓶颈已经变成了超高速的CPU运算速度与落后的数据读取速度之间的矛盾。CPU计算速度在纳秒级别,但是CPU读取主存的速度竟有百纳秒,CPU进行完计算后,要闲置几十倍的时间,实在是巨大的浪费。为了解决这个问题,设计人员为CPU增加了很多中间缓存Cache。

存储金字塔
CPU的寄存器存取速度极快,但是造价成本太高,发热量大,不能被大量采用。通常,CPU的寄存器只有几KB。L1 Cache和L2 Cache一般设计在CPU上,访问延迟在几纳秒只几十纳秒内,主存的访问延迟在百纳秒内。速度越快,意味着成本越高。
当单个CPU主频超过一定范围后,CPU成本和散热成了很大的问题,主频很难突破10GHz。为了获得更快的计算速度和更好的性能,芯片设计者决定绕过主频,采用人海战术,在一块CPU中增加多个核心(Core)。
一个核心是一个可以运行指令的独立单元,它包含了前面所提到的ALU和寄存器,并配备L1和L2 Cache。多个核心共享L3 Cache。

多核与Cache L3
上图中是一个多核处理器的电路图,每个Core旁边的黑色圆圈分别为L1和L2 Cache。可以看到CPU中,各类Cache占用了很大的空间。

多处理器多核结构
高性能服务器通常可以支持多个处理器,提供更多计算核心。支持单个CPU的服务器被称为单路服务器,支持两个CPU的服务器被称为双路服务器,支持四个CPU的服务器被称为四路服务器。上图展示了Intel的四路架构,系统支持四个CPU,假如每块CPU内有8个核心,系统可对外提供32核计算能力。
5. 进程与线程
前面都是计算机硬件知识,而线程和进程则是操作系统控制这些硬件而创造的软件概念。
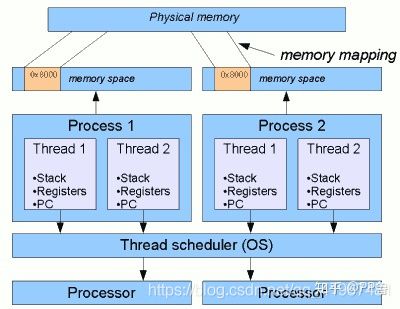
- 进程(Process)具有单独的计算资源,如内存空间。
- 线程(Thread)是进程的一个子集,一个进程默认启动一个线程,也可以通过多线程编程,启动多个线程,多个线程共享共享进程的资源。
在多核架构出现之前,CPU在某个特定时刻只能执行某个程序,无法并行。但前文提到,CPU处理速度是纳秒级,速度非常快,所以在单核时代,为了同时处理多项任务,CPU采用不停地在多个线程任务间切换的形式实现多线程。单个CPU每次切换不同的线程任务,会产生一些资源开销。
多核架构提供给用户多个可以独立计算的核心,这也意味着计算机可以同时并行执行多项任务,即并行计算(Parallel Computing)。列如:一个网页浏览器使用一个核渲染网页,另一个核缓存其他素材,第三个核下载背景音乐。
但是随着多核多线程架构出现,又引出另外一个问题:多线程安全问题。当多个核心都处理相同任务,极有可能使用同一块数据,就有可能出现数据读写的问题:例如,进行i = i + 1操作,如果两个线程短时间内都对变量i加一,变量应该被加了两次。
由于两个线程相隔时间太短,加上前面所说的缓存机制,计算的过程和临时结果还在寄存器和L1缓存,没来得及写到主存上。线程B读到还是较老的数据,这样就出现了数据不一致的情况。这种问题被称为线程安全问题。一般需要使用锁来处理线程安全问题。
二、编译型语言与解释型语言如何在计算机底层运行
前面说到,不同架构的CPU会适配一套指令集,而书写指令集的代码被称为机器语言或机器码。
很多时候我们使用计算机时都接触得到可执行文件(.exe文件),而可执行文件就是二进制机器语言的集合,可以被机器执行,得到我们想要的结果。
1. 编译型语言
正是基于不同厂商有不同的指令集,催生了C语言,建立了一个更为通用的编程范式。
C语言从源代码到执行,要使用编译器来编译(compile)、汇编(assembly)并连接(link)所依赖的库,形成机器可执行文件。执行某个二进制文件时,操作系统会为程序分配内存和CPU资源。“编译”和“汇编”,相当于将C语言翻译成底层语言。另外,代码中使用了库函数printf,当我们使用别人写好的函数时,需要将这些前人写好的库函数连接到我们的可执行文件中,否则会调用函数失败的错误。我们将这种需要编译的语言称为编译型语言。编译型语言有C/C++、Fortran等。
编译、汇编、连接缺一不可,特别是连接的存在,导致不同文件编译的顺序要求严格,继发调试困难。又由于不同操作系统下,因为架构的不同,调用各种接口的代码也会不同,继而编译过程也不相同,应用软件也就有了不同操作系统下的不同版本。
2. 解释型语言
因为IT圈的一句名言就是:计算机科学任何领域的问题都可以通过增加一个中间层来解决。一些大牛忍受不了C语言这样编写和调试太慢,系统平台之间无法共享移植的问题,于是开始自立门户,创建了新的编程语言,最有名的要数Java和Python,这类语言不需要每次都编译,因此被称为解释型语言。matlab、R、JavaScript也是解释语言。
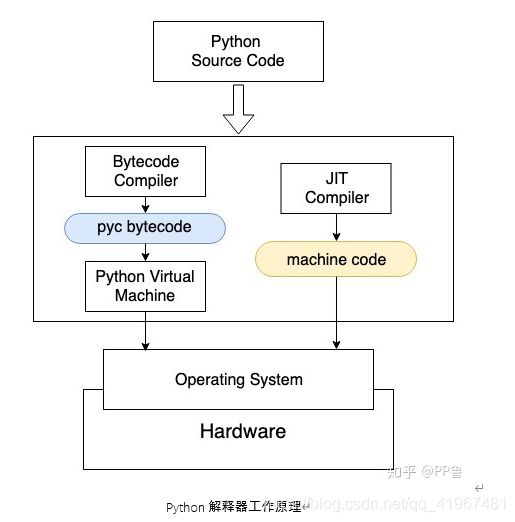
解释型语言一般是使用C语言等偏底层的语言做一个虚拟机或者解释器,编程人员需要先在自己的计算机上安装这个解释器,接下来就只用关心自己的源代码,其他的事情都交给解释器去做。如果把编译型语言的编译过程比作将源代码“翻译”成机器语言的话,那么解释性语言就是同声传译。编译型语言是一篇提前就“翻译”好的稿子,拿过来就能被读出来,这样肯定更快;解释型语言要等翻译边“听”边“翻译”,速度当然慢很多。
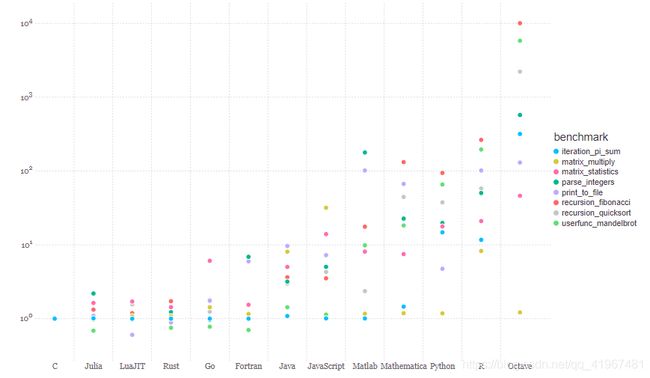
不同编程语言的性能测试
3. 如何将两种类型语言结合
总结以上介绍的两种语言:解译型语言运行效率高,而解释型语言具有可移植性好、使用方便的特点。所以可以将解译型语言向解释型语言发展的过程解读为一个为了易用性和可移植性而牺牲了效率的过程。
但是如果我比较贪心,又想要高效率,也不想损失可移植性和易用性呢?当前的技术为我们提供了两个方案:
-
使用编译型语言写的模块:
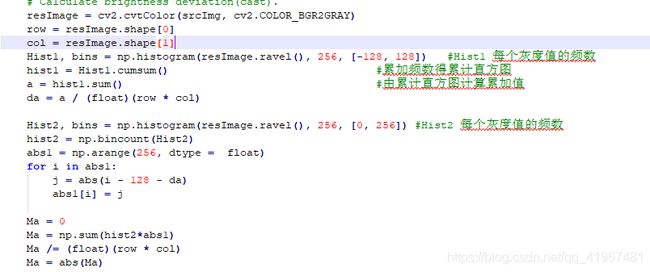
以Python为例,为了保证性能,大部分高性能科学计算库其实都是使用编译型语言编写的。比如numpy,用户安装numpy的包时,其实就是下载了C/C++和Fortran源代码,并在本地编译成了可执行的文件。简单举个例子:在图像处理中,用Python直接写裸的大循环效率十分低下,可以全改成numpy提供的方法来提高循环的效率。

修改后的代码,将循环改用了numpy提供的方法,效率有了很大提高。
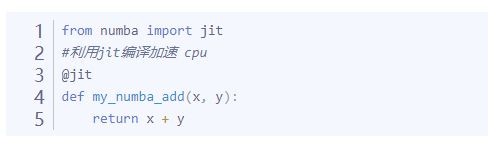
2. JIT(Just-In-Time) 即时编译技术
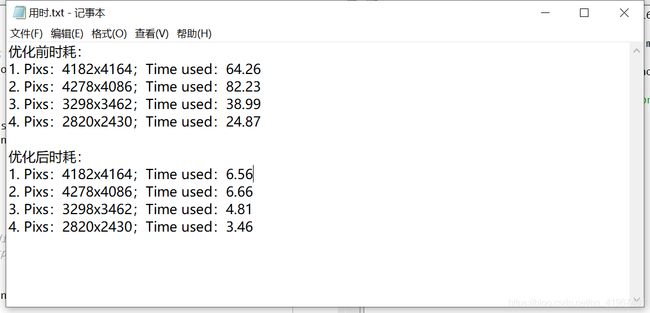
JIT把需要加速的代码编译成了机器语言,不再需要“同声传译”拖累自己了。比如在Python上调用numba库进行过JIT测试,同样的代码会有8倍以上的速度提升。而numba不仅可以编译用于CPU执行的代码,达到和C相比拟的速度,同时还可以调用GPU库(如NVIDIA的CUDA和AMD的ROCs等)来实现GPU加速,这些都可以简单的利用Python中的装饰器来实现。(https://zhuanlan.zhihu.com/p/72789048)
使用numb加速:

三、 GPU知识简单介绍
GPU全名为Graphics Processing Unit,又称视觉处理器、图形显示卡。GPU负责渲染出2D、3D、VR效果,主要专注于计算机图形图像领域。后来人们发现,GPU非常适合并行计算,可以加速现代科学计算,GPU也因此不再局限于游戏和视频领域。
1. CPU和GPU
我们之前介绍过CPU的构成和工作原理,现代CPU处理数据的速度在纳秒级别,但关键是无论是CPU还是GPU,在进行计算时,都需要用核心(Core)来做算术逻辑运算。核心中有ALU(逻辑运算单元)和寄存器等电路。在进行计算时,一个核心只能顺序执行某项任务。为了同时并行地处理更多任务,芯片公司开发出了多核架构,只要相互之间没有依赖,每个核心做自己的事情,多核之间互不干扰,就可以达到并行计算的效果,极大缩短计算时间。
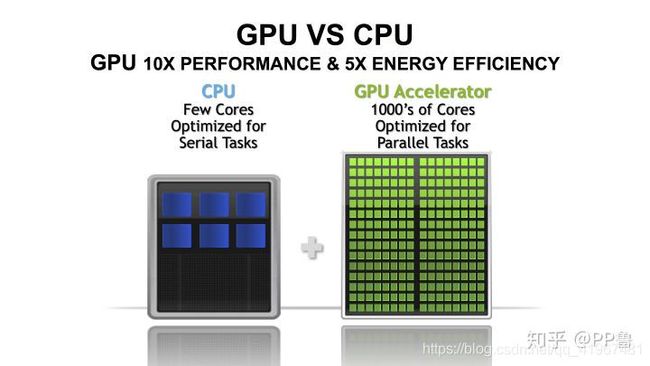
CPU VS GPU
个人桌面电脑CPU只有2到8个CPU核心,数据中心的服务器上也只有20到40个左右CPU核心,GPU却有上千个核心。与CPU的核心不同,GPU的核心只能专注于某些特定的任务,但是在执行比较简单而重复的任务时,GPU的超多核心就表现出了巨大的优势。
GPU核心在做计算时,只能直接从显存中读写数据,程序员需要在代码中指明哪些数据需要从内存和显存之间相互拷贝。这些数据传输都是在总线上,因此总线的传输速度和带宽成了部分计算任务的瓶颈。也因为这个瓶颈,很多计算任务并不适合放在GPU上。比如在深度学习中,因为输入是大规模稀疏特征,GPU加速获得的收益小于数据互相拷贝的时间损失。

CPU和GPU架构
如果只关注CPU和GPU,那么计算结构将如下图所示。CPU主要从主存(Main Memory)中读写数据,并通过总线(Bus)与GPU交互。GPU除了有超多计算核心外,也有自己独立的存储,被称之为显存。一台服务器上可以安装多块GPU卡,但GPU卡的发热量极大,普通的空调系统难以给大量GPU卡降温,所以大型数据中心通常使用水冷散热,并且选址在温度较低的地方。
GPU核心在做计算时,只能直接从显存中读写数据,程序员需要在代码中指明哪些数据需要从内存和显存之间相互拷贝。这些数据传输都是在总线上,因此总线的传输速度和带宽成了部分计算任务的瓶颈。也因为这个瓶颈,很多计算任务并不适合放在GPU上。比如在使用深度学习时,因为输入是大规模稀疏特征,GPU加速获得的收益小于数据互相拷贝的时间损失。
由于CPU和GPU是分开的,在英伟达的设计理念里,CPU和主存被称为Host,GPU被称为Device。Host和Device概念会贯穿整个英伟达GPU编程。
以上结构也被称为异构计算:使用CPU+GPU组合来加速计算。世界上顶尖的数据中心和超级计算机均采用了异构计算架构。例如超越天河2号成为世界第一的超级计算机Summit使用了9216个IBM POWER9 CPU和27648个英伟达Tesla GPU。

2. GPU架构
英伟达不同时代产品的芯片设计不同,每代产品背后有一个架构代号,架构均以著名的物理学家为名,以向先贤致敬。当前比较火热的架构有:
- Turing图灵 :消费显卡 GeoForce系列
- Volta 伏特 :专业显卡 Telsa V系列
- Pascal 帕斯卡 :专业显卡 Telsa P系列
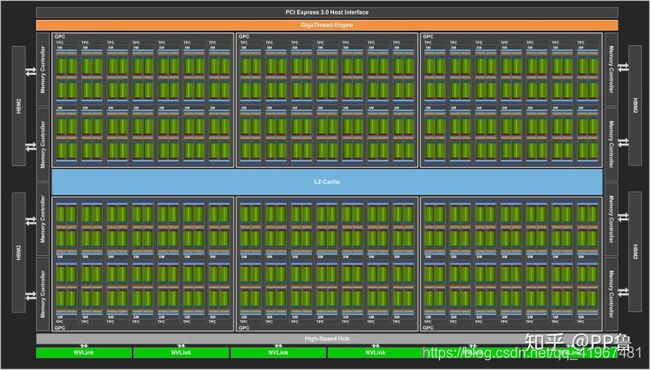
Telsa V100 设计图
在英伟达的设计里,多个小核心组成一个Streaming Multiprocessor(SM),一张GPU卡有多个SM。从“multiprocessor”这个名字上也可以看出SM包含了多个处理器。实际上,英伟达主要以SM为运算和调度的基本单元。上图为当前计算力最强的显卡Tesla V100,密密麻麻的绿色小格子就是GPU小核心,多个小核心一起组成了一个SM。

Telsa V100单个SM设计图
单个SM的结构如图所示。可以看到一个SM中包含了:
- 针对不同计算的小核心(绿色小格子),包括优化深度学习的TENSOR CORE,32个64位浮点核心(FP64),64个整型核心(INT),64个32位浮点核心(FP32)。
- 计算核心直接从寄存器(Register)中读写数据。
- 调度和分发器(Scheduler和Dispatch Unit)。
- L0和L1级缓存。
3. 软件生态
英伟达能够在人工智能时代成功,除了他们在长期深耕显卡芯片领域,更重要的是他们率先提供了可编程的软件架构。2007年,英伟达发布了CUDA编程模型,软件开发人员从此可以使用CUDA在英伟达的GPU上进行并行编程。在此之前,GPU编程并不友好。

NIVIDA软件栈
继CUDA之后,英伟达不断丰富其软件技术栈,提供了科学计算所必须的cuBLAS线性代数库,cuFFT快速傅里叶变换库等,当深度学习大潮到来时,英伟达提供了cuDNN深度神经网络加速库,目前常用的TensorFlow、PyTorch深度学习框架的底层大多基于cuDNN库。
GPU编程可以直接使用CUDA的C/C++版本进行编程,也可以使用其他语言包装好的库,比如Python可使用Numba库调用CUDA。CUDA的编程思想在不同语言上都很相似。
CUDA及其软件栈的优势是方便易用,缺点也显而易见:
(1)软件环境复杂,库以及版本很多,顶层应用又严重依赖底层工具库,入门者很难快速配置好一整套环境;多环境配置困难(Win10版本CUDA配置可以参考博客:https://blog.csdn.net/qq_41967481/article/details/108431516)。
(2)用户只能使用英伟达的显卡,成本高,个人用户几乎负担不起。
因此,如果没有专业的运维人员维护GPU机器,最好还是在公有云上按需购买GPU虚拟机。入门者可以考虑云厂商的Telsa P4虚拟机,大约10+元/小时,云厂商会配置好CUDA及工具库。
-
参考
大量图片和内容都是参考知乎大牛PP鲁老师的博客,感谢能从他的博客中学习到宝贵的知识。附个传送门:https://zhuanlan.zhihu.com/c_1127896820252299264。
其他参考:
https://blog.csdn.net/The_Time_Runner/article/details/103364257?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
https://blog.csdn.net/u014636245/article/details/84404646?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.add_param_isCf&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.add_param_isCf